
A Preset Skewed Static Logic Family
Albert Ma & Krste Asanovic
Introduction
Signal integrity and device variance have become dominant design and verification issues in sub-100nm technologies. Noise, relative to power supply voltage, has increased while relative noise immunity has decreased. Designers need logic styles that best balance the requirements of performance, power, noise immunity, and design effort. We present Preset Skewed Static Logic (PSSL), a new logic style and pipelining scheme that combines the performance of domino logic with the robustness of static CMOS logic. PSSL works by presetting nodes at latch boundaries to known logic values, thus allowing certain paths to begin evaluation a phase early.
Design
Fig. 1a shows an example PSSL pipeline using a standard two-phase pipeline with static latches. Clocked NAND gates are placed after each latch to preset nodes B/E high while the latches are transparent. Fig. 2 shows the timing diagram. t1 and t3 represent the delays of the preset paths, those paths activated by rising inputs. t2 and t4 represent the delays of the evaluate paths, those paths activated by falling inputs. The corresponding timing constraints, ignoring clock skew or jitter, are given by
| t1 < tΦl + tΦh | t3 < tΦl + tΦh | |
| t2 < tΦl | t4 < tΦh |
The preset paths overlap in time and can take a whole clock cycle to complete. Logic can be skewed to favor the evaluate paths, resulting in better energy and delay than static CMOS. The scheme can be extended to N-phases, but with rapidly diminishing returns past N=2.
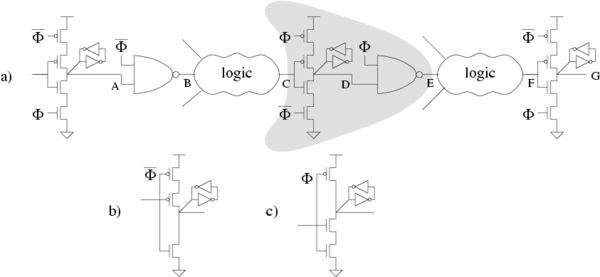 |
Fig. 1 PSSL pipeline
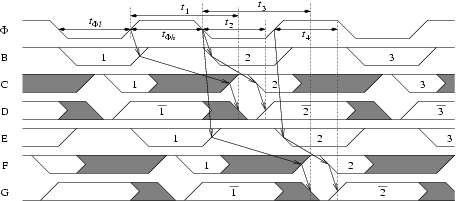 |
Fig. 2 PSSL pipeline timing
If the logic between nodes B and C in Fig. 1a is strictly inverting/non-inverting then the latching circuitry in grey can be simplified as in Fig. 1b/c (ignoring output inversion). The removal of the static latches increases speed and enables time borrowing[1], which loosens the evaluate path timing constraint to t2+t4< tΦl+tΦh and reduces sensitivity to clock jitter. Even if the logic is not completely monotonic, the simplified latching can still be used. However, the designer must guarantee tΦh < t1 and/or tΦl < t3 so that the preset paths are sufficiently slow as to not interfere with the evaluation of the previous cycle; this is a form of wave-pipelining. In contrast, it is impossible to implement non-monotonic logic in single-rail domino directly because the corresponding timing constraints would be impossible to meet.
A design in PSSL is generally smaller than the same design in static CMOS logic at the same performance because transistors in the preset path can be downsized. The only area overhead is in the clocked NAND gates, which can often be simplified away.
Domino logic exhibits a tradeoff between performance, power, and noise immunity (including soft errors) that gets worse with scaling[2]. This is further exacerbated by variance, particularly in transistor leakage. In addition, footless domino styles require many finely spaced precisely timed and shaped clocks. Clock uncertainty requires extra delay margin or can cause increased power dissipation from short-circuit paths. In contrast, PSSL is robust because it uses static CMOS logic for the bulk of the circuitry. Variance has a much smaller impact on energy, delay, or noise margin in PSSL, though some care must be taken when wave-pipelining techniques are being used.
A static/dynamic hybrid called Skewed CMOS logic was proposed in [3]. Our work shares the idea of using skewed static gates for improved performance and robustness, but uses different timing principles. In Skewed CMOS, speedup is attained by having multiple sections of dependent logic in the same stage precharging simultaneously. Precharge must complete in one phase. In PSSL, speedup is attained by overlapping the preset of logic in adjacent stages. Preset completes in one clock cycle. Skewed CMOS requires a greater clock load, a factor of 2 for performance equal to PSSL. On the other hand, Skewed CMOS can potentially achieve greater performance than 2-phase PSSL. However, the same performance can be achieved at lower energy either by using a hybrid Skewed CMOS/PSSL design or by using a multi-phase PSSL design.
Evaluation
We first compare PSSL against domino logic (both footless and footed) by implementing a 4-bit shift register using dual-phase clocking. For delay elements we used chains of alternating 3-input NAND and NOR gates. Many variants of the three designs were simulated in HSPICE using the BPTM[4] 70nm process at 0.7V and with 5fF of capacitive load at each node. The energy, delay, and noise- margin were measured at optimal design points. We define noise-margin as the input voltage at which DC large-signal unity gain is observed, equivalent to the DC noise required to flip the last node on an infinitely long chain of gates.
The energy-delay curves (see Fig. 3) at 0.20V and 0.25V noise-margin are shown for the domino designs. The curve at 0.30V noise-margin is shown for the PSSL design. Comparing the 0.20V domino and 0.30V PSSL curves, we see that even with a 0.10V difference in noise-margin (about 15% of Vdd), PSSL is competitive with domino logic in terms of energy-delay and at the slow end of the curve PSSL is clearly superior. Comparing the 0.20V and 0.25V domino curves, we see that increasing the noise margin of domino comes at an energy-delay penalty of roughly 15-20%.
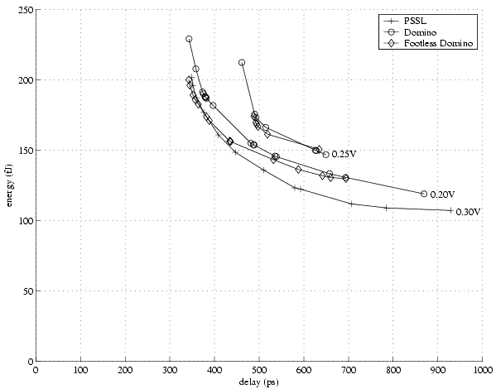 |
Fig. 3 Shift register energy-delay curves at different fixed noise margins
Adders are an important component on the critical paths of microprocessors and DSP's. We implemented a 32-bit accumulator shown in Fig. 4 to serve as a realistic test case for PSSL. Additional inverter stages were added to model mux and drive stages that would be present in a processor datapath. For the adder we chose a hybrid carry-lookahead/carry-select architecture. We implemented the accumulator in static CMOS, PSSL, and footed domino. The PSSL and domino implementations require some care because the logic is not fully monotonic. For the domino implementation, we chose to keep the design single-rail by employing complementary signal generators (CSGs) before the final muxes. The CSGs add extra delay but allowed a power reduction of roughly 50%. In the PSSL implementation, we did not include the CSGs in the critical carry-generation paths, shaving some delay. Those paths thus have minimum delay constraints, but the constraints are easily met.
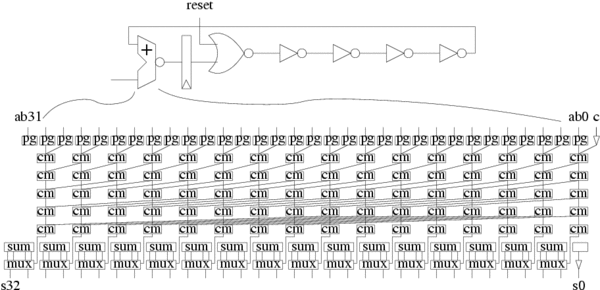 |
Fig. 4 Accumulator design
We simulated the designs in the TSMC 0.18mm process at 1.8V and 1.2V over 9 cycles with the same set of random input data. The netlist was annotated to include estimated wire and source/drain parasitics. The designs were optimized around different energy-delay points without noise-margin constraints. At each voltage, PSSL is superior to static CMOS except at the lowest energy points and is superior to domino except at the lowest delay points (Fig. 5). At the sweet spot for PSSL, roughly 500ps and 70pJ, it exhibits 20% less energy than domino and 33% less delay than static CMOS. If we combine voltage scaling and transistor sizing, we can conclude that PSSL is superior to both domino and static CMOS at every design point except where ultra-high performance or ultra-low power is required. In addition, the PSSL design should have higher noise margins.
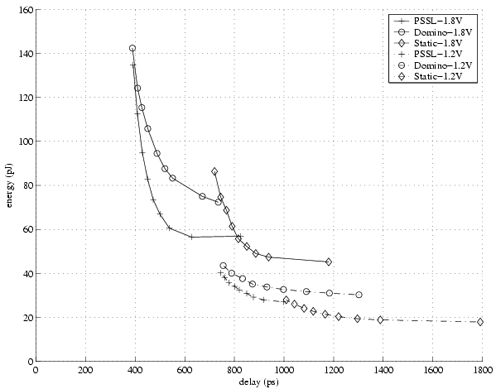 |
Fig. 5 Accumulator energy vs. delay at 1.8V and 1.2V
Research Support
This work is partially supported by NSF CAREER Award CCR-0093354, the Cambridge-MIT Institute, and a donation from the Intel corporation.
References
[1] D. Harris. Skew-Tolerant Circuit Design. Morgan Kaufmann Publishers, 2001.
[2] M. Anders, R. Krishnamurthy, R. Spotten, and K. Soumyanath. Robustness of sub-70nm dynamic circuits: Analytical techniques and scaling trends. Symp. VLSI Circuits, vol. 3, pp. 23-24, June 2001.
[3] A. Solomatnikov, D. Somasekhar, N. Sirisantana, and K. Roy. Skewed CMOS: Noise-tolerant high-performance low-power static circuit family. IEEE Trans. VLSI Syst., 10(4):469-476, August 2002.
[4] Y. Cao, T. Sato, M. Orshansky, D. Sylvester, and C. Hu. New paradigm of predictive MOSFET and interconnect modeling for early circuit design. IEEE CICC, pp 201-204, June 2000.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |