
HiT: Mutlimedia Summarization System for Personalized Baseball Highlights
Alice Oh, Howard Shrobe & Robert Laddaga
Problem Statement
Two people can have very different perspectives of the same event. This is readily apparent in the sports domain, where, depending on which hat you are wearing, you view the games as a "win" or a "loss." This divergence of perspective is reflected in the media, in the form of newspaper articles and sports news and highlights. However, besides a limited amount of individual play clips and highlights on the Internet, the audience does not have control over the media content. If one is more interested in certain types of plays or specific players, he cannot request that ESPN play highlights containing those plays. If he missed the game and has forty-five minutes to watch a condensed version, he cannot ask MLB.com to make a 45-minute version of the game containing certain plays he does not want to miss. MLB.com offers flexibility in playing back individual plays, such as the strikeout in the seventh inning, but it does not give the context in which the event happened, so the user would miss that it was the third out of the game following two walks, leaving the runners stranded in a game that was decided by one point.
As the media industry moves toward more on-demand programming, providing viewers choice over what and when to watch, there is a greater need for personalized content created by intelligent analyses using artificial intelligence techniques. We are developing a system that uses domain modeling and user modeling to automatically generated personalized baseball highlights.
Domain Modeling
Research in analyzing sports video has flourished because of the widespread and deep interest in sports, but there is another facet of the sports domain that has not been explored much, and that is the highly structured nature of the games. In our project, we chose to model baseball, but other sports such as American football or basketball also have varying degrees of explicit structure that is absent in many other genres. By exploiting the structure, a computational system can manipulate the video in a much more flexible yet intelligent way.
In [1], we describe our hierarchical model of baseball. We designed the model to capture important semantic details of a baseball game. This would allow users to personalize the highlights using semantic descriptions. The model is built automatically from external data. This is because for every baseball game in Major League Baseball (http://www.mlb.com), there is a wealth of information on the Internet including a detailed pitch-by-pitch log of the game that gets updated near real-time as the game progresses. This log is an excellent source for extracting a model of a game because it is readily accessible, simple and regular in structure and language, and contains an accurate and objective account of the game. We implemented a simple regular-expression matching algorithm to analyze the log. Although a more flexible natural language parser would be a better choice, the regular-expression matching works quite well because of the regularity and simplicity of the language in the log.
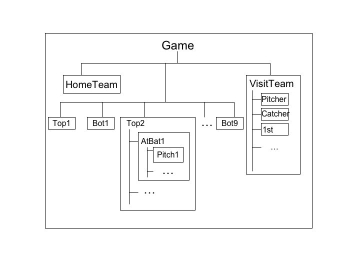
Using the model, we compute semantic features, such as number of outs, RBI, number of runners, and then try to identify the individual plays that are significant. We have experimented with two method: the first method is a simple rule set, and the second method is a supervised learning algorithm. We used human-generated highlights on TV and in newspaper articles as training and test data. We achieved 88.0% accuracy using the learning algorithm, which shows our domain modeling does well in identifying important plays.
User Modeling
One of the next steps in our research is to explore user modeling techniques. The combination of user modeling and domain modeling would enable personalization of highlights. [2] uses user modeling to generate personalized news summaries, and we plan on using similar techniques for our domain. In addition, we are analyzing newspaper articles and television broadcast to understand how user preferences may translate into surface form generation. That is, once we know a user prefers certain players or certain types of plays, how would we generated the multimedia story that includes those plays. We have gathered hundreds of documents, both text and multimedia, and are experimenting with learning algorithms to analyze and collect the patterns.
Future Work
This work is very much in progress. We have completed the domain modeling part, and are working on analyzing data and building user models. There are also other issues such as user interface and multimedia generation. We plan on tacking these subproblems one by one and completing the system in the near future.
References
[1] Alice Oh, Howard Shrobe, and Robert Laddaga. Modeling Baseball Using External Data for Automatic Highlight Generation. Submitted for Review
[2] Mark Maybury, Warren Greiff, Stanley Boykin, Jay Ponte, Chad Mchenry, and Lisa Ferro. Personalcasting: Tailored Broadcast News. User Modeling and User-Adapted Interaction, vol. 14, no. 1, pp. 5-36.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |