
Socially Situated Learning for A Humanoid Robotic Creature
Lijin Aryananda
Introduction
The primary objective of this project is to explore socially situated learning, i.e. acquisition of new behavior from others in a social context, in a humanoid robot. Our approach is heavily inspired by the role of experience in the world and social interaction on the infant's learning process. Vygotsky's theory asserts that human intelligence emerges as a result of biological factors that participate in a physical and social environment through a developmental process [1]. Given these biases, we propose that the robot must be able to operate in human spaces and time scales, continuously running everyday in different public locations, and interacting with human passersby. The idea is to move toward a robotic creature that lives around people on a regular basis and incrementally learns from its experience instead of a research tool that interfaces only with its programmers and performs a specific task within short-term testing periods. Much like human infants, the robot will be directly exposed to multisensory experiences in the world. In raw form, such data can be overwhelmingly complex, but this information will be filtered by human mentors. Our goal is to have the robot incrementally learn from its daily experience in this rich but challenging setting.
In contrast to the typical robot learning setup where the robot executes learning algorithms to acquire a specific task, we aim for more general and open-ended learning scenarios which will be dynamically determined by the corresponding situational and social contexts. More specifically, we plan to develop the robot to ultimately do the following:
- live in various public spaces, run continuously everyday, and interact with spontaneous passersby;
- start with a set of preprogrammed innate behaviors and drives, such as preference for faces, etc;
- incrementally learn to recognize individuals after some significant encounters;
- acquire lexicon of socially relevant phoneme sequences in an unsupervised manner;
- discover that some initial random behaviors lead to positive feedback and learn to automatically generate these actions whenever appropriate.
Motivation
We postulate that a robotic creature that is capable of long-term continuous operation and embedded in our social environment may generate some interesting opportunities. First, social interaction can serve as a powerful interface for teaching skills to a robot [2]. Second, the robot's prolonged run time gives us access to an enormous amount of concurrent natural data from multiple modalities, as well as longer-term social interaction dynamics. Supposing that a pet dog were awake for only several hours per week, imagine the degree to which its social interactions would be impoverished. Lastly, we can take advantage of various situational and sociocultural contexts, which play an important role in our learning process. Vygotsky provides the example of finger pointing, which initially begins as a meaningless grasping motion and becomes a meaningful movement as people react to the gesture [1].
Approach
To this end, we have designed and constructed MERTZ , an active-vision head robot with thirteen degrees of freedom (see Figure 1). In [3], we report on design steps toward a modular control architecture and issues involving reliable continuous operation. We have equipped the robot with simple visual and verbal behaviors. The robot orients to and tracks salient visual targets, such as human faces and bright-colored toys, and tries to encourage verbal interaction by mimicking phoneme sequences extracted from speech input. In [4], we describe the robot's perceptual and behavior systems, as well as address the challenging objective of generating one of the prerequisites for the robot's learning process, i.e. social and scaffolding feedback from naive passersby. We conducted an experiment where the robot ran for approximately 7 hours per day for 5 days at different public spaces to assess the following issues: Will people actually interact with the robot? Will they interact closely enough for the robot to acquire a set of face images? Are people going to speak to the robot? Will they say some one-word utterances to avoid the difficult word segmentation task? Will there be enough word repeatability for the robot to acquire a lexicon of socially relevant words?

Fig 1: Multiple views of MERTZ, an active-vision
humanoid head robot with 13 degrees of freedom (DOF).
The robot is mounted on a portable wheeled platform that can be turned
on anywhere by plugging into a power outlet.
Experimental Results
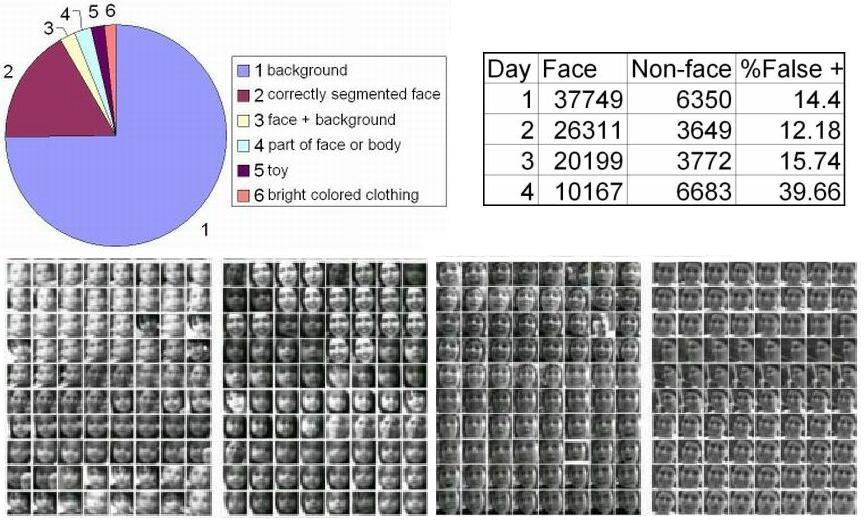
Fig 2: Upper Left: What the robot tracked during
a sequence of 14186 frames.
Upper Right: The false positive error rate of the face detector over
the course of 4 days.
Bottom: A sample set of the 943,656 correctly detected faces.
During the experiment, we recorded the robot's visual input and the tracker's output every second. We labelled a sequence of 14186 frames collected during a close to four hour period on day 2. As shown in the figure above, approximately 16.9\% of the sequence, the robot tracked correctly segmented faces. For a small part of the sequence the robot tracked faces that either included too much background or partially cropped and tracked bright colored toys and clothing. We also collected every frame of segmented face images that were detected by the frontal face detector throughout the experiment, which amount to a total of 114,880 images from at least 600 individuals. Figure 2 shows the breakdown of the face detector's performance during each day, excluding one day due to file loss. These results suggest that the robot is able to acquire a significant set of face images because people do interact with the robot closely enough and for long enough durations.
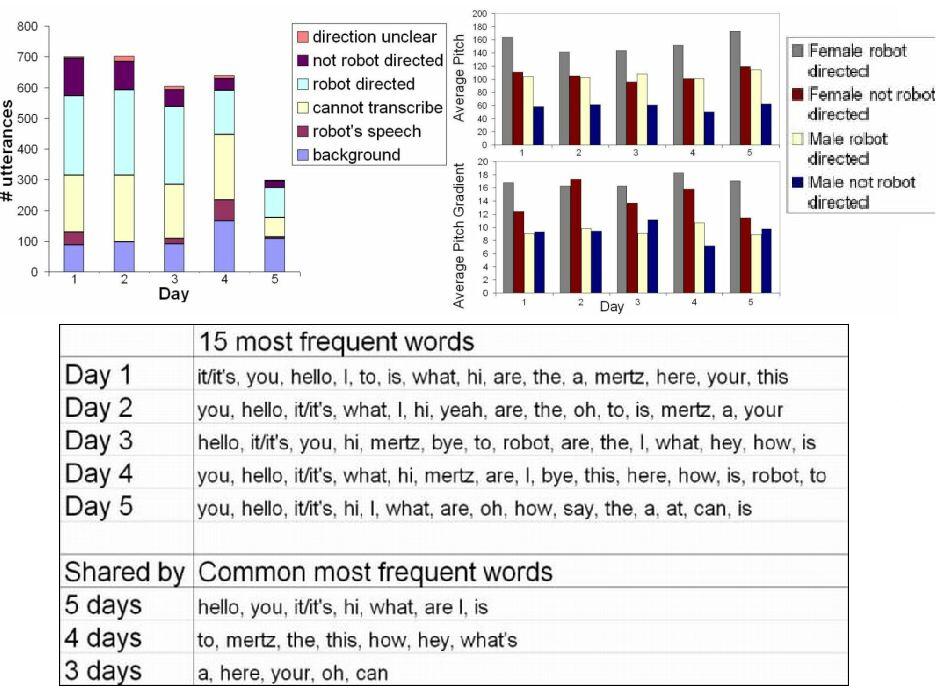
Fig 3: Upper Left: The characteristic of speech
input received by the robot on each day of the experiment.
Upper Right: Average pitch and pitch gradient values extracted from robot
directed and non-robot directed speech.
Bottom: The top 15 words on each experiment day and the common set of
most frequently said words across multiple days.
The robot received over 1000 audio samples per day. We transcribed 3027 utterances taken from a continuous sequence of speech input spanning a number of hours per day. As shown in the figure above, approximately 37% of the total utterances are intelligible robot directed speech. The rest are made up of background noise, robot's own speech, human speech that is unintelligible (cropped, foreign language, muddled, etc), and human speech directed not at the robot. From this set of intelligible human speech, one-word utterances make up 38% of the set and 38.64% of robot directed ones. Approximately 83.21% of all intelligible human speech and 87.77% of robot directed speech contain less than 5 words. Moreover, calculation of the pitch values of input speech indicates that both female and male speakers tend to speak with higher pitch average to the robot versus other people. The average pitch gradient data suggests that female speakers tend to speak with more modulated pitch contour when speaking to the robot. Lastly, we are also interested in assessing whether a set of words tend to be repeated by a large number of people, such that the robot may acquire a set of lexicon of relevant words. Analysis of speech data shows that a set of words tend to be repeated during each day of the experiment (see figure above).
These results seem to suggest to people do in fact interact verbally with the robot and some speak to it like they would to a young child. The frequency of one-word utterances seems to be high enough to provide the robot with a starting point for unsupervised lexical acquisition. Lastly, a set of common words tend to be repeated throughout the experiment despite the large number of speakers and minimal constraints on the human-robot interaction.
References
[1] L. Vygotsky. Mind in society. Cambridge, MA: Harvard Univ Press, 1978.
[2] C. Breazeal. Sociable machines: Expressive social exchange between humans and robots. Sc.D. Dissertation, Department of EECS, MIT, 2000.
[3] L. Aryananda. Mertz: A quest for a robust and scalable active vision humanoid head robot. IEEE-RAS International Conference on Humanoid Robots, 2004.
[4] L. Aryananda. Out in the World: What Did the Robot Hear and See?. Submitted to Epigenetic Robotics, 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |