
Scene Understanding in the Street Scenes Database
Stan Bileschi, Lior Wolf & Tomaso Poggio
Goals
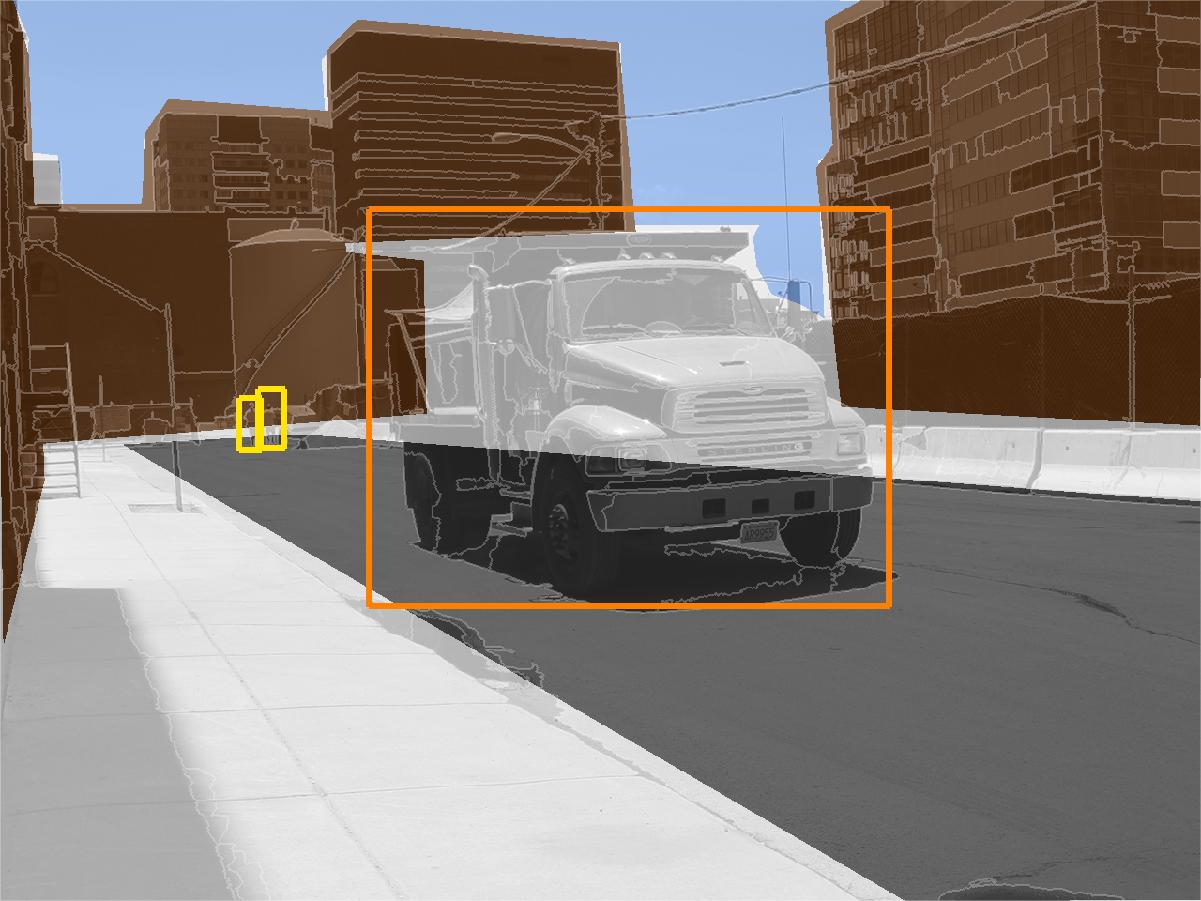
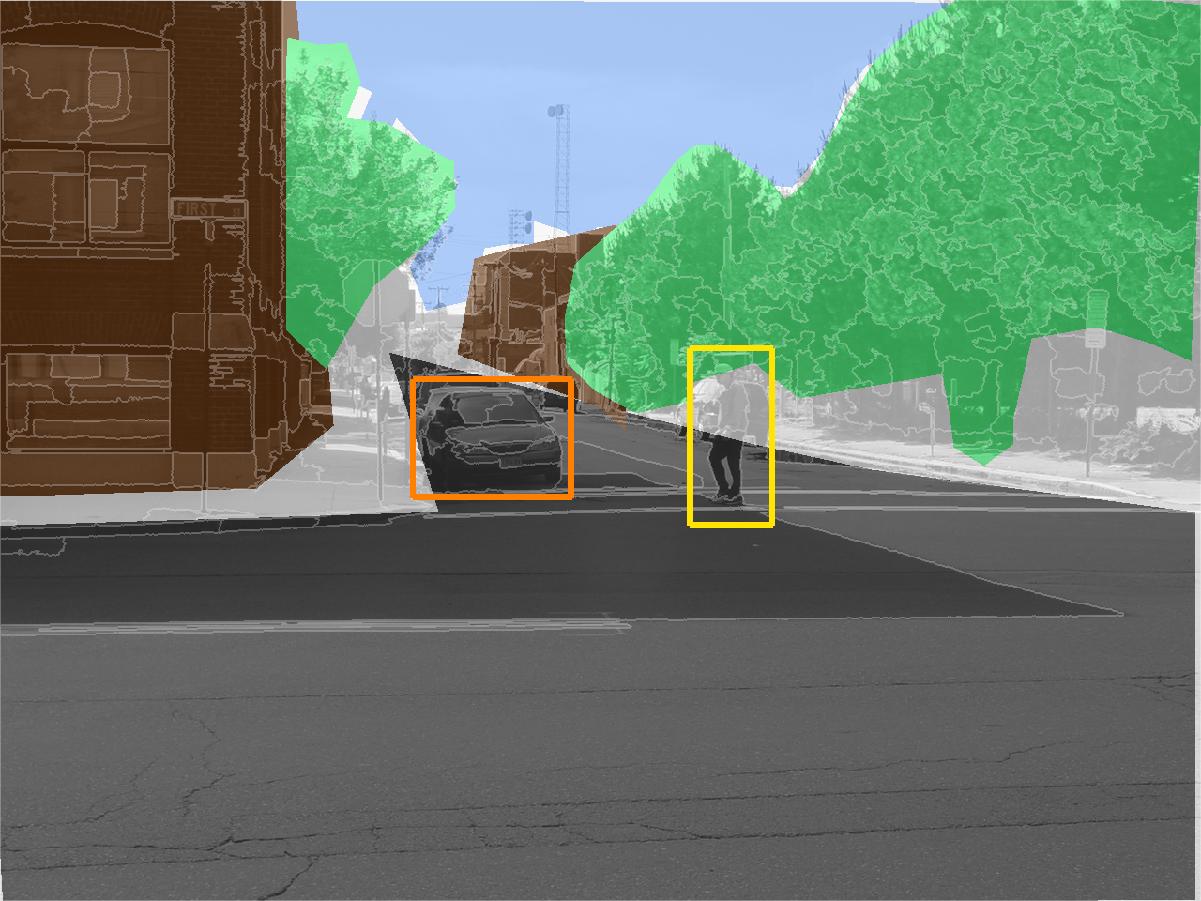
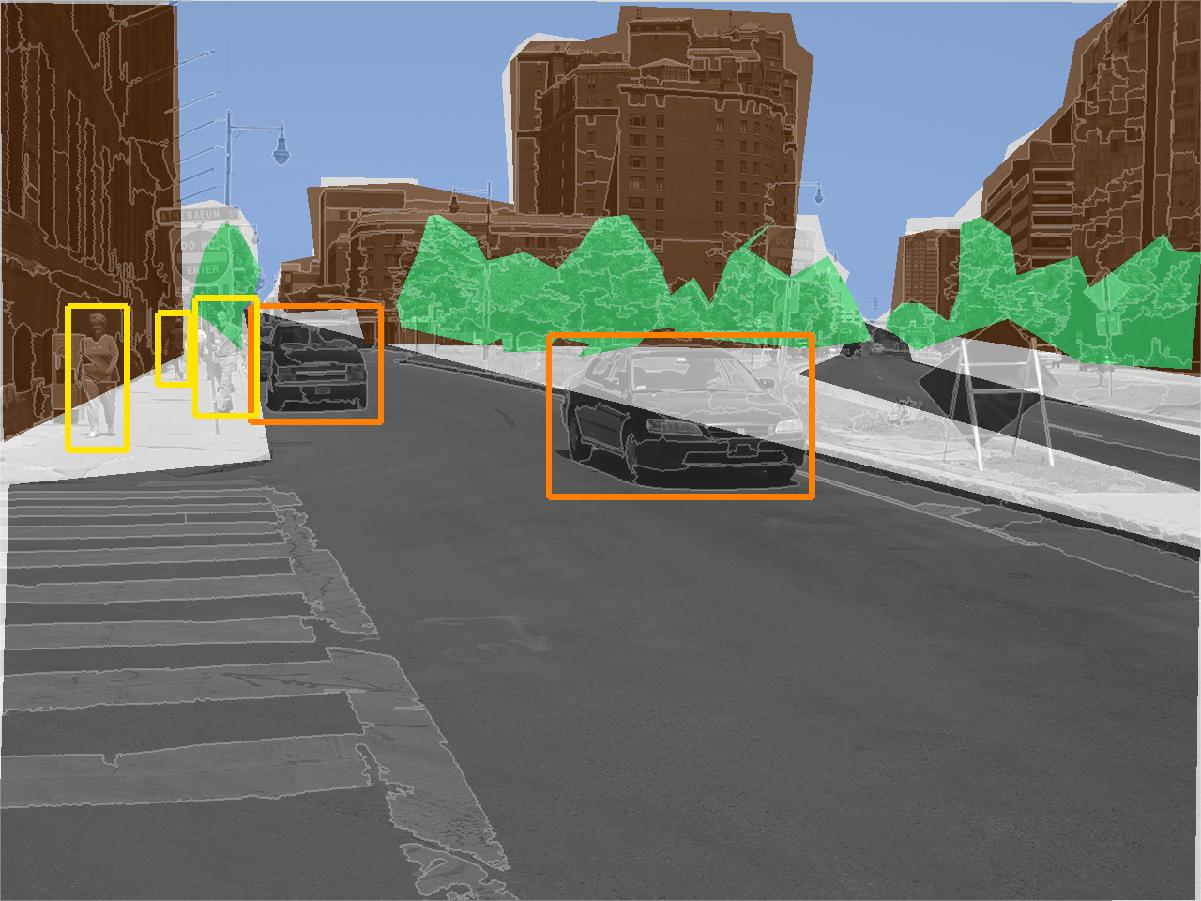
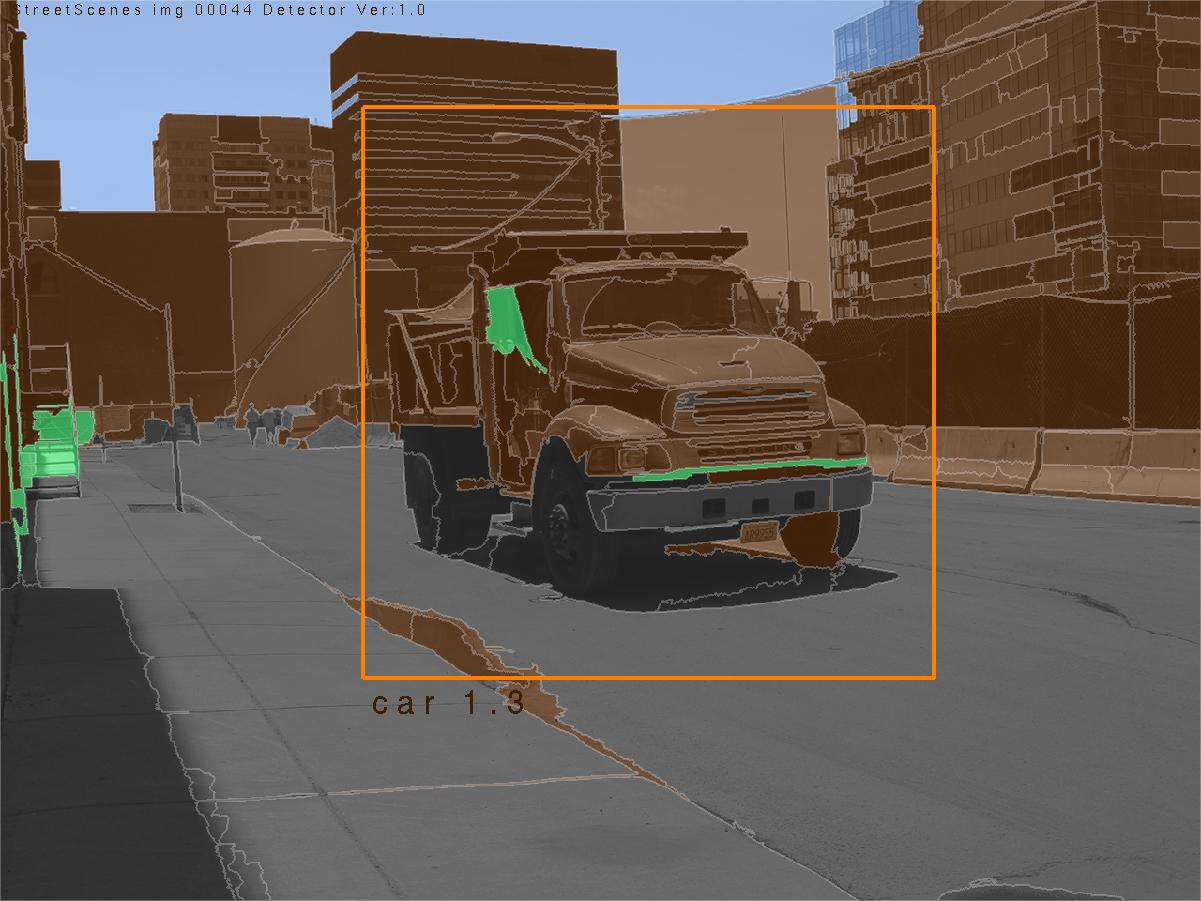
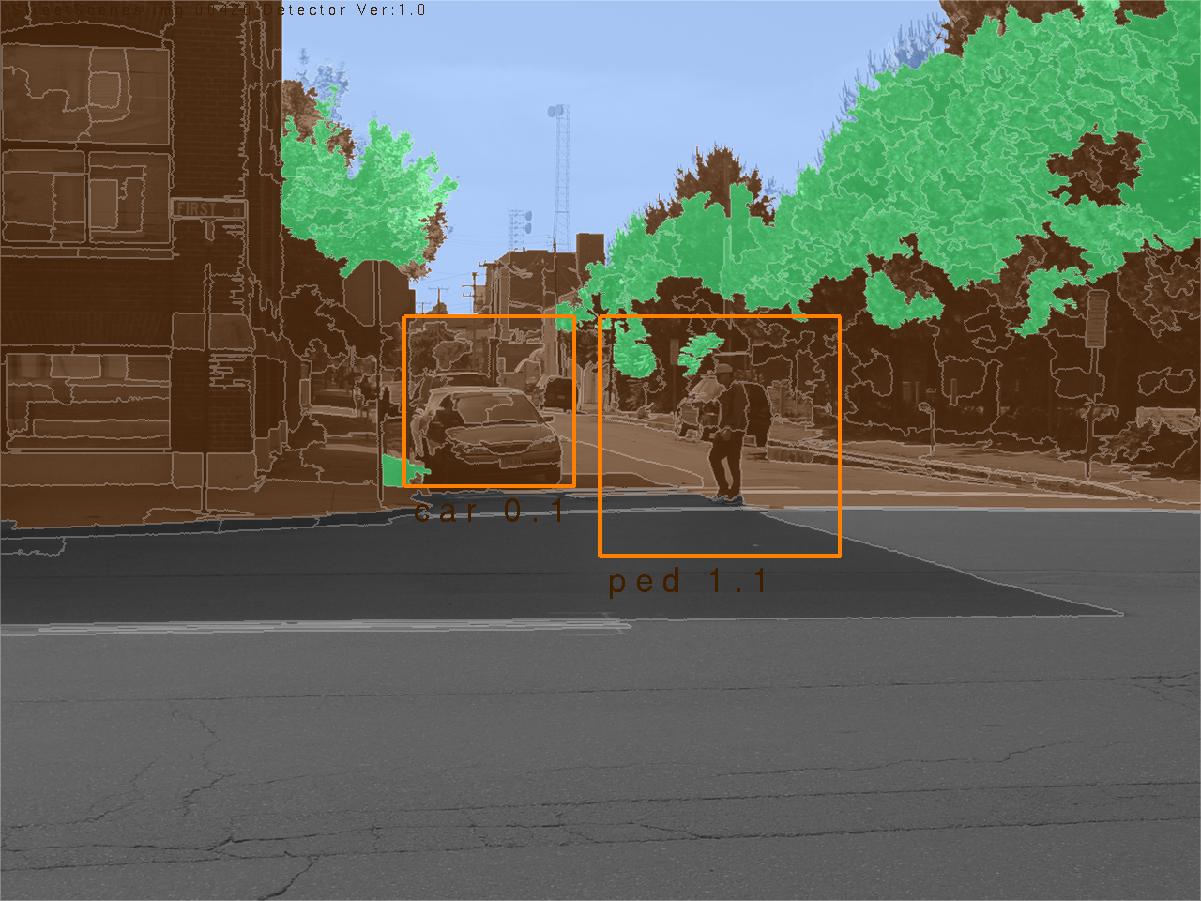
The StreetScenes project is a multi year endeavor by the Center for Biological and Computational Learning (CBCL) to promote and develop technologies for scene understanding. The first phase of this project was to acquire an appropriate training and testing platform, manifested in the StreetScenes database; a data base of over 3,000 high resolution images of outdoor scenes in Boston and the surrounding areas. These images have been hand labelled for around 10 object categories, including buildings, trees, cars, pedestrians, etc. Currently we are developing a unified approach to automatically learn reliable detectors for these objects. The goal is to develop an architecture capable of learning a function from images to image descriptions directly from the training data. Some examples of StreetScene images, their true labelling, and some empirical results are illustrated in Fig. 1. In the second row of Fig. 1 different fill colors indicated the hand labelling of large texture-based objects within the scene, with brown indicating buildings, green indicating trees, and blue and gray marking sky and road respectively. The shape-based objects are labelled with bounding rectangles, with orange rectangles surrounding cars, and yellow rectangles surrounding pedestrians. White regions have no label. This same annotation is used in the empirical results from the scene understanding system in the last row. In these images text, rather than color, indicates the difference between pedestrians and vehicles.

| 
| 
|
| 
| 
|
| 
| 
|
Prior Work
Our approach to scene understanding depends on the robust combination of a number of continuously developing technologies, including object detection [1,2], texture recognition [3,4], and contextual understanding [5,6]. Other key enabling technologies have been the development of the theory of statistical learning [7] and intuitions drawn from rigorous studies of the biological vision system [8].
One difference between our system and [5] is that our system operates in a discriminative feed-forward fashion and is capable of detecting large texture based objects.
Strategy
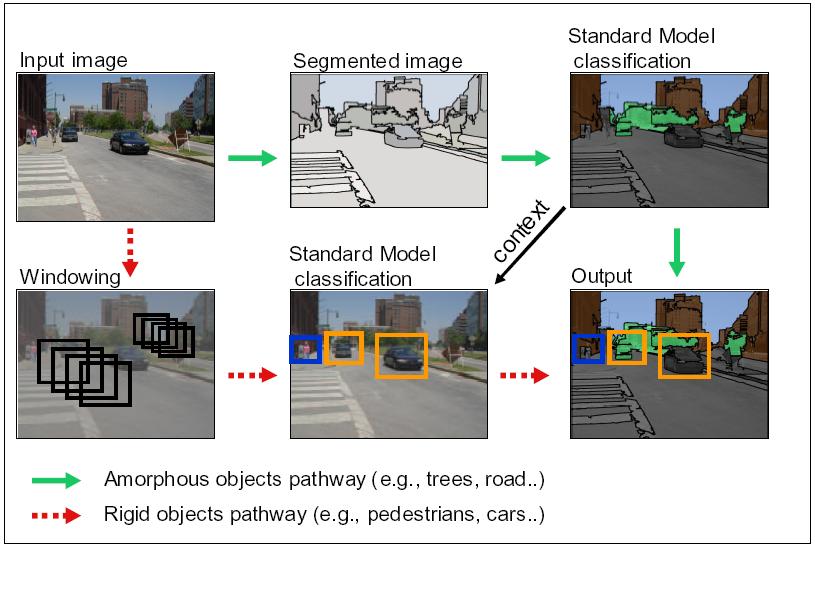
We divide the class of objects into two distinct sets, texture-based objects and shape-based objects, nearly analogous to Adelson's concept of things and stuff. These two classes of objects are handled using different learning strategies, even though both will rely upon the same features. Fig. 2 illustrates a data flow diagram for this architecture. The dashed arrows and solid arrows indicate the pathways for detection of the texture-based and shape-based objects, respectively. Additionally, the arrow labelled ``context,'' connecting the two pathways, symbolizes that the system is capable of using detections of the former class of objects to aid in the detections of the latter.
Standard Model Feature Set
The unifying principle of our scene understanding system is that all detectors rely upon visual features drawn from the same biologically inspired model of low-level visual processing, called the Standard Model Feature set (SMF) [8]. The SMF feature set consists of a multilayered approach to image processing combining linear filters, morphological dilation, and decimation. Previous detection systems have shown that the top level SMF features are good for the unsegmented object detection task. In the StreetScenes system we extend these experiments to the segmented object detection problem in cluttered natural scenes, and for object types not previously addressed. Encouraging results suggest that the SMF features outperform features engineered explicitly for these tasks.
Progress
As illustrated in Fig. 1, our current system is capable of robust detection for 7 widely different object categories in natural scenes, and performance on par with state of the art detectors designed explicitly for subsets of these objects. Specifically, the SMF based detectors for cars, pedestrians, and bicycles outperform global SVM models [1] and more recent part based methods [2]. The texture based detectors for buildings, trees, roads, and sky outperform the texton based detector of Malik [4], also designed for texture recognition. Finally, we have shown encouraging results involving contextual information flow between object types, such that the detection of a road may influence the detection of a car.
References
[1] Edgar Osuna. Support Vector Machines: Training and Applications. Ph.D. Thesis, EECS & OR, MIT, June 1998.
[2] Berned Heisele, Thomas Serre, Sayan Mukherjee and Tomasso. Poggio. Feature Reduction and Hierarchy of Classifiers for Fast Object Detection in Video Images. In: Proceedings of 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), IEEE Computer Society Press, Kauai, Hawaii, Vol. 2, 18-24, December 2001.
[3] Chad Carson, Serge Belongie, Hayit Greenspan and Jitendra Malik, Blobworld: Image Segmentation Using Expectation-Maximization and Its Application to Image Querying; in IEEE Trans. on Pattern Analysis and Machine Intelligence, 24(8), 1026-1038, August 2002.
[4] Jitendra Malik, Serge Belongie, Thomas Leung and Jianbo Shi, Contour and Texture Analysis for Image Segmentation. In International Journal of Computer Vision, 43(1), 7-27, June 2001.
[5] Antonio Torralba, Kevin P. Murphy and William T. Freeman (2004). Contextual Models for Object Detection using Boosted Random Fields. To appear in Adv. in Neural Information Processing Systems (NIPS)", (Also MIT AI Lab Memo AIM-2004-008, April 14).
[6]Peter Carbonetto, Nando de Freitas, and Kobus Barnard, A Statistical Model for General Contextual Object Recognition. In European Conference on Computer Vision, 2004.
[7] T. Hastie, R. Tibshirani, J. H. Friedman. The Elements of Statistical Learning. IPublisher: Springer; 1 edition (August 9, 2001), ISBN: 0387952845
[8] Thomas Serre, Lior Wolf and Tomaso Poggio. A New Biologically Motivated Framework for Robust Object Recognition. CBCL Paper #243/AI Memo #2004-026, Massachusetts Institute of Technology, Cambridge, MA, November, 2004.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |