
Parsing Spanish Using a Morphologically-Rich Statistical Model
Brooke Cowan & Michael Collins
Introduction
We have developed a statistical parsing model that exploits the morphology of the Spanish language. We find that incorporation of morphological information into a lexicalized probabilistic context-free grammar (PCFG) significantly improves the model's performance in parsing Spanish.
A syntactic parser takes as input a sentence or phrase and outputs a structure associated with it. The structure usually makes explicit the hierarchical phrasing in the sentence. Figures 1(a) and (b) are examples of parse trees associated with two Spanish phrases. Morphology is the study of how meaning-bearing units combine to form words. For example, in English the verb form eats may be explained as the combination of two morphemes — eat and s — where the latter marks the verb as 3rd-person singular. English is a weakly-inflected language exhibiting very few morphological changes to root forms; other languages, like Spanish, exhibit such changes far more extensively.
Spanish morphology is sensitive to several important features, for example person, case, number, and gender. By incorporating these features into a model of Spanish syntax, we hope to capture dependencies between lexical items that are linguistically constrained. For example, determiners, adjectives, and nouns are constrained to agree in number and gender when they occur in the same noun phrase (Figure 1). If the parser has access to these morphological features, it may make fewer mistakes when two or more analyses of the same sentence are possible.
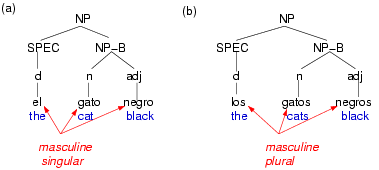
Figure 1: In Spanish, certain words constituting a noun phrase are constrained
to agree in gender and number.
While morphology is an important structural cue in Spanish, it is not obvious how to best profit from it computationally. For example, if we naively used all of the morphological information available to us in the treebank we use to train our model, the performance of our model would suffer due to data sparsity. We show that selectively adding morphological information improves the model's performance.
Approach
The basic approach we follow is to vary the morphological information that is available to the parser by modifying the part-of-speech (POS) tagset in the underlying model. For example, in the baseline model we might have a single POS tag n for every noun; in a more refined model sensitive to number information, we might have three POS tags for noun: one each for singular, plural, and number-neutral nouns.
Our underlying model is a lexicalized PCFG based on the Collins parser [2]. A PCFG is a set of grammatical rules and associated probabilities. Given a tree structure, there is a one-to-one mapping between each node and its children to a rule in the grammar; assuming independence in the application of the rules, the result of multiplying the associated probabilities provides a measure of the likelihood of a parse. Lexicalizing such a grammar usually means pairing lexical items (headwords) and POS tags (headtags) with the nonterminals. The subtree in Figure 2 has lexicalized nonterminals.
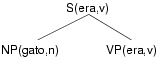
Figure 2: An NP modifying a VP under an S. Each nonterminal is labeled
with a lexical item (headword) and a POS tag (headtag).
To understand how changing the POS tagset affects the Collins model — and in particular to see how changing the POS tag definitions allows morphological information to be accessible to the parser — it is useful to understand how parameters are estimated in the Collins model. (Note that the parsing model includes several features, such as distance, subcategorization and so on, which we omit in the following discussion for the sake of clarity.) Consider, for example, the noun phrase (NP) modifier to the verb phrase (VP) in Figure 2. The probability associated with the NP is first decomposed using the chain rule:
![]()
Each term is then smoothed as follows:
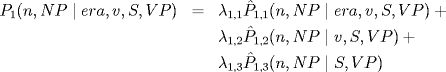
and
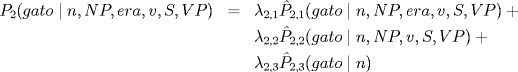
Here the ![]() terms are maximum likelihood estimates derived directly from
counts in the training data, and the
terms are maximum likelihood estimates derived directly from
counts in the training data, and the ![]() are scaling factors that are proportional to how often the
conditioning context of the associated term has been seen. Note that through
the maximum likelihood estimates, information from the POS categories
n and v is incorporated in a number of ways. When we
make the POS tags sensitive to morphological information such as number,
we can more effectively model situations such as a plural noun modifying
a plural verb, a plural noun modifying a singular verb, and so on. That
is, we can more effectively differentiate likely situations from unlikely
ones.
are scaling factors that are proportional to how often the
conditioning context of the associated term has been seen. Note that through
the maximum likelihood estimates, information from the POS categories
n and v is incorporated in a number of ways. When we
make the POS tags sensitive to morphological information such as number,
we can more effectively model situations such as a plural noun modifying
a plural verb, a plural noun modifying a singular verb, and so on. That
is, we can more effectively differentiate likely situations from unlikely
ones.
Experimental Results
We used a publicly-available Spanish treebank [6] consisting of approximately 3500 trees to train a baseline model (Collins model 1) and over 50 morphological models, each using different combinations of morphological features added to the baseline in the way described above. We divided the data into training/development (80%) and test (20%) sets. During development, we found that the model with the highest accuracy employed number for nouns, adjectives, determiners, verbs, and pronouns, as well as the mode of verbs. We trained this model and the baseline on the entire training set and tested using the held-out test data. The results using standard evaluation metrics (precision and recall of labeled/unlabeled dependencies as well as bracketed constituents) are in Tables 1 and 2.

Table 1: Precision and recall for recovery of labeled and unlabeled dependencies.
Row 1 is the baseline model, and row 2 is the morphological model.
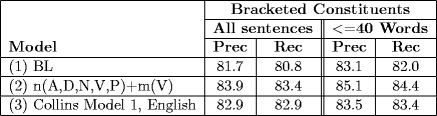
Table 2: Precision and recall for recovery of bracketed constituents.
Row 1 is the baseline; row 2 is the morphological model; row 3 is the
Collins parser trained on 2800 English trees from the Penn treebank, tested
on section 23 of the same.
The results in the tables show that adding some amount of morphological information to a lexicalized PCFG parsing model is beneficial for parsing Spanish. Not only does the morphologically-enhanced parser outperform our baseline, but it also performs comparably to parsers for languages other than English (e.g., [1],[3],[4],[5]); additionally, it performs comparably to a Collins model 1 English parser [2] trained on a equal amount of data.
Future Work
We have shown that the inclusion of morphological features in a parsing model for Spanish can improve its performance. One general direction for future work is to use a reranking model that would allow the inclusion of more Spanish features without compromising the ability of the model to adequately estimate its parameters. We would also like to try using the Spanish parser in an application such as machine translation to test its usefulness.
Support
This work was funded by the NSF though the MSPA-MCS program, award #DMS-0434222.
References
[1] David Chiang and Daniel M. Bikel. Recovering Latent Information in Treebanks. In Proceedings of COLING-2002, pages 183--189. 2002.
[2] Michael Collins. Head-Driven Statistical Models for Natural Language Parsing. University of Pennsylvania. 1999.
[3] Michael Collins, Jan Hajic, Lance Ranshaw, and Christoph Tillman. A Statistical Parser for Czech. In ACL 99, 1999.
[4] Amit Dubey and Frank Keller. Probabilistic Parsing for German using Sister-Head Dependencies. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics, pp. 96--103, July 2003.
[5] Roger Levy and Christopher Manning. Is it harder to parse Chinese, or the Chinese Treebank? In ACL 2003, pp. 439--446, 2003.
[6] Montserrat Civit Torruella. Guía para la anotación morfosintáctica del corpus CLiC-TALP. X-Tract Working Paper, WP-00/06. 2000.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |