
Improving the Performance of Vector Memory Systems
Christopher Batten, Ronny Krashinsky, Steve Gerding & Krste Asanovic
Motivation
Abundant data parallelism is found in a wide range of important compute-intensive applications, from scientific supercomputing to mobile media processing. Vector architectures exploit this data parallelism by arraying multiple clusters of functional units and register files to provide huge computational throughput at low power and low cost. Memory bandwidth is much more expensive to provide, and consequently often limits application performance.
Earlier vector supercomputers relied on interleaved SRAM memory banks to provide high bandwidth at moderate latency, but modern vector supercomputers now implement main memory with the same commodity DRAM parts as other sectors of the computing industry, for improved cost, power, and density. As with conventional scalar processors, designers of all classes of vector machine, from vector supercomputers to vector microprocessors, are motivated to add vector data caches to improve the effective bandwidth and latency of a DRAM main memory.
For vector codes with temporal locality, caches can provide a significant boost in throughput and a reduction in the energy consumed for off-chip accesses. But, even for codes with significant reuse, it is important that the cache not impede the flow of data from main memory. Existing non-blocking vector cache designs are complex since they must track all primary misses and merge secondary misses using replay queues. This complexity also pervades the vector unit itself, as element storage must be reserved for all pending data accesses in either vector registers or a decoupled load data queue.
In this research, we are considering two primary techniques to improve the performance of cached vector memory systems. First, we are investigating refill/access decoupling, which augments the vector processor with a Vector Refill Unit (VRU) to quickly pre-execute vector memory commands and issue any needed cache line refills ahead of regular execution. The VRU reduces costs by eliminating much of the outstanding miss state required in traditional vector architectures and by using the cache itself as a cost-effective prefetch buffer. We are also investigating vector segment memory accesses, a new class of vector memory instructions that efficiently encode two-dimensional access patterns. Segments reduce address bandwidth demands and enable more efficient refill/access decoupling by increasing the information contained in each vector memory command.
Approach: Refill/Access Decoupling
Refill/access decoupling is a simple and inexpensive mechanism to sustain high memory bandwidths in a cached vector machine. A scalar unit runs ahead queuing compactly encoded instructions for the vector units, and a Vector Refill Unit (VRU) quickly pre-executes vector memory instructions to detect which of the lines they will touch are not in cache and should be prefetched. This exact non-speculative hardware prefetch tries to ensure that when the vector memory instruction is eventually executed, it will find data already in cache. Figure 1 shows how a vector refill unit can be integrated into a decoupled vector machine. The cache can be simpler because we do not need to track and merge large numbers of pending misses. The vector unit is also simpler as less buffering is needed for pending element accesses. Vector refill/access decoupling is a microarchitectural technique that is invisible to software, and so can be used with any existing vector architecture.
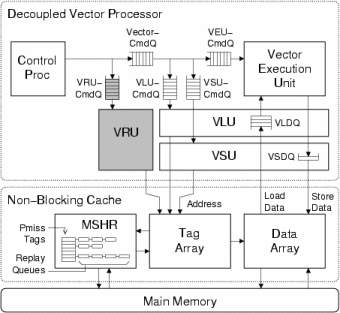
|
Figure 1. Basic decoupled vector machine (DVM). The vector processor is made up of several units including the control processor (CP), vector execution unit (VEU), vector load unit (VLU), and vector store unit (VSU). The non-blocking cache contains miss status handling registers (MSHR), a tag array, and a data array. Refill/access decoupling is enabled by adding the highlighted components: a vector refill unit (VRU) and corresponding command queue.
Approach: Vector Segment Memory Accesses
Vector unit-stride accesses move consecutive elements in memory into consecutive elements in a single vector register. Although these one-dimensional unit-stride access patterns are very common, many applications also include two-dimensional access patterns where consecutive elements in memory are moved into different vector registers. For example, assume that an application needs to process an array of three byte RGB pixels. A programmer might use the following sequence of strided vector accesses (each with a stride of three) to load an array (A) of pixels into the vector registers vr1, vr2, and vr3:
la r1, A li r2, 3 vlbst vr1, r1, r2 addu r1, r1, 1 vlbst vr2, r1, r2 addu r1, r1, 1 vlbst vr3, r1, r2
In this example, the programmer has converted a two-dimensional access pattern into multiple one-dimensional access patterns. Unfortunately, these multiple strided accesses hide the spatial locality in the original higher-order access pattern and can cause poor performance in the memory system including increased bank conflicts, wasted address bandwidth, additional access management state, and wasted non-allocating store data bandwidth. Vector segment memory accesses are a new vector mechanism which more directly captures the two-dimensional nature of many higher-order access patterns. They are similar in spirit to the stream loads and stores found in stream processors. As an example, the following sequence of vector instructions uses a segment access to load an array of RGB pixel values.
la r1, A vlbseg 3, vr1, r1
The vlbseg instruction has three fields: a segment length encoded as an immediate, a base destination vector register specifier, and a scalar base address register specifier. The instruction writes each element of each segment into consecutive vector registers starting with the base destination vector register. In this example, the red values would be loaded into vr1, the green values into vr2, and the blue values into vr3. Although conceptually straightforward, much of our work on segment accesses has focused on efficiently implementing these accesses in hardware.
Segment accesses are useful for more than just array-of-structures access patterns; they are appropriate any time a programmer needs to move consecutive elements in memory into different vector registers. Segments can be used to efficiently access sub-matrices in a larger matrix or to implement vector loop-raking. Vector segment instructions improve performance by converting some strided accesses into contiguous bursts, and improve the efficiency of refill/access decoupling by reducing the number of cache tag probes required by the refill engine.
Progress and Future Work
We have used various kernels to evaluate both refill/access decoupling and vector segment accesses. Our results show that refill/access decoupling is able to achieve better performance with less resources than more traditional decoupling methods. Even with a small cache and memory latencies as long as 800 cycles, refill/access decoupling can sustain several kilobytes of in-flight data with minimal access management state and no need for expensive reserved element buffering. Furthermore, kernels which can use vector segment accesses instead of multiple strided accesses have many fewer memory bank conflicts and thus are able to achieve significantly higher performance.
This work was presented at MICRO 2005 [1]. Copies of the paper and presentation slides are available at the SCALE group webpage. We are planning to integrate the techniques investigated in this research into the VLSI implementation of the SCALE prototype [2].
Research Support
This work was funded in part by NSF CAREER award CCR-0093354 and by the Cambridge-MIT Institute.
References
[1] Christopher Batten, Ronny Krashinsky, Steven Gerding, and Krste Asanovic. Cache Refill/Access Decoupling for Vector Machines. In 37th International Symposium on Microarchitecture, Portland, Oregon, December 2004.
[2] Ronny Krashinsky, Christopher Batten, Mark Hampton, Steve Gerding, Brian Pharris, Jared Casper, and Krste Asanovic. The Vector-Thread Architecture. In 31st International Symposium on Computer Architecture, Munich, Germany, June 2004.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |