
Tools for Automatic Transcription and Browsing of Audio-Visual Presentations
Scott Cyphers, Timothy J. Hazen & James R. Glass
Introduction
In the past decade, lower data storage costs and faster data transfer rates have made it feasible to provide on-line academic lecture material including audio-visual presentations. Such educational resources have the potential to eliminate many space and time constraints from the learning process by allowing people to access quality educational material irrespective of where they are or when they need it. Unlike text however, untranscribed audio data is tedious to browse, making it difficult to utilize the information to its full potential without time-consuming data preparation. In this work, we have developed a set of tools for automatically transcribing and indexing audio lectures as well as a prototype browser for searching and browsing these processed lectures.
Lecture Transcription
Our goal in this work is provide a web-based transcription service in which users can upload audio files to our system for automatic transcription and indexing. To help the recognition process, users could provide their own supplemental text files, such as journal articles, book chapters, etc., which would be used to adapt the language model and vocabulary of the system's speech recognition engine. Once uploaded, a speech recognition engine would transcribe the files in preparation for text indexing and browsing. The key steps of the transcription process are as follows:
- automatic segmentation of the audio file into 6 to 8 second chunks of speech separated by pauses
- adaptation of a topic-independent vocabulary and language model using the supplemental text data provided by the user
- automatic recognition of the audio chunks using a speech recognition system
The segmentation algorithm is performed in two steps. First the audio file is arbitrarily broken into 10 second chunks and processed with an efficient vocabulary- and speaker-independent phonetic recognizer. To help improve its speech detection accuracy, this recognizer contains models for non-lexical artifacts such as laughs and coughs as well as a variety of other noises. Contiguous regions of speech are identified from the phonetic recognition output, from which the segmenter constructs audio segments containing roughly 6 to 8 seconds of speech. Experiments have shown that longer segments tend to be computationally burdensome to the speech recognition search while shorter segments are harder to recognize accurately because they provide less context information to the language model.
Language model adaptation is performed is two steps. First the vocabulary of the supplemental text material is extracted and added to an existing topic-independent vocabulary of 16,671 words. Next, the recognizer interpolates topic-independent statistics from an existing corpus of lecture material with the topic-dependent statistics of the supplemental material to create a topic-adapted language model.
Once the audio data is segmented and the language model is adapted, the SUMMIT speech recognition system is used to transcribe the segmented audio [1]. This process can be efficiently performed with distributed processing over a bank of computation servers. Preliminary recognition experiments on a set of computer science lectures has been performed and reported on in [2]. Once recognition is completed, the audio data is indexed (based on the recognition output) in preparation for browsing by the user.
Lecture Browser
The lecture browser provides a graphical user interface to one or more automatically transcribed lectures. A user can type a text query to the browser and receive a list of hits within the indexed lectures. When a hit is selected, it is shown in the context of the lecture transcription. The user can adjust the duration of context preceding and following the hit, navigate to and from the preceding and following parts of the lecture, and listen to the displayed segment.
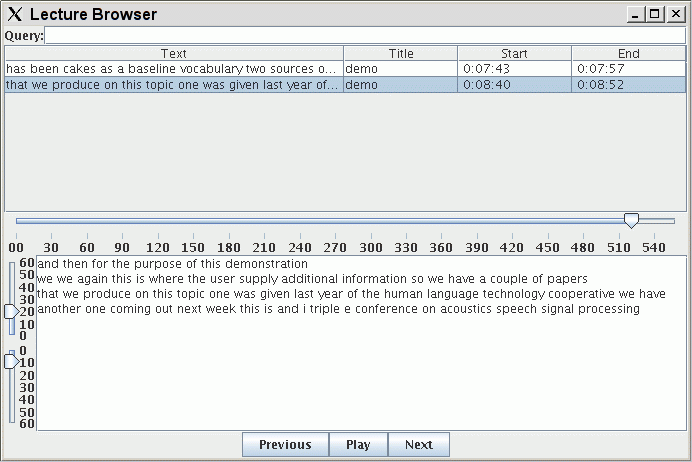
Lecture transcriptions are split into segments separated by two or more seconds of non-speech (as determined by the recognizer). We used the Java version of the Apache Lucene text search engine library http://lucene.apache.org/java/docs/index.html to index the segments.
The Lucene indexer is easy to use and provides stop-word removal and word stemming, but it does not provide the information needed for easy traversal from one segment to another, so we added a separate Berkeley DB Java Edition, http://sleepycat.com/products/je.shtml, database that contained additional information, such as timing for the segments and the words within the segments.
The user can type a query at the top of the browser. The query is sent directly to the Lucene query engine and can contain standard search connectives such as "AND" and "NEAR". The hits returned by Lucene are shown below the query line. The words in the segment, the lecture name and start/end time of the segment, retrieved from the Berkeley DB database are shown.
When a segment is selected, a horizontal slider shows where the hit appears in the segment's lecture and the segment containing the hit is shown in context. The user can jump to other parts of the lecture by moving the slider. Sliders control how many seconds of context before and after the selected segment are shown. Each segment is shown as a separate line, but, due to wrapping, not all lines correspond to segments.
At the bottom of the browser, "Previous" and "Next" buttons let the user step through the lecture. The "Play" button will play the displayed hit in context. Segments are highlighted as they are played.
Future Work
Our on-going work is split into two general areas: (1) improving the speech recognition accuracy of the automatic transcriber, and (2) investigating methods for the browser to display (potentially errorful) transcriptions to users so that they can quickly and accurately assess whether or not audio segment hits are relevant to their query and should be listened to. Once our set of tools is robust enough, we hope to make them available via a publicaly available web-service.
Acknowledgments
Support for this research has been provided by the MIT/Microsoft iCampus Alliance for Educational Technology.
References
[1] James R. Glass. A probabilistic framework for segment-based speech recognition. Computer Speech and Language, vol. 17, no. 2-3, pp. 137-152, April/July 2003.
[2] Alex Park, Timothy J. Hazen and James R. Glass. Automatic processing of audio lectures for information retrieval: Vocabulary selection and language modeling. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, March, 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |