
Concurrent Cache-Oblivious B-Trees
Michael A. Bender, Jeremy T. Fineman, Seth Gilbert & Bradley C. Kuszmaul
Introduction
For over three decades, the B-tree [5,12] has been the data structure of choice for maintaining searchable ordered data on disk. Even though the B-tree (provably) minimizes the number of block transfers during a search, the B-tree is empirically suboptimal because it exploits data locality at only one level of granularity (typically disk blocks), but not at coarser or finer granularities.
Recently the cache-oblivious B-tree [7] was proposed as a powerful alternative to the traditional B-tree. Cache-oblivious B-trees (and cache-oblivious data structures in general) achieve nearly optimal locality of reference at every granularity. Thus, a cache-oblivious B-tree simultaneously optimizes for cache misses, page faults, TLB misses, data prefetches, etc. Although the first cache-oblivious B-tree was too complicated to be practical [7], subsequent designs [8,11,16,22] rival B-trees both in simplicity and performance [8,10,11,16,17,22]. Indeed, preliminary experiments [9,16] have shown, surprisingly, that cache-oblivious B-trees can outperform traditional B-trees, sometimes by factors of more than 2.
Despite the potential performance advantages of cache-oblivious B-trees, they have yet to be implemented for real applications, such as file systems and databases. A prerequisite for the adoption of cache-oblivious B-trees is that they support concurrent operations.
Our research focuses on the first theoretical study of concurrent cache-oblivious (CO) B-trees. We extend the cache-oblivious model to apply to a parallel or distributed setting. We transform both serial CO B-tree designs into concurrent data structures, and we consider both lock-based and lock-free approaches to concurrency. We have designed three concurrent CO B-trees.
Model
B-trees (and other external-memory algorithms) are traditionally analyzed in the disk-access model (DAM) [1], in which internal memory has size M and is divided into blocks of size B, and external memory (disk) is arbitrarily large. Performance in the DAM model is measured in terms of the number of block transfers (and thus the B-tree supports optimal searches in the DAM model). In the cache-oblivious model [13,21], as in the DAM model, the objective is to minimize the number of data transfers between two levels. Unlike the DAM model, however, the parameters B, the block size, and M, the main-memory size, are unknown to the coder or to the algorithm. The main idea of the cache-oblivious model is that if an algorithm performs a nearly optimal number of memory transfers in a two-level model with unknown parameters, then the algorithm also performs a nearly optimal number of memory transfers on any unknown, multilevel memory hierarchy.
Serial CO B-trees
There are two main approaches to implementing a serial cache-oblivious
B-tree, both of which use static cache-oblivious search trees developed
in
[21] as a building block. A static cache-oblivious
search tree stores a set of N ordered elements and executes searches
using 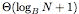 memory transfers.
In order to achieve efficient searches, the elements are laid out in an
array using the van Emde Boas layout (see below). Conceptually,
the tree is split at roughly half its height to obtain
memory transfers.
In order to achieve efficient searches, the elements are laid out in an
array using the van Emde Boas layout (see below). Conceptually,
the tree is split at roughly half its height to obtain 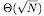 subtrees. The subtrees are stored
contiguously in the array; each subtree is laid out recursively.
subtrees. The subtrees are stored
contiguously in the array; each subtree is laid out recursively.
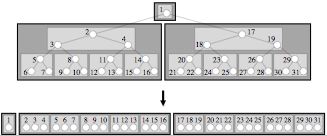 |
The van Emde Boas layout from [21]. A tree of height h is cut into subtrees at height near h/2. In the example on the right, we chose to cut the tree so that the child trees are a power of two in size, so the root tree only contains one node. |
The earliest serial (dynamic) cache-oblivious B-tree, presented in [7], is based on the packed-memory structure [7,15] and was subsequently simplified by [8,11]. The packed-memory structure stores the keys in order, subject to insertions and deletions, and uses a static (cache-oblivious) search tree to search the array efficiently.
The second approach
[6,22] uses an exponential search tree
[2,3] construction to transform the
static cache-oblivious search tree into a dynamic data structure. An exponential
search tree is similar in structure to a B-tree except that nodes vary
dramatically in size, there are only 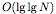 nodes on any root-to-leaf path, and the rebalancing scheme (where nodes
are split and merged) is based on some weight-balance property
[19], such as strong weight balance
[4,7,19,20].
Each node in the tree is laid out in memory using a van Emde Boas layout,
and the balancing scheme allows updates to the tree enough flexibility
to maintain the efficient layout despite changes in the tree.
nodes on any root-to-leaf path, and the rebalancing scheme (where nodes
are split and merged) is based on some weight-balance property
[19], such as strong weight balance
[4,7,19,20].
Each node in the tree is laid out in memory using a van Emde Boas layout,
and the balancing scheme allows updates to the tree enough flexibility
to maintain the efficient layout despite changes in the tree.
The Concurrency Problem
Concurrency introduces several challenges. A naive first approach is to attempt to lock segments of the data structure during an update. For example, in a traditional B-tree, an algorithm would normally attempt to lock a cache-line or a page. Unfortunately, in the cache-oblivious model, it is difficult to determine the correct granularity at which to acquire locks because the cache and page sizes are unknown. Locking too small a region may result in deadlock; locking too large a region may result in poor concurrency.
Second, in most database applications, search operations are significantly more common than insert or delete operations, so it is desirable that searches be nonblocking, meaning that each search operation can continue to make progress, even if other operations are stalled. Thus, we do not allow search operations to acquire locks, as a simple locking scheme might require.
Another problem arises with maintaining the "balance" of the data structures. Both main approaches to designing (serial) cache-oblivious B-trees require careful weight balance of the trees in order to guarantee efficient operation. With concurrent updates, the balance can be difficult to maintain.
Finally, there is a significant asymmetry between reading and writing the memory. Two processes can read a location in memory concurrently, since two caches can simultaneously hold the same block in a read-only state. In fact, it may be preferable if parts of the data structure, e.g., the root, are accessed frequently and so that they are maintained in cache by all processes. On the other hand, when multiple processes attempt to write to a block, the memory accesses to the block are effectively serialized, and all parallelism is lost.
We respond to these challenges by designing new serial data structure that are more amenable to parallel accesses, and then we apply concurrency techniques to develop our concurrent cache-oblivious B-trees.
Our Results
We have designed three concurrent cache-oblivious B-tree data structures: (1) Exponential CO B-tree (lock-based), (2) Packed-Memory CO B-tree (lock-based), and (3) Packed-Memory CO B-tree (nonblocking). Each data structure is linearizable, meaning that each completed operation (and a subset of the incomplete operations) can be assigned a serialization point; each operation appears, from an external viewer's perspective, as if it occurs exactly at the serialization point. (See [14,18] for a more complete definition.) The lock-based data structures are deadlock-free, i.e., some operation always eventually completes. The nonblocking B-tree is lock-free; that is, even if some processes fail, some operation always completes. When only one process is executing, the trees gain all the provably good performance advantages of optimal cache-obliviousness; for example, they execute operations with the same asymptotic performance as the nonconcurrent versions and behave well on a multilevel cache hierarchy without any explicit coding for the cache parameters. When more than one process is executing, the B-trees operate correctly and with little interference between disparate operations.
Future Work
We are looking for theoretical bounds on the performance of our data structures under various concurrent workloads.
Research Support
This research is supported in part by Singapore-MIT Alliance and by NSF Grants ACI-0324974 and CNS-0305606.
References
[1] Alok Aggarwal and Jeffrey Scott Vitter. The input/output complexity of sorting and related problems. Communications of the ACM, 31(9): pp. 1116—1127, September 1988.
[2] Arne Andersson. Faster deterministic sorting and searching in linear space. In Proceedings. of the 37th Annual Symposium on Foundations of Computer Science, pp. 135—141, 1996.
[3] Arne Andersson and Mikkel Thorup. Tighter worst-case bounds on dynamic searching and priority queues. In Proceedings. of the 32nd Annual Symposium on Theory of Computing, pp. 335—342, Portland, Oregon, May 2000.
[4] Lars Arge and Jeffrey Scott Vitter. Optimal dynamic interval management in external memory. In Proceedings. of the 37th Annual Symposium on Foundations of Computer Science, pp. 560—569, Burlington, VT, October 1996.
[5] Rudolf Bayer and Edward M. McCreight. Organization and maintenance of large ordered indexes. Acta Informatica, 1(3): pp. 173—189, February 1972.
[6] M. A. Bender, R. Cole, and R. Raman. Exponential structures for efficient cache-oblivious algorithms. In Proceedings. of the 29th International Colloquium on Automata, Languages, and Programming, pp. 195—207, 2002.
[7] M. A. Bender, E. Demaine, and M. Farach-Colton. Cache-oblivious B-trees. In Proceedings. of the 41st Annual Symposium on Foundations of Computer Science, pp. 399—409, 2000.
[8] M. A. Bender, Z. Duan, J. Iacono, and J. Wu. A locality-preserving cache-oblivious dynamic dictionary. In Proceedings. of the 13th Annual Symposium on Discrete Algorithms, pp. 29—38, 2002.
[9] M. A. Bender, M. Farach-Colton, and B. C. Kuszmaul. Cache-oblivious b-trees for optimizing disk performance. 2004.
[10] Michael A. Bender, Gerth Stølting Brodal, Rolf Fagerberg, Dongdong Ge, Simai He, Haodong Hu, John Iacono, and Alejandro López-Ortiz. The cost of cache-oblivious searching. In Proceedings. of the 44st Annual Symposium on Foundations of Computer Science, pp. 271—282, Cambridge, Massachusetts, October 2003.
[11] Gerth Stølting Brodal, Rolf Fagerberg, and Riko Jacob. Cache oblivious search trees via binary trees of small height. In Proceedings. of the 13th Annual Symposium on Discrete Algorithms, pp. 39—48, San Francisco, California, January 2002.
[12] D. Comer. The ubiquitous B-Tree. Computing Surveys, 11: pp. 121—137, 1979.
[13] Matteo Frigo, Charles E. Leiserson, Harald Prokop, and Sridhar Ramachandran. Cache-oblivious algorithms. In 40th Annual Symposium on Foundations of Computer Science, pp. 285—297, New York, New York, October 17—19 1999.
[14] Maurice P. Herlihy and Jeannette M. Wing. Linearizability: A correctness condition for concurrent objects. Transactions on Programming Languages and Systems, 12(3): pp. 463—492, 1990.
[15] Alon Itai, Alan G. Konheim, and Michael Rodeh. A sparse table implementation of priority queues. In S. Even and O. Kariv, editors, In Proceedings. of the 8th Colloquium on Automata, Languages, and Programming, volume 115 of LNCS, pp. 417—431, Acre (Akko), Israel, July13—17 1981.
[16] Zardosht Kasheff. Cache-oblivious dynamic search trees. Master's thesis, Massachusetts Institute of Technology, Cambridge, MA, June 2004.
[17] Richard E. Ladner, Ray Fortna, and Bao-Hoang Nguyen. A comparison of cache aware and cache oblivious static search trees using program instrumentation. In Experimental Algorithmics: From Algorithm Design to Robust and Efficient Software, volume 2547 of LNCS, pp. 78—92, 2002.
[18] Nancy Lynch. Distributed Algorithms. Morgan Kaufmann, 1996.
[19] Kurt Mehlhorn. Data Structures and Algorithms 1: Sorting and Searching, theorem 5, pp. 198—199. SpringerVerlag, Berlin, 1984.
[20] J. Ian Munro, Thomas Papadakis, and Robert Sedgewick. Deterministic skip lists. In Proceedings. of the 3rd Annual Symposium on Discrete Algorithms, pp 367—375, Orlando, Florida, January 1992.
[21] Harald Prokop. Cache-oblivious algorithms. Master's thesis, Massachusetts Institute of Technology, Cambridge, MA, June 1999.
[22] Naila Rahman, Richard Cole, and Rajeev Raman. Optimised predecessor data structures for internal memory. In Proceedings. of the 5th International Workshop on Algorithm Engineering, volume 2141 of LNCS, pp. 67—78, Aarhus, Denmark, August 2001.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |