
Efficient Incremental Algorithms for Dynamic Detection of Likely Invariants
Jeff H. Perkins & Michael D. Ernst
What
Dynamic detection of likely invariants [1] is a program analysis that generalizes over observed values to hypothesize program properties. The reported program properties are a set of likely invariants over the program, also known as an operational abstraction. Previous techniques for dynamic invariant detection report too few properties, or they scale poorly. This research takes steps toward correcting these problems. We have developed an optimized incremental algorithm [3] that provides more scalable invariant detection without sacrificing functionality.
Why
Dynamic invariant detection is an important and practical problem. Operational abstractions have been used to assist in verifying safety properties, theorem-proving, identifying refactoring opportunities, predicate abstraction, generating test cases, selecting and prioritizing test cases, explaining test failures, predicting incompatibilities in component upgrades, error detection, and error isolation, among other tasks. Dynamic invariant detection has been independently implemented by numerous research groups, and related tools that produce formal descriptions of run-time behavior have also seen wide use.
While dynamic invariant detection is valuable, implementing it efficiently is challenging. A naive implementation is straightforward but fails to scale to problems of substantial size.
Previous invariant detection algorithms detect only a few invariants or are expensive in time and space. For example, our previous approach [2] used a multi-pass batch algorithm. Each pass used the results of previous passes to limit the number of invariants that needed to be checked. The downside of this approach is the need to store the trace data so that it can be processed multiple times. Even modest traces can occupy gigabytes of disk space and, more seriously, memory.
How
The key to our new approach is to use an optimized incremental algorithm. Each sample is processed exactly once, thereby avoiding the need to store traces. The basic approach is to initially assume that all properties in the invariant grammar are true. A candidate invariant for each property and combination of variables is instantiated. Any invariants that are contradicted by a sample are removed. Unfortunately, the number of invariants that must be checked with this approach is a high-order polynomial on the number of variables: O(V9) if there are ternary invariants and ternary derived variables.
Many of these invariants, however, are redundant. Some reflect the same property reported in multiple ways. Or one or more properties may imply another (weaker) property. These redundancies provide significant opportunities for optimization. Implied invariants need not be checked or even instantiated as long as their antecedents are true.
When processing samples incrementally, the properties that enable optimizations are always subject to change. The algorithm, therefore, must be able to undo an optimization. This may require creating previously suppressed invariants and putting them in the same state they would have been in, had they processed all the samples that have been seen so far.
Progress
We have developed a number of effective optimizations. These have allowed us to discover invariants in programs of moderate size that previously could not be processed (due to memory constraints). For example, were were able to process the flex lexical analyzer, a C program that is part of the standard Linux distribution. The optimized algorithm creates less than 0.5 percent as many invariants as does the unoptimized version. Figure 1 shows these results as samples are processed.
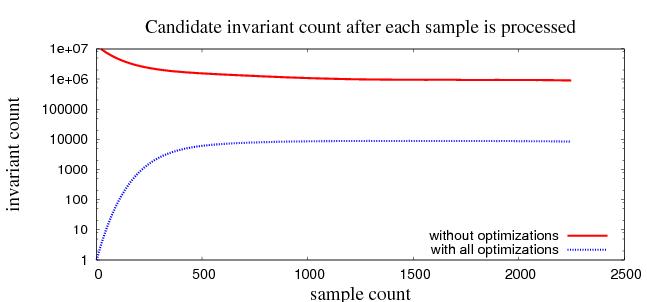 |
| Figure 1: The number of candidate invariants with optimizations and without optimizations as samples are processed. The data shown is from one of the 391 program points in the flex lexical analyzer. |
- Equality. If two or more variables are always equal, then
any invariant that is true for one of the variables is true for each
of the variables. For example, if x = y and x > z, then
y > z. More generally, for any invariant f, f(x)
implies f(y).
This optimization is realized by placing all comparable variables in an equivalence set. Invariants are only instantiated over set leaders. During processing, if any elements of the equivalence set differ, the equivalence set is broken into multiple parts, and invariants over the original leader are copied to the new leaders.
- Dynamic constants. A dynamic constant is a variable that has the same value at each sample. The invariant x = a (for constant a) makes any other invariant over (only) x redundant. For example x = 5 implies odd(x) and x > - 5. Likewise for combinations of variables: x = 5 and y = 6 implies both x < y and x = y - 1. The incremental algorithm maintains a set of dynamic constants and only instantiates invariants that include at least one non-constant.
- Program point and variable hierarchy. Some variable values
contribute to invariants at multiple program points. For two program
points
AandB, if all samples forBalso appear atA, then any invariant true atAis necessarily true atBand is redundant atB. In this case we say thatAis higher in the hierarchy thanB. For example, values observed at the exit of methodA.get()apply not only to invariants atA.get()but also to invariants at the objectA. ThusAis higher in the hierarchy thanA.get(). This provides an optimization opportunity. Only the leaves of the hierarchy are processed. Invariants at upper points are created by merging the results from the lower points. An invariant is true at an upper point iff it is true at each child of that point. - Suppression of weaker invariants. An invariant can be suppressed
if it is logically implied by some set of other invariants in a fashion
not explicitly addressed above. For example, x > y implies x
≥ y, and 0 < x < y and z = O imply x div y =
z.
Suppressed invariants are neither instantiated or processed as long as their antecedents remain true. No state whatsoever is maintained to indicate whether a non-existent invariant has been removed because it was falsified or was never instantiated because it is suppressed. This saves space, but at the cost of more complicated processing.
Whenever an invariant that might be an antecedent is falsified, every non-instantiated invariant that it might be suppressing is checked. If any suppression for the invariant holds before falsification of the antecedent, but no suppression holds after falsification of the antecedent, then the invariant must be instantiated. In other words, the invariant is un-suppressed (instantiated) as soon as the last suppression no longer holds.
These optimizations are implemented in version 3 of the Daikon invariant detector.
Future
We continue to refine our optimizations to further reduce the memory and time requried for processing. Also, in order to take full advantage of the incremental approach, we also want to detect invariants online (via a direct connection from the target program to the invariant detector) so that a trace file need not be created. We also want to explore a wider variety of realistically sized programs.
Research Support
This research is supported by gifts from IBM, NTT, and Toshiba, a grant from the MIT Deshpande Center, and NSF grant CCR-0234651.
References
[1] Michael D. Ernst, Jake Cockrell, William G. Griswold, and David Notkin. Dynamically discovering likely program invariants to support program evolution. in IEEE Transactions on Software Engineering, 27(2):1-25, February 2001.
[2] Michael D. Ernst, Adam Czeisler, William G. Griswold, and David Notkin. Quickly detecting relevant program invariants. In Proceedings of the 22nd International Conference on Software Engineering, pages 449-458, Limerick, Ireland, November 7-9 2000.
[3] Jeff H. Perkins and Michael D. Ernst. Efficient incremental algorithms for dynamic detection of likely invariants. In Proceedings of the ACM Sigsoft 12th Symposium on the Foundations of Software Engineering SIGSOFT (FSE 2004), pp 23-32, Newport Beach, California, USA November 2004
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |