
Accelerating Multiprocessor Simulation with a Memory Timestamp Record
Kenneth C. Barr, Heidi Pan, Michael Zhang & Krste Asanovic
Introduction
Computer architects rely heavily on software simulators to evaluate, refine, and validate new designs before implementation, but modern multiprocessors have a growing amount of microarchitectural state which must be "warmed" before detailed simulation to avoid cold-start effects. Some industry development groups report detailed warming requires up to two weeks when starting from stored architectural checkpoints. To address this bottleneck, we introduce a fast and accurate technique for warming the directory and cache state of a multiprocessor system based on a novel software structure called the memory timestamp record (MTR). The MTR is a versatile, compressed snapshot of memory reference patterns which can be rapidly updated during fast-forwarded simulation, or stored as part of a checkpoint. We study the MTR with a full-system simulation framework, which models a directory-based cache-coherent multiprocessor running a range of multithreaded workloads. With this framework, we find the MTR's performance predictions to be within 15% of our detailed model while running up to 7.7X faster.
Approach
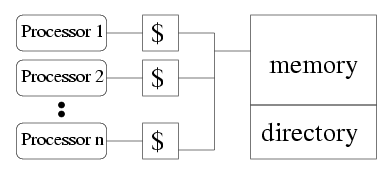
Figure 1 shows popular techniques used for sampling program execution to reduce simulation time. Phase-based selective sampling (1c) or uniform statistical sampling (1d, 1e) have been shown to provide high accuracy with a short runtimes. With such techniques, the bulk of execution time (up to 99.9% of instructions) is spent fast forwarding rather than running a detailed model [3]. This time may be amortized by storing the results of fast-forwarding in a checkpoint. In most cases, such a checkpoint is restricted to the microarchitecture that generated it, or -- if only programmer-visible state is stored -- requires a lengthy warming period. Warming is especially time-consuming in the context of a large symmetric multiprocessor (SMP) model which will have several caches and a directory (Figure 2). Not only does the multiprocessor have more state to warm, but multiprocessor experiments must be run several times in order to quantify the effects of system variation on application performance [1].
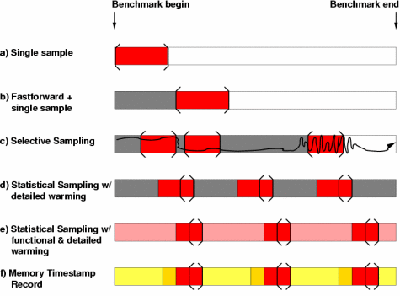

The MTR attacks lengthy warmup periods by simplifying the work that must be done during the bulk of simulation, moving all work to a single, fast reconstruction phase (1e). The technique works on uniprocessors, but is especially valuable for reducing the time necessary to simulate a multiprocessor. The contents of a single MTR can be used to fill in a variety of microarchitectures as the MTR supports common cache organizations, replacement policies, and coherence protocols.
During fast-forwarding, MTR reduces the amount of work per memory access to a simple and fast table update, deferring cache state reconstruction until the transition into detailed mode. The key observation is that directory and cache state can be reconstructed if, for each memory block, we know about each processor's latest accesses and the relative order of these accesses across processors. During MTR fast-forwarding, each simulated processor reads and writes a shared "magic memory" for instant resolution of loads and stores. We also capture the most recent memory accesses using the MTR structure shown in Figure 3. The MTR has an entry for every memory block. Each block's entry contains an array of read timestamps, one per processor, indicating the last time each processor read the block. Additional fields record the ID of the last processor to modify the block and the timestamp of the write. Each timestamp reflects the cycle in which the memory request was issued.
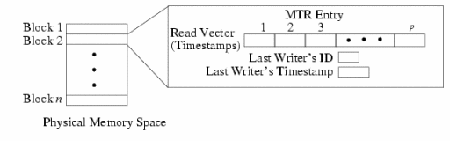
Caches and directory state are created from MTR snapshots in two phases. In the first, the abstract contents of the MTR are coalesced into the concrete cache structure. Since multiple memory blocks may map to the same cache set, the timestamps are used to preserve a least-recently-used replacement policy. Next, a fixup stage looks across the CPUs' caches to enforce a coherence policy. Reads prior to writes are invalidated, writes without a following read are marked modified and dirty, etc. Using slight modifications to our algorithms, the MTR can support:
- Snoopy or directory-based protocols
- Multilevel caches (inclusive or exclusive)
- Time-based replacement policies (strict LRU or cache decay)
- Invalidate, update, or hybrid coherence protocols
- MSI, MESI, and MOESI
Some ambiguities arise due to the MTR not storing evict times, but many of these ambiguities can be resolved by a more in-depth algorithm which counts the number of accesses in a window of time. If the count is greater than the associativity, a line must have been evicted in that window. Otherwise, the situation remains ambiguous, and time-based heuristics can be used to help the MTR-generated state match the state that would arise due to a detailed run.
Results
We combine a cycle-accurate, directory-based, cache-coherent memory system simulator with a Free, full-system, x86 emulator that allows us to boot SMP Linux 2.4.24. This allows us to run benchmarks that depend on the operating system for process scheduling and virtual memory. Our benchmarks include scientific code written in OpenMP/FORTRAN from NASA's Advanced Supercomputing Parallel benchmark suite; dbench, a concurrent file system stress test; apache; a concurrent web server stress test; and Cilk checkers, an AI benchmark with dynamic thread creation and scheduling.
We compare the MTR against a straightforward implemenation of fast functional warming (FFW) for an SMP. Note that on every memory access FFW must search for a tag match and update LRU bits. On a coherence miss, FFW must consult the directory, then find and invalidate outstanding copies of the cache block. We hypothesize that both FFW and MTR will be faster than a full detailed simulation, and that MTR will be faster than FFW because it performs less work in the common case (simple table updates rather than functional, multiprocessor cache simulation). To be useful, both the FFW and MTR schemes must not only run faster, but answer design questions in the same way as a full detailed model.
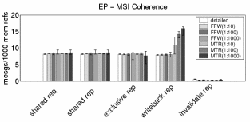
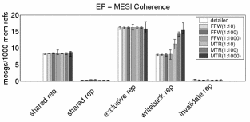
One such question is: "How does the number and makeup of network messages change when one changes the coherence mechanism from MSI to MESI?" We answer this question with the graphs shown in Figure 4. The x-axis lists five types of messages. On the y-axis, we measure messages per 1000 memory references. To show how system variations affect simulation measurements, we report each result as median of eight separate runs (denoted by the solid bars) and the range of values observed (as denoted by the thin lines). We use FFW(a:b) and MTR(a:b) to denote the results of FFW and MTR where a:b is the ratio of instructions executed in the detailed period to those executed in the fast period. The length of the detailed phase is fixed at 100,000 instructions. There are seven bars for each reported metric, each representing a simulation configuration: fully detailed run, FFW(1:10), FFW(1:100), FFW(1:1000), MTR(1:10), MTR(1:100), and MTR(1:1000).
As expected (unless many read-modify-writes are present), shared requests under MESI and MSI are similar. However, the shared replies are quite different, since part of the shared reply messages in MSI become exclusive reply messages in the MESI protocol. The increase in shared replies is prominent in both fast-forwarding and detailed simulation data, thus allowing one to draw the same conclusion about the effects of the MESI versus MSI with much shorter simulations. When we enhance MTR reconstruction to resolve certain eviction ambiguities, writeback messages converge to their detailed and FFW counterparts, because fewer spurious writeback messages get generated by incorrectly marked blocks (rightmost graph in Figure 4).
MTR edges out FFW by up to 1.45 times speedup on average. Small fast-to-detailed transition times confirm that the reconstruction time of the MTR scheme does not outweigh the speedup it can provide during fast mode. This is largely due to the fact that while our programs can make billions of memory references, the MTR compresses repeated references to the same block. The number of touched blocks which must be considered during reconstruction is a small fraction of the total requests -- usually less than half a percent. Although MTR achieves a respectable speedup in the serial execution of a single configuration, what is more exciting is the additional speedup from multi-configuration simulation and parallelization. Assuming 1% detailed execution time, we estimate that MTR could simulate five different configurations simultaneously and still have comparable running time to FFW running one configuration.
For completeness, we note that the MTR is 7.7 times faster than our detailed model when using the relatively accurate 1:100 sampling ratio. FFW is 5.5 times faster at this ratio. Of course, much higher speedups will be achieved when using a more complex detailed model, for example, with a detailed DRAM model in place of our fixed-latency memory, or an out-of-order superscalar processor model instead of our in-order single-issue processor model.
 |
 |
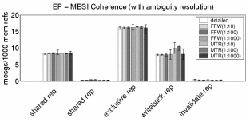 |
Figure 4. Comparison of MSI and MESI protocols using detailed, FFW, and MTR simulation.
Progress and Future Work
This work was presented at ISPASS 2005 [2]. Copies of the paper and presentation slides are available at the SCALE group webpage. Our simulation framework ties together a custom detailed memory system with Bochs, an open source x86 emulator. We host a wiki via http://www.cag.lcs.mit.edu/scale/bochs.html where other researchers interested in the frameworks can contribute suggestions and advice.
We plan to continue our investigation into quickly resolving ambiguous cases; compressing the MTR so that checkpoints require less storage space; and altering our simulator to support simultaneous simulation from single stored checkpoints.
Research Support
This work was partly funded by the DARPA HPCS/IBM PERCS project, NSF CAREER Award CCR-0093354, and an Intel Fellowship.
References
[1] Alan R. Alameldeen and David A. Wood. Addressing Workload Variability in Architectural Simulations. In HPCA-9, February 2003.
[2] Kenneth C. Barr, Heidi Pan, Michael Zhang, and Krste Asanovic. Accelerating Multiprocessor Simulation with a Memory Timestamp Record. In The Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software, pp. 66--77, Austin, Texas, USA, April 2005.
[3] R. Wunderlich et al. SMARTS: Accelerating microarchitecture simulation via rigorous statistical sampling. In Proceedings of the 30th International Symposium on Computer Architecture, June 2003.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |