
Dialog Context for Head Gesture Recognition
Louis-Philippe Morency & Trevor Darrell
Introduction
During face-to-face conversation, people use visual nonverbal feedback to communicate relevant information and to synchronize rhythm between participants. A good example of nonverbal feedback is head nodding and its use for visual grounding, turn-taking and answering yes/no questions. When recognizing visual feedback, people use more than their visual perception. Knowledge about the current topic and expectations from the previous utterances are also included with our visual perception to recognize nonverbal cues. Our goal is to equip an embodied conversational agent (ECA) with the ability to use contextual information for performing visual feedback recognition much in the same way people do.
In the last decade, many ECAs have been developed for face-to-face interaction. A key component of these systems is the dialogue manager, usually consisting of a history of the past events, the current state, and an agenda of future actions (see Figure 1). The dialogue manager uses contextual information to decide which verbal or nonverbal action the agent should perform next. This is called context-based synthesis.
Contextual information has proven useful for aiding speech recognition [1]. In this system, the grammar of the speech recognizer dynamically changes depending on the agent's previous action or utterance. In a similar fashion, we want to develop a context-based visual recognition module that builds upon the contextual information available in the dialogue manager to improve performance.
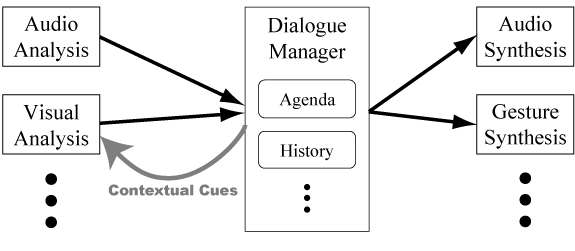
Figure 1: Simplified architecture for embodied conversational agent. Our method integrates contextual information from the dialogue manager inside the visual analysis module.
The use of dialogue context for visual gesture recognition has, to our knowledge, not been explored before for conversational interaction. Here we present a model for incorporating dialogue context into head gesture recognition. We exploit discriminative classifiers in our work, but other classification schemes could also fit into our approach.
We have designed a visual analysis module that can recognize head nods based on both visual and dialogue context cues. The contextual information is derived from the utterances of the ECA, which is readily available from the dialogue manager. We use a discriminative framework to detect head gestures from the frequency pattern of the user's head motion combined with contextual knowledge of the ECA's spoken utterance.
While some of systems [2,3] have incorporated tracking of fine motion actions or visual gesture, none have included top-down dialogue context as part of the visual recognition process. This abstract describes our framework for context-based visual feedback recognition.
Context in Embodied Conversational Agents
Figure 1 depicts a typical architecture for an embodied conversational agent. In this architecture, the dialogue manager contains two main sub-components, an agenda and a history. The agenda keeps a list of all the possible actions the agent and the user (i.e. human participant) can do next. This list is updated by the dialogue manager based on its discourse model (prior knowledge) and on the history. In our work we use the COLLAGEN conversation manager [4], but other dialogue managers provide these components as well.
Some interesting contextual cues can be estimated from the agenda:
- What will be the next utterance of our embodied agent?
- Are we expecting a specific utterance from the user?
- Is the user expected to look at a common space?
The history keeps a log of all the previous events that happened during the conversation. This information can be used to learn some interesting contextual cues:
- Did the user recently give verbal feedback?
- Does the user prefer speech or gesture to answer a question?
Based on the history, we can build a prior model of how a user interacts with the ECA. Similarly, the agenda can be used to determine the most likely visual feedback to be performed by the user. Both the history and agenda can serve as useful contextual cues for visual feedback recognition.
Dialogue Context for Gesture Recognition
People use contextual cues during conversation to predict the non-verbal behaviors of other people. We would like to provide the same information to the visual feedback module of an embodied agent. To accomplish this task, we seek contextual features that are readily available in most conversational agents, useful for visual feedback recognition. We also seek an integration framework that can efficiently extend pre-existing vision and dialogue systems. Figure 2 provides an overview of our solution, which includes a contextual predictor that translates the contextual features into a likelihood measure, similar to the visual recognition output and a merging node that fuses the visual and context likelihoods.
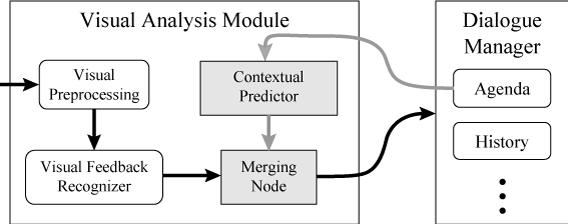
Figure 2: Augmented framework for context-based visual recognition. New context-based components are in grey. The contextual predictor translates contextual features into a likelihood measure, similar to the visual recognizer. The merging node fuses the visual and context likelihood measures.
Conclusion and Future Work
We presented a visual recognition model that integrates knowledge from the spoken dialogue of an embodied agent. By using simple contextual features like spoken utterance and question/statement differentiation, we were able to improve the performance of the vision-only head nod detector from 79% to 92% recognition rate. As future work, we would like to experiment with a richer set of contextual cues and apply our model to different types of visual feedback.
References
[1] Lemon, Gruenstein and Peters Stanley. Collaborative Activities and Multi-tasking in Dialogue Systems. Traitement Automatique des Langues (TAL), special issue on dialogue, 43(2):131--154, 2002.
[2] Nakano, Reinstein, Stocky, and Justine Cassell. Towards a model of face-to-face grounding. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Sapporo, Japan, July 2003.
[3] Breazeal, Hoffman, and A. Lockerd. Teaching and working with robots as a collaboration. In The Third International Conference on Autonomous Agents and Multi-Agent Systems AAMAS 2004, pages 10281035. ACM Press, July 2004.
[4] Rich, Sidner, and Neal Lesh. Collagen: Applying collaborative discourse theory to humancomputer interaction. AI Magazine, Special Issue on Intelligent User Interfaces, 22(4):1525, 2001.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |