
Fault-Tolerance in the Borealis Distributed Stream Processing System
Magdalena Balazinska, Hari Balakrishnan, Samuel Madden & Michael Stonebraker
Note: This project is part of the Borealis project.
Introduction
In recent years, a new class of data-intensive applications requiring near real-time processing of large volumes of streaming data has emerged. These stream processing applications arise in several different domains, including computer networks (e.g., intrusion detection), financial services (e.g., market feed processing), medical information systems (e.g., sensor-based patient monitoring), civil engineering (e.g., highway monitoring, pipeline health monitoring), and military systems (e.g., platoon tracking, target detection).
In all these domains, stream processing entails the composition of a relatively small set of operators (e.g., filters, aggregates, and correlations) that perform their computations on windows of data that move with time. Most stream processing applications require results to be continually produced at low latency, even in the face of high and variable input data rates. As has been widely noted [1, 3, 5], traditional data base management systems (DBMSs) based on the ``store-then-process'' model are inadequate for such high-rate, low-latency stream processing.
Stream processing engines (SPEs) (also known as data stream managers [1, 11] or continuous query processors [5]) are a class of software systems that handle the data processing requirements mentioned above. Over the last several years, a great deal of progress has been made in the area of SPEs. Several groups have developed working prototypes (e.g., Aurora, STREAM, TelegraphCQ) and many papers have been published on detailed aspects of the technology such as stream-oriented languages, resource-constrained one-pass query processing, load shedding, and distributed processing.
Stream processing applications are inherently distributed, both because input streams often arrive from geographically distributed data sources, and because running SPEs on multiple processing nodes enables better performance under high load [6, 12]. In a distributed SPE, each node produces result streams that are either sent to applications or to other nodes for additional processing. When a stream goes from one node to another, the nodes are called upstream and downstream neighbors. Figure 1 illustrates a query network distributed over three Borealis nodes. In Borealis, the application logic takes the form of a data flow: boxes represent operators and arrows represent data streams.
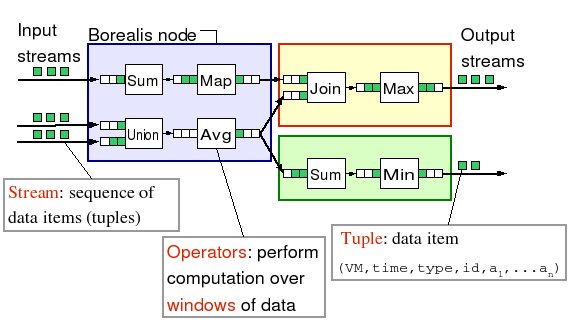
Figure 1 : Example of a query distributed across three nodes.
In this project, we add to the body of work on SPEs by addressing fault-tolerant stream processing. We design, implement, and evaluate a protocol that enables a distributed SPE to cope with a variety of network and system failures. More specifically, we address fail-stop failures of processing nodes, network failures, and network partitions. Our approach differs from previous work on high availability in streaming systems by offering a configurable trade-off between availability and consistency. Previous schemes either do not address network failures [10] or strictly favor consistency over availability, by requiring at least one fully connected copy of the query network to exist in order to continue processing at any time [12]. As such, our scheme is particularly well-suited for applications where it is possible to make significant progress even when some of the inputs are unavailable.
Our approach aims to reduce the degree of inconsistency in the system while guaranteeing that available inputs capable of being processed are processed within a specified time threshold. This threshold allows a user to trade availability for consistency: a larger time threshold decreases availability but limits inconsistency, while a smaller threshold increases availability but produces more inconsistent results based on partial data. In addition, when failures heal, our scheme corrects previously produced results, ensuring eventual consistency.
Our approach is motivated by the fact that many stream processing applications are geared toward monitoring tasks. In such tasks, when a failure occurs upstream from a non-blocking operator and causes some (but not all) of its input streams to be unavailable, it is often useful to continue processing the inputs that remain available. For example, in a network monitoring application, even if only a subset of network streams are available, processing their data might suffice to identify some potential attackers or detect other network anomalies. In this application, low latency processing is critical to mitigate attacks. Therefore, when a failure occurs, our scheme favors availability over consistency. After a failure heals, previously unavailable data streams are made available again. To ensure eventual consistency (i.e., to ensure that client applications eventually receive the complete correct streams), our system corrects the internal state of each processing node as well as the outputs produced during the failure to reflect the state they would have had if no failure had occurred.
Overview of the Approach
As in most previous work on masking software failures, we use replication [8]: for each processing node running a fragment of a query network, we run one or more identical replicas of that node. Each replica processes input tuples and produces results. Furthermore, each processing node and its replicas implement the state machine shown in Figure 2 that has three states: STABLE, UPSTREAM_FAILURE, and STABILIZATION. The basic idea is for each node or replica to manage its own consistency and availability.
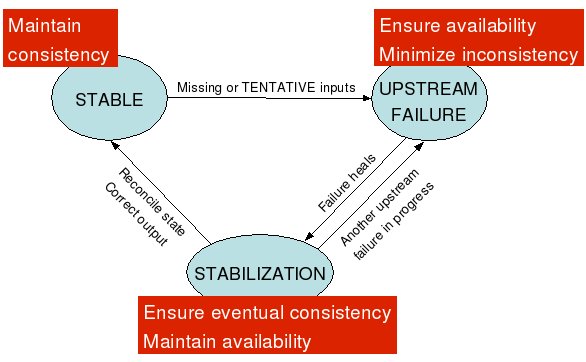
Figure 2 : Fault-tolerance state machine. Each state is annotated with
the fault-tolerance goals that the replica strives to achieve in that
state.
Initially, nodes start in the STABLE state. When a node stops receiving data (or ``heartbeat'' messages signifying liveness) from one of its upstream neighbors, it requests the missing input streams from a replica of that neighbor (if it can find one). For a node to be able to correctly continue processing after such a switch, all replicas of the same processing node must be consistent with each other. They must process their inputs in the same order, progress at roughly the same pace, and their internal computational state must be the same. To ensure replica consistency, we define a simple data-serializing operator, called SUnion, that takes multiple streams as input and produces one output stream with deterministically ordered tuples.
At the same time, if a node is unable to find a new upstream neighbor for an input stream, it must decide whether to continue processing with the remaining (partial) inputs, or block until the failure heals. If it chooses to continue, a number of possibly incorrect results will be produced, while blocking makes the system unavailable. Our approach gives the user explicit control of trade-offs between consistency and availability in the face of network failures. To provide high availability in the UPSTREAM_FAILURE state, each SPE processes the available ("partial") input data and forwards results within a user-specified time threshold of arrival, even if other inputs are currently unavailable. We introduce an enhanced streaming data model in which results based on partial inputs are marked as tentative, with the understanding that they may subsequently be modified; all other results are considered stable and immutable.
A failure heals when a previously unavailable upstream neighbor starts producing stable tuples again or when a node finds another replica of the upstream neighbor that can provide the stable version of the stream. Once a node receives the stable versions of all previously missing or tentative input tuples, it transitions into the STABILIZATION state. In this state, if the node processed any tentative tuples during UPSTREAM_FAILURE it must now reconcile its state by re-running its computation on the correct input streams. While correcting its internal state, the replica also stabilizes its output by replacing the previously tentative output with stable data tuples, allowing downstream neighbors to reconcile in turn.
While a node reconciles its state, new input tuples are likely to continue to arrive. Our approach enables a node to reconcile its state and correct its outputs, while ensuring that new tuples continue to be processed. We do so by forcing replicas to stagger their reconciliation. With this technique, downstream nodes always have access to at least one replica that produces results based on the most recent input data, while other replicas reconcile their state and stabilize their output streams.
Results
We have implemented our approach in Borealis [2] and evaluated its performance through experiments [4]. Here, we only show that our approach achieves the desired availability even for long failures and distributed deployments. We show the results of running a query network spanning a sequence of one to four processing nodes. Each processing node has two replicas (including itself). We cause a 15 second failure on one of three input streams. Figures 3 and 4 show the availability and consistency of the single output stream. More specifically, Figure 3 shows the availability of the output stream measured as the maximum per-tuple processing latency. Figure 4 shows the inconsistency measured as the number of tentative tuples produced on the output stream. In this experiment, the availability requirement is to process input tuples within 3 seconds per-node. The results show that it is critical for the system to process input tuples both during failure and stabilization in order to meet the required availability. The approach labeled "Suspend while reconciling" does not process new tuples during reconciliation. For sufficiently long failures, this approach fails to meet the availability requirement. Furthermore, with this technique the processing delay increases drastically with every node in the chain.
However, there are two ways in which the system can achieve the desired availability. Each node can process tentative tuples as they arrive ("Process without delay") during UPSTREAM_FAILURE and STABILIZATION or it can always delay these tuples as much as possible ("Delay as much as possible"). In the latter scenario, the system still meets the availability requirement but it always runs on the verge of breaking that requirement, thus delivering a reduced availability. Interestingly, if we measure the number of tentative tuples produced on the output stream, delaying tentative tuples not only does not provide any benefit but can even hurt when compared with no delay. Indeed, when STABILIZATION starts, each node in the sequence is delaying the data it receives by a little under 3 seconds, before processing it. As nodes reconcile their states, they no longer delay. They catch-up. Because nodes reconcile one after the other in sequence, all tuples processed during catch-up by a node are processed as tentative by its downstream neighbors that are still in UPSTREAM_FAILURE state. Hence, the catch-up undoes all the savings of the original delay. Furthermore, after the failure heals, nodes are processing more input tuples and in this experiment are actually producing more output tuples. Hence for long failures, processing new tuples without delay delivers the best availability and consistency.
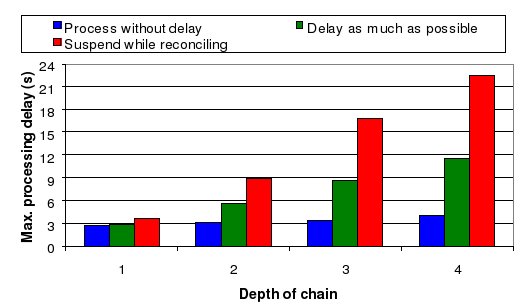
Figure 3 : Availability of the output stream when a failure and recovery
propagate through a chain of 1 to 4 processing nodes. Suspending while
reconciling fails to meet the availability requirement.
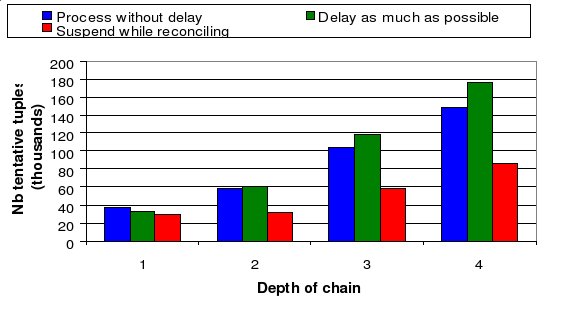
Figure 4 : Inconsistency of the output stream when a failure and recovery
propagate through a chain of 1 to 4 processing nodes. For long failures,
processing tentative tuples without delay does not hurt consistency.
Conclusion
We presented a replication-based approach to fault-tolerant stream processing that handles node failures, network failures, and network partitions. Our approach uses a new data model that distinguishes between stable tuples and tentative tuples, which result from processing partial inputs and may later be corrected. Our approach favors availability but guarantees eventual consistency.
Our fault-tolerance protocol addresses the problem of minimizing the number of tentative tuples while guaranteeing that the results corresponding to any new tuple are sent downstream within a specified time threshold. The ability to trade availability (via a user-specified threshold) for consistency (measured by the number of tentative result tuples, since that is often a reasonable proxy for replica inconsistency) is useful in many streaming applications where having perfect answers at all times is not essential. Our approach also performs well in the face of the non-uniform failure durations observed in empirical measurements of system failures: most failures are short, but most of the downtime of a system component is due to long-duration failures [7, 9]. More details about the approach can be found in [4].
Research Support
This material is based upon work supported by the National Science Foundation under Grants No. 0205445. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Magdalena Balazinska is supported by a Microsoft Graduate Fellowship.
References:
[1] Abadi et al. Aurora: A New Model and Architecture for Data Stream Management. In VLDB Journal, 12(2), September 2003.
[2] Abadi et al. The Design of the Borealis Stream Processing Engine. In Proceeding of the Second CIDR Conference. January 2005.
[3] Brian Babcock, Shivnath Babu, Mayur Datar, Rajeev Motwani, and Jennifer Widom. Models and Issues in Data Stream Systems. In Proceeding of the 2002 ACM PODS Conference. June 2002.
[4] Magdalena Balazinska, Hari Balakrishnan, Samuel Madden, and Michael Stonebraker. Fault-Tolerance in the Borealis Distributed Stream Processing System. In Proceeding of the 2005 ACM SIGMOD Conference. June 2005.
[5] Chandrasekaran et al. TelegraphCQ: Continuous Dataflow Processing for an Uncertain World. In Proceeding of the First CIDR Conference. January 2003.
[6] Cherniack et al. Scalable Distributed Stream Processing. In Proceeding of the First CIDR Conference. January 2003.
[7] Nick Feamster, David G. Andersen, Hari Balakrishnan, and Frans Kaashoek. Measuring the Effects of Internet Path Faults on Reactive Routing. In Proceedings of the ACM Sigmetrics - Performance 2003. June 2003.
[8] Jim Gray, Pat Helland, Patrick O'Neil, and Dennis Shasha. The Dangers of Replication and a Solution. In Proceeding of the 1996 ACM SIGMOD Conference. June 1996.
[9] Jim Gray and Andreas Reuters. Transaction Processing: Concepts and Techniques. Morgan Kaufmann. 1993.
[10] Jeong-Hyon Hwang, Magdalena Balazinska, Alexander Rasin, Ugur Cetintemel, Michael Stonebraker, and Stan Zdonik. High-Availability Algorithms for Distributed Stream Processing. In Proceeding of the 21st ICDE Conference. April 2005.
[11] Motwani et al. Query Processing, Approximation, and Resource Management in a Data Stream Management System. In Proceeding of the First CIDR Conference. January 2003.
[12] Mehul Shah, Joseph Hellerstein, and Eric Brewer. Highly-Available, Fault-Tolerant, Parallel Dataflows. In Proceeding of the 2004 ACM SIGMOD Conference. June 2004.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |