
Automatic Synthesis of Cache-Coherence Protocol Processors Using Bluespec
Man Cheuk Ng, Nirav Dave & Arvind
Introduction
It has been shown previously that cache-coherence protocols can be described precisely and naturally using TRSs [1]. Such descriptions allow separating the protocol into mandatory and voluntary rules which in turn has been shown to reduce the verification effort. Unfortunately, when it is time to implement these verified cache coherence protocols in hardware, designers are often unable to translate the high-level descriptions directly into hardware, either due to inappropriateness of the protocol mechanisms for hardware, or other real-world constraints (e.g. timing, area). Any modification of the protocol during the implementation stage essentially opens up the Pandora's box of verification. Ordinary verification techniques do not work well with cache coherence protocol implementations because of their time-dependent, nondeterministic behaviors. In fact, the task of proving that the implementation of a protocol is correct is as difficult as the task of verifying the correctness of the cache coherence protocol in the first place.
In this project, we will show that the TRS descriptions of cache-coherence protocols can be expressed in Bluespec SystemVerilog (BSV), a hardware description language based on guarded atomic actions. Further, we will show that, by using BSV compiler, we can automatically synthesize a hardware implementation. Such high-level synthesis will dramatically raise our ability to experiment with protocols and processor-memory interfaces in multiprocessor systems.
Approach
It has been shown previously that it is straightforward to translate TRS rules into BSV [2, 3]. Unfortunately, we find that a direct translation does not automatically guarantee an efficient and correct implementation of a cache-coherence protocol processor and requires the following modifications:
- BSV Modules: BSV allows designs to be divided into modules. A module interacts with the outside world through its interface, which provides communication channels for data input and output. Designers can change the implementation of a module without affecting other parts of the design as long as the module provides the same interface. With a strong abstraction for the communication channels between modules, BSV designs can even be highly parameterized. Therefore, it is preferable to make the design modular and partition the TRS rules into appropriate modules. Sometimes, this requires certain TRS rules to be split into multiple rules so that each of them can reside in different modules. This splitting must be done carefully because it may affect the correctness of the implementation by breaking the atomicity of the original rule.
- Buffer Management: To simplify the verification process, most high-level cache-coherence protocols assume simple but unrealistic buffer managements. For example, many protocols assume the sizes of the buffer queues are infinite to prevent deadlock. On the contrary, finite sizes are required for these queues in BSV so that the compiler can synthesize the design into hardware. In this case, designers need to calculate the minimum size of each buffer queue when they are translating the protocols into BSV descriptions. Apart from the buffer size problem, some protocols may also require buffers to be able to reorder the their storage data to prevent deadlock. Queues with type of property are usually not provided by the standard BSV library. Therefore, designer need to program this feature explicitly when these kind of queues are used in their design.
- Fairness: Some cache-coherence protocols achieve forward progress by requiring the system to possess the strong fairness property, which ensures that if a rule is enabled an infinite number of times, it will fire eventually. On the other hand, the BSV compiler generates hardware schedulers that follow some static rule property in scheduling to simplify the resulting circuitry. This compiler simplification introduces the possibility of breaking the strong fairness property required by some protocols. The solution to this problem is to add an arbitrator explicitly to the system whenever strong fairness is required for correctness.
Progress
We have implemented a non-blocking MSI cache coherence protocol for a DSM system (Figure 1). The TRS description of the protocol was presented in the Computer System Architecture course in Fall 2004 at MIT. After we have translated the TRS rules into BSV rules, we made the necessary modifications to ensure the correctness by following the methodology discussed in the previous section: First, we divided our design into two kind of modules: Cache-side Protocol Processor (CPP) modules and Memory-side Protocol Processor (MPP) modules. Each kind is responsible for protocol traffic at cache-side and memory-side respectively. Second, for buffer management, the protocol classifies the request messages from the caches to the main memory as low priority messages and the reply messages as high priority messages. The protocol requires that a low priority message can never block a high priority message indefinitely. We achieves this by having separate buffer queues for each type of messages. On the other hand, there is no restriction on the sizes of all the buffers existed in the protocol since size variations only affect the performance but not the correctness for this protocol. Finally, for the fairness issue, we added an arbitrator to the MPP so that the low priority messages from each CPP are guaranteed to be processed by the MPP eventually.
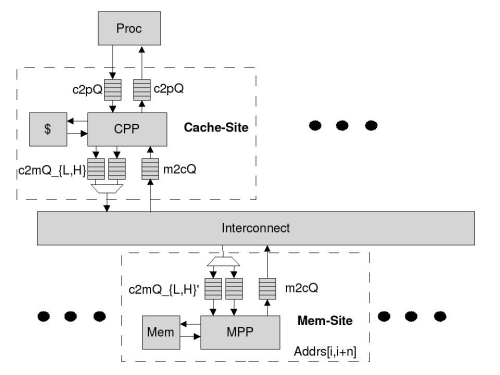
|
The final design is parameterized by the number of CPPs, the number of MPPs, the size of memory in each of these units, and the sizes of various queues. The design can also be modified with some effort so that it can accept various cache organizations (e.g., direct mapped, set associative) as a parameter. It only took 1050 lines of BSV code to represent the processor for this protocol. Once the protocol was defined in the tabular form, the design was completed in 3 man-days by two of the authors. Both the designers had expert level understanding of BSV and the MSI protocol presented. Nearly half of this time was spent finding and correcting typographical errors in the translation. No other functional errors were found or introduced in this encoding phase. The rest of the time was spent in tuning for performance and setting up the test bench.
The final design was tested and synthesized for both 4 and 8 instantiated caches. Compilation of design remained roughly constant, taking 333 seconds for a 4 cache system , and 339 seconds for an 8 cache one.
For testing, A directed random trace of cache requests was fed to each CPP. The testbench sustained an average latency of 1.3 cycles per lookup with a single-cycle latency cache, and a 10 cycle latency main memory with miss rate at roughly 5%.
Future
We plan to modify out work so that designs generated by our tools will be compatible with the UNUM framework [4], which models various PowerPC microarchitectures for multiprocessor configurations. By doing so, we will be able to generate a series of modular memory systems, each with its own coherence protocol but with identical interfaces to the processor modules. Our setup would provide a much more realistic setting for both protocol verification and performance measurements than traditional simulators. Additionally, we plan to map these BSV designs onto large FPGAs.
Research Support
Funding for this work has been provided by the IBM agreement number W0133890 as a part of DARPA's PERCS Projects.
References
[1] J. E. Stoy, X. Shen and Arvind. Proofs of Correctness of Cache-Coherence Protocols. In The Proceedings of FME'01: Formal Methods for Increasing Software Productivity, pp. 47-71, London, UK, 2001.
[2] N. Dave. Designing a Processor in Bluespec. Master's Thesis, MIT, Cambridge, MA, January 2005.
[3] Bluespec, Inc. Bluespec SystemVerilog Version 3.8 Reference Guide. Waltham, MA, November 2004.
[4] N. Dave, M. Pellauer and Arvind. UNUM: A General Microprocessor Framework Using Guarded Atomic Actions. CSAIL Research Abstracts 2005, MIT, Cambridge, MA, April 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |