
Hybrid Space-Time Partitioning of Stream Programs
Michael Gordon, Jasper Lin, William Thies & Saman Amarasinghe
What
We are developing compiler technology for StreamIt [3], a high-level stream programming language that aims for portability across communication-exposed machines. StreamIt contains basic constructs that expose the parallelism and communication of streaming applications, independent of the topology or granularity of the underlying architecture. There are two methods for compiling stream programs to a parallel architecture: time multiplexing and space multiplexing. Time multiplexing provides efficient load balancing by synchronizing operations through memory, while space multiplexing provides producer-consumer locality and scales with spatially-aware architectures. In this work, we are developing a hybrid backend that uses time multiplexing to switch between several space-multiplexed phases, thereby leveraging the benefits of both execution models. Our compiler targets the MIT Raw architecture [4], a tiled machine with fine-grained, programmable communication between processors.
Why
As we approach the billion-transistor era, a number of emerging architectures are addressing the wire delay problem by replicating the basic processing unit and exposing the communication between units to a software layer. These machines are especially well-suited for streaming applications that have regular communication patterns and widespread parallelism. However, today's communication-exposed architectures are lacking a portable programming model. If these machines are to be widely used, it is imperative that one be able to write a program once, in a high-level language, and rely on a compiler to produce an efficient executable on any of the candidate targets.
How
Given a stream graph, composed of filters (actors) and uni-directional FIFO channels connecting the filters, what is the best way to execute it? If we are targeting a uniprocessor, the most obvious technique is time multiplexing where we run one filter at a time on the processor. Load balancing is not an issue and the memory interface provides synchronization. Problems arise if we target a multiprocessor. Time multiplexing leads to long latency, lots of memory traffic (possibly with bad cache behavior), and the utilization depends on the presence of data-parallel filters that can be spread across the chip.
A second approach is to run all the filters in parallel, each on its own tile. This is termed space multiplexing. Our first StreamIt compiler for Raw uses this technique [1]. Space multiplexing affords (i) no filter-swapping overhead, (ii) reduced memory traffic, (iii) localized communication, and (iv) tighter latencies. Due to these properties, space multiplexing scales extremely well, although it is subject to effective load balancing techniques. Toward that end, merging and splitting components of the stream graph until it is composed of n load balanced filters, where n <= the number of processing elements, proved difficult, as the optimization technique is constrained by several competing factors. Further, the use of space multiplexing alone forced us to support arbitrarily complex communication patterns that did not map efficiently to the 2-D mesh in Raw.
The technique employed by our new backend for Raw is to merge the advantages of space multiplexing and time multiplexing. This hybrid approach will time multiplex different groups of filters and space multiplex the filters within a group. We call each group a space-time slice or just a slice. Hybrid space-time multiplexing allows space multiplexing for fine-grained, systolic sections of the stream graph and time multiplexing for improved load balancing. Furthermore, we use software pipelining techniques to allow arbitrary ordering of slices during steady-state execution.
An integral part of our technique is to recognize parts of the stream graph that can be space-multiplexed in a fine-grained, systolic fashion. Using our linear analysis framework [2], we can discover the linear sections of a streaming application. We define a linear section of a stream graph as a group of filters that compute a linear combination of their inputs. Many ubiquitous DSP kernels are linear including FIR, low and high-pass filters, and DFT. These linear computations can be represented as a matrix multiplication and efficiently mapped to Raw. Linear slices of the stream graph are space-multiplexed across tiles of the chip using parameterized computation and communication code. The matrix representations of the linear filters are broken into pieces that the compiler targets for aggressive code generation. This results in optimal usage of the tiles for each piece.
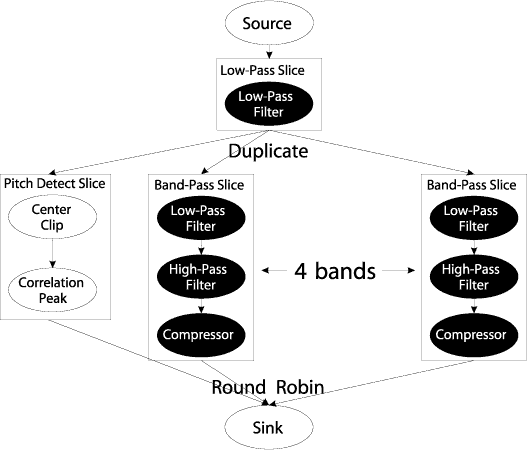
We will now present a small example to solidify the reader's understanding of our work. In the above figure we show the stream graph for a simple channel vocoder. The dark ovals denote the linear filters of the application. The white ovals are non-linear but stateless filters and thus can be data-parallelized.
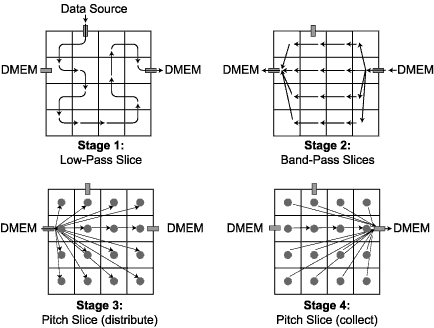
An example mapping of this application to a 16 tile Raw configuration (figure above) first executes the top low-pass filter slice, occupying the entire Raw chip and executing enough times to supply the subsequent slices. Next, each band-pass slice will occupy a quarter of the chip, executing the 4 bands in parallel. Remember that each of the above slices are linear and our parameterized linear code generation provides near-optimal utilization. Finally, the non-linear, stateless pitch detector slice is data-parallelized across the entire Raw chip. Each slice reads its input from and writes its output to off-chip DRAM.
Progress
Currently, we have completed a first version of our hybrid space-time multiplexing Raw backend for StreamIt and are in the process of evaluating its performance and scalability. We have a robust implementation of inter-slice communication using Raw's off-chip streaming memory interface. For intra-slice communication, we exploit Raw's static network and translate StreamIt's filter code into C code to be executed on the compute processors. We have completed parameterized code generation for linear filters that generates assembly directly.
As for the high-level algorithms, we have implemented a greedy algorithm to partition and schedule the stream graph into ordered slices. This algorithm has the freedom of producing an arbitrary ordering of slices to best distribute the work evenly, while the software pipelining algorithm is responsible for mapping the schedule and producing a valid execution---by determining what initialization steps are necessary for steady-state execution.
Future
In the near future we would like to explore more advanced partitioning and layout algorithms. Additionally, we will further expand space multiplexing as we investigate additional parallelism schemes such as filter fission (breaking a filter into multiple, smaller filters), state-space filter representations, and optimized linear code generation for sparse matrices. We are also working on a new intermediate representation for our compiler that will allow us to directly generate assembly code for Raw's compute processors. This will overcome some of the inefficiencies in generating stream code via a procedural framework.
Research Support
This work is supported in part by a grant from DARPA (PCA F29601-04-2-0166), awards from NSF (CISE EIA-0071841, ITR ACI-0325297, NGS CNS-0305453) and the MIT-Oxygen Project.
References:
[1] Michael Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali S. Meli, Andrew A. Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, and Saman Amarasinghe. A Stream Compiler for Communication-Exposed Architectures. In ASPLOS, 2002.
[2] Andrew A. Lamb, William Thies, and Saman Amarasinghe. Linear Analysis and Optimization of Stream Programs. In ACM Conference on Programming Language Design and Implementation, 2003.
[3] William Thies, Michal Karczmarek, and Saman Amarasinghe. StreamIt: A Language for Streaming Applications. In Proc. of the International Conference of Compiler Construction, Grenoble, France, 2002.
[4] Elliot Waingold, Michael Taylor, Devabhaktuni Srikrishna, Vivek Sarkar, Walter Lee, Victor Lee, Jang Kim, Matthew Frank, Peter Finch, Rajeev Barua, Jonathan Babb, Saman Amarasinghe, and Anant Agarwal. Baring It All To Software: Raw Machines. IEEE Computer, 30(9), 1997.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |