
LOUD: A 1020-Node Modular Microphone Array and Beamformer for Intelligent Computing Spaces
Eugene Weinstein, Kenneth Steele, Anant Agarwal & James Glass
Abstract
Ubiquitous computing environments are characterized by an unbounded amount of noise and crosstalk. In these environments, traditional methods of sound capture are insufficient, and array microphones are needed in order to obtain a clean recording of desired speech. In this work, we have designed, implemented, and tested LOUD [1], a novel 1020-node microphone array utilizing the Raw tile parallel processor architecture [2] for computation. LOUD is currently the largest microphone array in the world (Guinness World Records). We have explored the uses of the array within ubiquitous computing scenarios by implementing an acoustic beamforming algorithm for sound source amplification in a noisy environment, and have obtained preliminary results demonstrating the efficacy of the array.

Motivation
The interaction between humans and computers has been a central focus of ubiquitous computing research in recent times. In particular, communication through speech has been extensively explored as a method for making human-computer interaction more natural. However, computer recognition of human speech performs well only when a recording can be made without the presence of much ambient noise or crosstalk. Seeking to create a natural setting, ubiquitous computing environments tend to fall in this category of situations where natural-interaction speech recognition is a challenging problem. When significant levels of noise are present, or several humans are talking at the same time, recognition becomes difficult, if not impossible, in the absence of an appropriate technology to separate the desired speech from the undesired speech and ambient noise.
Implementation
The 1020-node microphone array is constructed from 510 two-microphone boards. This modular structure allows creating arrays of many different shapes. Each board has two microphones, one stereo A-to-D converter, and a small CPLD. The A-to-D converter samples at 16 KHz, generating 24-bit serial data for each microphone. The serial data streams are sent back to the Raw handheld board using time division multiplexing and streamed into one of Raw's input ports.
In order to utilize the microphone array to selectively amplify sound coming from a particular source or sources, we have used a beamforming algorithm [3] on the Raw microprocessor. Beamforming algorithms use the properties of sound propagation through space for sound source separation. The delay for the sound wave to propagate from one microphone in the array to the next can be empirically measured or calculated from the array geometry. This delay is different for each direction of sound propagation, i.e., the sound source position. By delaying the signal from each microphone by an amount of time corresponding to the direction of propagation and then summing the delayed signals, we can selectively amplify sound coming from a particular direction.
Experiments
Our experiments with the LOUD array involved recording a person speaking in a room where several sources of noise were present. The room was a very noisy hardware laboratory. The main noise sources were several tens of cooling fans for computers and custom hardware, and a loud air conditioner. The subject read a series of digit strings, and the speech was recorded with various subsets of the LOUD microphone array and a high-quality noise-canceling close talking microphone (i.e., "clean" speech). In some of the trials, another person served as the "interferer," reading a text passage at the same time as the main speaker is speaking digit strings. A delay-and-sum [3] beamforming algorithm was then applied to each subset of microphones to provide one resulting waveform of the speaker's voice.
The evaluation portion of our experiment consisted of running the output of the beamforming algorithm through the MIT SUMMIT speech recognizer [4]. The recognizer was trained on a combination of clean and noisy speech. For this initial round of experiments, we recorded 150 utterances from two male speakers with an interferer, and 110 utterances from the same speakers without interferers. The data for the close-talking microphone were collected as 80 utterances with an interferer at the same time as the array experiments, in order to provide a baseline for the speech recognition experiments.
Results
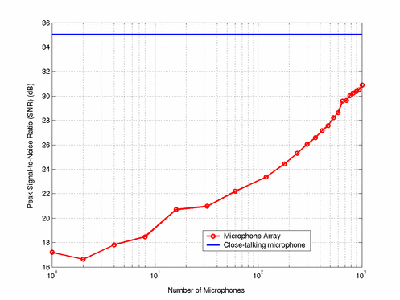
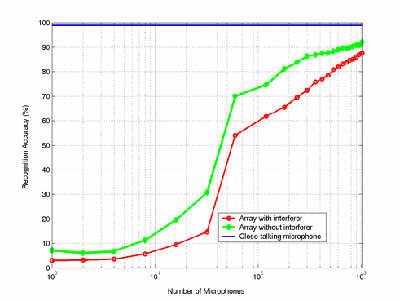
Figure 2 gives approximate peak signal-to-noise ratios (SNRs) in dB for a representative utterance, displaying the trend of improvement as the number of microphones is increased. The close-talking microphone, with an SNR level of 35.0dB, serves as the baseline. The SNR improves from 17.2dB with one microphone to 30.9dB with all 1020 microphones. This 13.7dB improvement corresponds to a 4.6-fold improvement in the ratio of signal energy to noise energy. Figure 3 gives the speech recognition accuracy rates for the experimental data that we have collected, for all the array sizes ranging from one microphone to all 1020. Our baseline accuracy is for a close-talking microphone, at 98.8%. For one microphone, the accuracy is below 10% both with and without an interferer, meaning acceptable recognition is impossible to achieve. The accuracy rises above 50% around 60 microphones (one full row of the array) -- a reasonable recognition hypothesis can sometimes be made at this level. All 1020 microphones yield 87.6% accuracy (87.2% drop in word error rate) in the presence of an interferer and 90.6% (89.6% drop in WER) without an interferer.
|
|
Figure 2: Peak signal-to-noise ratios for one representative recording from the microphone array. |
Figure 3: Experimental results from the LOUD microphone array. Results for data recorded with the array both in the presence of an interference, and when the interferer is absent, are given. The baseline level of 98.8% accuracy is given when using a high-quality close-talking microphone. |
The most drastic jump in the recognition accuracy curve is seen when the number of microphones jumps from 32 to 60, most likely because this completes the full line of the array (60 microphones), making the beam width almost twice as narrow as with 32 microphones. After this point, adding more microphones does not make the array wider, just taller. Another reason for the jump is that the landmark component of the recognizerwas not optimized for low SNRs. We note that the accuracy even with 1020 microphones (87.6% and 90.6%) is clearly significantly short of the 98.8% baseline from the close-talking microphone; and this is consistent with the SNRs noted in the recordings. However, with more complicated signal processing and beamforming algorithms, we are confident that the recognition accuracy of audio recorded with the array can approach that of a close-talking microphone. One can imagine that a projection based on Figures 1 and 2 will eventually allow array performance to reach close-talking microphone levels.
Links
For video demonstrations of the microphone array, please see this page.
References
[1] E. Weinstein, K. Steele, A. Agarwal, and J. Glass. LOUD: A 1020-Node Modular Microphone Array and Beamformer for Intelligent Computing Spaces. MIT/LCS Technical Memo MIT-LCS-TM-642, April, 2004
[2] M. B. Taylor et al. The Raw Microprocessor: A Computational Fabric for Software Circuits and General Purpose Programs. IEEE Micro, March/April 2002.
[3] Van Trees, H.L. Optimum Array Processing. Wiley-Interscience (2002).
[4] Glass, J. A probabilistic framework for segment-based speech recognition. Computer, Speech, and Language 17 (2003) 137-152
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |