
Active Exploration for Maximising Map Accuracy
Nicholas Roy
What
Tremendous progress has been made recently in simultaneous localisation and mapping of unknown environments. Using sensor and odometry data from an exploring mobile robot, it has become much easier to build high-quality globally consistent maps of many large, real-world environments. However, relatively little attention has been given to the trajectories that generate the data for building these maps. Exploration strategies are often used to cover the largest amount of unknown space as quickly as possible, but few strategies exist for building the most reliable map possible. Nevertheless, the particular control strategy can have a substantial impact on the quality of the resulting map. We have developed control algorithms for exploring unknown space that explicitly tries to build as large a map as possible while maintaining as accurate a map as possible.
Why
Recording the sensor data for a good map is not necessarily a straight-forward
process, even done manually. The control strategy used to acquire the
data can have a substantial impact on the quality of the resulting map;
different kinds of motions can lead to greater or smaller errors in the
mapping process. Ideally, we would like to automate the exploration process,
not just for efficient exploration of unknown areas of space, but exploration
that will lead to high accuracy maps. How We consider the problem of building
an accurate map in the Extended Kalman Filter framework [1].
The approach we take is to use a one-step lookahead, choosing trajectories
that maximise the space explored while minimising the likelihood we will
become lost on re-entering known space. In this case, the single step
is over a path from the existing map through unexplored space to the first
sensor reading from within the known map. At every time step, we will
choose a trajectory that will minimise our uncertainty as we re-enter
the map, at the same time maximising the coverage of the unexplored area.
We use a parameterised class of paths and repeatedly choose the parameter
setting that maximises our objective function. The class of paths is given
by the parametric curve [2]:
which expresses the distance ![]() of the robot from the origin as a function of time;
of the robot from the origin as a function of time; ![]() is a dilating constant and
is a dilating constant and ![]() parameterises the curve to control the frequency with which the robot
moves toward the origin. The rate of new space covered as a function of
parameterises the curve to control the frequency with which the robot
moves toward the origin. The rate of new space covered as a function of
![]() decreases roughly monotonically as
decreases roughly monotonically as ![]() increases, since for larger
increases, since for larger ![]() the robot spends an increasing amount of time in previously explored
territory.
the robot spends an increasing amount of time in previously explored
territory.
For a particular trajectory ![]() , we define an objective function for computing the optimal
trajectory,
, we define an objective function for computing the optimal
trajectory, ![]() , from
, from ![]() to
to ![]() as the amount of unexplored space covered from
as the amount of unexplored space covered from ![]() to
to ![]() , reduced by the uncertainty of state estimate at time
, reduced by the uncertainty of state estimate at time ![]() . Let us use
. Let us use ![]() as an indicator function, whether or not the pose of the
robot at time
as an indicator function, whether or not the pose of the
robot at time ![]() is in explored space. There are many choices for quantifying the
uncertainty of the EKF filter at time
is in explored space. There are many choices for quantifying the
uncertainty of the EKF filter at time ![]() : we will use one of the most common functions, the determinant of
the covariance matrix,
: we will use one of the most common functions, the determinant of
the covariance matrix, ![]() . These two functions give us our objective function
. These two functions give us our objective function
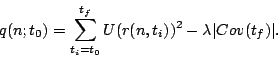 |
(2) |
This function contains the one free parameter ![]() that allows us to vary how aggressive the exploration of unknown
space should be compared with building a high-accuracy map.
that allows us to vary how aggressive the exploration of unknown
space should be compared with building a high-accuracy map.
Progress
Given the policy class ![]() and objective function
and objective function ![]() described above, we want to find
described above, we want to find ![]() to maximise
to maximise ![]() . For a particular state of the Extended Kalman Filter
at time
. For a particular state of the Extended Kalman Filter
at time ![]() , we cannot compute the covariance at time
, we cannot compute the covariance at time ![]() in closed form so we use numerical simulation, projecting the Kalman
filter forward until the trajectory enters unexplored space and then returns
into the map. We discretise
in closed form so we use numerical simulation, projecting the Kalman
filter forward until the trajectory enters unexplored space and then returns
into the map. We discretise ![]() and evaluate
and evaluate ![]() for each choice of
for each choice of ![]() .
.
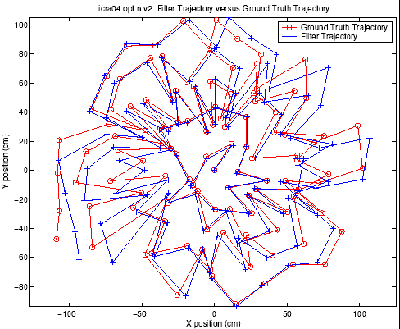
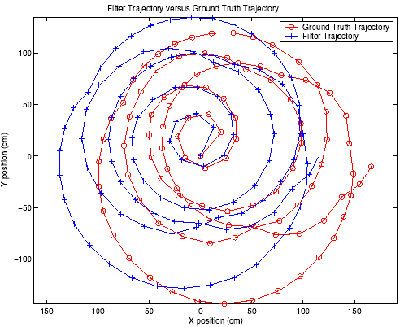 |
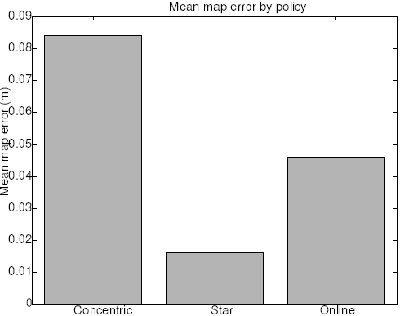
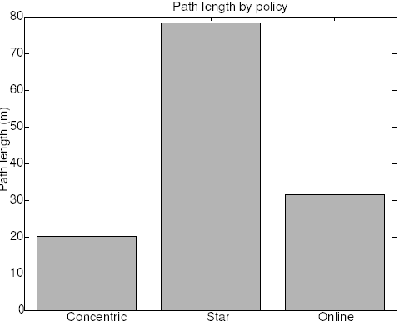 |
Future
The online strategy currently contains at some open problems. Firstly,
the reward function contains an explicit trade-off between exploration
and map accuracy, represented by the free parameter ![]() . Ideally, the optimal control representation would not contain
any free parameters. We may be able to eliminate this free parameter by
choosing a different reward function, but this is a question for further
research. Secondly, the particular parameterisation may not be the best
policy class. This policy class is somewhat restrictive, in that the single
parameter essentially represents a frequency of returning to the origin.
We may be able to achieve better results using a more general policy class,
such as one of the stochastic policy classes in the reinforcement learning
literature. Finally, the strategy is greedy, in that it attempts to choose
the trajectory based on a single projection into the future. However,
as more of the map is acquired, it may become possible to infer unseen
map structure and make more intelligent decisions, leading to even better
performance in more structured and regular environments.
. Ideally, the optimal control representation would not contain
any free parameters. We may be able to eliminate this free parameter by
choosing a different reward function, but this is a question for further
research. Secondly, the particular parameterisation may not be the best
policy class. This policy class is somewhat restrictive, in that the single
parameter essentially represents a frequency of returning to the origin.
We may be able to achieve better results using a more general policy class,
such as one of the stochastic policy classes in the reinforcement learning
literature. Finally, the strategy is greedy, in that it attempts to choose
the trajectory based on a single projection into the future. However,
as more of the map is acquired, it may become possible to infer unseen
map structure and make more intelligent decisions, leading to even better
performance in more structured and regular environments.
Acknowledgments
This is joint work with Robert Sim and Gregory Dudek.
References
[1]J. J. Leonard, I. J. Cox, and H. F. Durrant-Whyte. Dynamic map building for an autonomous mobile robot. Int. J. Robotics Research, 11(4):286--298, 1992.
[2] Robert Sim and Gregory Dudek. Effective exploration strategies for the construction of visual maps. In Proc. IJCAI Workshop on Reasoning with Uncertainty in Robotics (RUR), pages 69--76, 2003.
[3] Robert Sim, Gregory Dudek, and Nicholas Roy. Online control policy optimization for minimizing map uncertainty during exploration. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2004), New Orleans, LA, April 2004.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |