
AXCIS: Rapid Processor Architectural Exploration using Compressed Instruction Segments
Rose Liu & Krste Asanovic
Introduction
In the early stages of processor design, computer architects are faced with exploring a very large design space. Detailed, cycle-accurate simulation is an effective and widely used tool for evaluating different design points. However, the slow speed of current cycle-accurate microarchitectural simulators severely limit the number of designs that can be explored.
Previous works have proposed techniques to decrease simulation time by eliminating unneeded information processed by cycle-accurate simulators. As shown in these previous works, simulation time is a function of the input benchmark size and the level of microarchitectural detail simulated. Decreasing either of these parameters leads to faster simulation time. For example, the use of statistically reduced datasets and time sampling of the execution trace are two ways of reducing simulator input size, and analytical modeling is a faster alternative to detailed simulation. However, these techniques often suffer from high errors in corner cases because they require critical information that was not retained in the simulation. Therefore the problem is to find and retain only the information that is critical to simulation accuracy.
In this work, we introduce instruction segments as a new way of abstracting the full dynamic program trace to expose the critical information needed for accurate performance simulation. Using the idea of instruction segments, we present AXCIS, a technique for fast and accurate design space exploration. In addition, we provide some initial results of AXCIS in the context of superscalar processors.
The AXCIS Technique
AXCIS divides simulation into two stages: Dynamic Trace Compression and Abstract Performance Modeling. In the first stage, the Dynamic Trace Compressor (DTC) compacts the full dynamic instruction trace into a compressed instruction segment table (CIST). As shown in Figure 1, the CIST and a microarchitecture configuration are then fed into an Abstract Performance Model (APM), which calculates the instructions per cycle (IPC), a commonly used performance metric. Each CIST can be re-used to simulate multiple designs. Also, since CISTs are very small compared to the original dynamic instruction trace, the APM is much faster than conventional simulators.
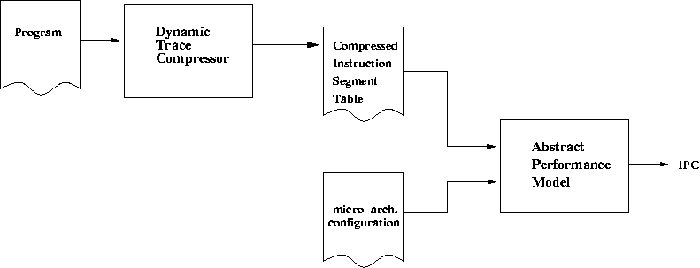
The Dynamic Trace Compressor compactly records data dependencies by exploiting the repetition of data dependence patterns from loops, function calls, and code re-use in the dynamic trace of a program. Data dependence patterns can be expressed as directed acyclic graphs of instruction types, called instruction segments. An instruction type is an abstraction that groups together instructions that share the same latency. For example, all simple integer arithmetic and logic instructions are of type iALU. These instructions are generally computed by the same type of microarchitectural unit, and thus experience the same latency. The DTC compresses the dynamic trace by detecting and eliminating the repetition of instruction segments. The DTC records only one instance of each segment along with a frequency count to indicate the number of times each segment occurred. The DTC also records the total number of instructions in the dynamic trace. The resulting compressed table of instruction segments (CIST) is microarchitecture independent. Although the DTC does require that any microarchitecture explored have the same mapping from instruction to instruction type, the DTC does not fix any particular latency to an instruction type. Therefore a compressed trace can be re-used when simulating a variety of different microarchitectural designs. Note that CISTs contain only the information needed for accurate performance calculation. CISTs cannot be used to recreate the original dynamic trace.
Given a microarchitecture configuration and a CIST, the Abstract Performance Model estimates IPC, expressed as
 .
.
Net stall cycles, which can be negative in a superscalar machine, is calculated by summing the product of the stall cycles and corresponding occurrences of each instruction segment. Net stall cycles, is then combined with the total instructions to obtain IPC.
Instruction Segments
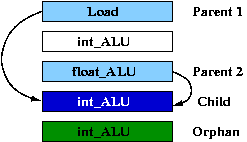
The instruction segment primitive captures the data dependencies for each instruction. Therefore, one instruction segment is defined for each executed instruction. Figure 2 shows a sample instruction segment. Note that although one instruction segment is defined for each instruction, we are able to significantly compress the number of instruction segments and the number of instructions needed for accurate performance simulation.
Before we define what instruction segments are, we first introduce some terminology.
- Parent Instruction: Instruction that produces a value that is read by a later instruction.
- Child Instruction: Instruction that reads a value produced by an earlier instruction.
- Orphan Instruction: Instruction that has no parents.
An instruction segment is defined as a sequence of instruction types that start from the earliest parent instruction down to the child instruction. If there are consecutive orphan instructions (instructions with no parents) immediately following the child instruction, then these orphan instructions are also included within the instruction segment.
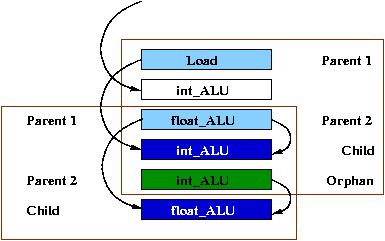
As shown in Figure 3, the instruction segments overlap with each other. This shows that data dependencies of different instructions overlap, causing the stall cycles experienced by different instructions to overlap. Because instruction segments completely capture the data dependencies for each instruction, we are able to accurately account for the overlap in stall cycles during performance simulation.
|
Figure 2: Example of isolated instruction segment |
Figure 3: Example of 2 overlapping instruction segments |
Initial Results
We applied AXCIS to simulate an in-order superscalar processor with no caches and perfect branch prediction. We evaluated AXCIS by comparing the IPCs of 11 SPEC2000 [1] benchmarks estimated by AXCIS and a detailed cycle-accurate performance simulator built on top of SimpleScalar sim-safe [2]. For our experiments, we simulated an 8 issue, in-order microarchitectural design with 4 integer ALU units, 2 memory read ports, 1 memory write port, 1 floating point unit, and various latencies for each unit. Each of the 11 benchmarks were simulated for 1 billion instructions.
AXCIS is run by first feeding the 11 benchmarks through the Dynamic Trace Compressor to obtain 11 corresponding CISTs. These CISTs are then fed into to the Abstract Performance Model along with a microarchitecture configuration.
The detailed cycle-accurate performance simulator is run by feeding the 11 benchmarks directly in the simulator along with a microarchitecture configuration.
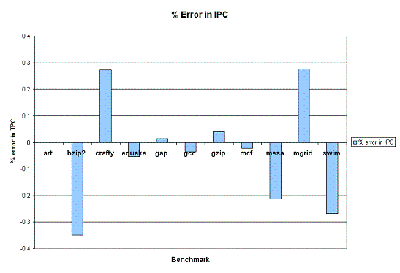
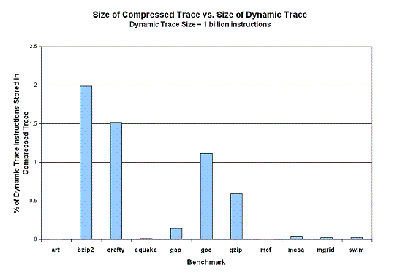
As can be seen in Figure 4, the Abstract Performance Model produced IPC estimates within 1 percent of that produced by a detailed cycle-accurate performance simulator. Also, as can be seen in Figure 5, the Dynamic Trace Compressor was able to compress the dynamic trace down to less than 2 percent of its original size of 1 billion instructions. Therefore in the worst case for bzip2, the Abstract Performance Model only had to simulate up to 20 million instructions, where the cycle-accurate simulator needed to simulate 1 billion instructions to obtain comparable results. For the other SPEC2000 benchmarks, the Abstract Performance Model could even simulate for much less than 20 million instructions.
|
Figure 4: Accuracy of IPC estimated by the Abstract Performance Model |
Figure 5: Evaluation of Compression achieved by the Dynamic Trace Compressor |
Work in Progress and Future
We are extending AXCIS to support modeling of caches and branch prediction. We also hope to explore the applications of instruction segments in workload characterization.
Research Support
This work is supported by an NSF Graduate Fellowship, and the DARPA HPCS/IBM PERCS project.
References:
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |