
Victim Replication: Maximizing Capacity while Hiding Wire Delay in Tiled Chip Multiprocessors
Michael Zhang & Krste Asanovic
Introduction
Chip multiprocessors (CMPs) exploit increasing transistor counts by placing multiple processors on a single die. CMPs are attractive for applications with significant thread-level parallelism where they can provide higher throughput and consume less energy per operation than a wider-issue uniprocessor. In future CMPs, both the processor count and the L2 cache size are likely to increase, with the wire delay reaching tens of clock cycles for cross-chip communication latencies. Most current L2 caches have a simple fixed-latency pipeline to access all L2 cache slices. Using the worst-case latency, however, will result in unacceptable hit times for the larger caches expected in future processors. We believe future CMP designs will naturally evolve toward arrays of replicated tiles connected over a switched network. Tiled CMPs scale well to larger processor counts and can easily support families of products with varying numbers of tiles. In our study, we focus on a class of tiled CMPs where each tile contains a processor with primary caches, a slice of the L2 cache, and a connection to the on-chip network, as shown in Figure 1.
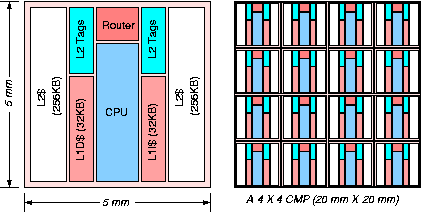
Design
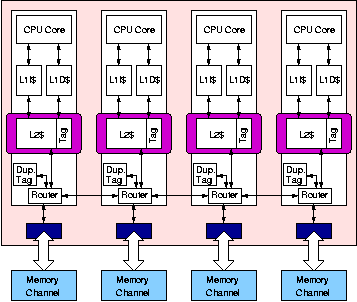
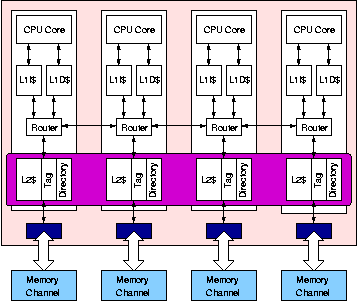
There are two basic schemes to manage the on-chip L2 storage in these tiled CMPs: 1) each L2 slice is treated as a private L2 cache for the local processor (shown in Figure 2), or 2) the distributed L2 slices are aggregated to form a single high-capacity shared L2 cache for all tiles (shown in Figure 3). We refer to these two schemes as L2P and L2S, respectively. The L2P scheme has low L2 hit latency, providing good performance when the working set fits in the local L2 slice. But each tile must keep a local copy of any data it touches, reducing the total effective on-chip cache capacity for shared data. Also, the fixed partitioning of resources does not allow a thread with a larger working set to "borrow" L2 cache capacity from other tiles hosting threads with smaller working sets. The L2S scheme reduces the off-chip miss rate for large shared working sets, but the network latency between a processor and an L2 cache slice varies widely depending on their relative placement on the die and on network congestion. As we will show in the results, the higher L2 hit latency can sometimes outweigh the capacity advantage of the shared L2 cache, and cross-chip latencies will continue to grow in future technologies. We introduce victim replication [1], a hybrid cache management policy which combines the advantages of both private and shared L2 schemes. Victim replication (L2VR) is based on the shared L2 scheme, but reduces hit latency over L2S by allowing multiple copies of a cache line to co-exist in different L2 slices of the shared L2 cache. Each copy of an L2 cache line residing on a tile other than its home tile is a replica. In effect, replicas form dynamically-created private L2 caches to reduce hit latency for the local processor. We show that victim replication provides better overall performance than either private or shared cache designs.
 |
 |
| Figure 2: The baseline private L2 design. Each
L2 slice is treated as a private cache to its local processor. |
Figure 3: The baseline shared L2 design. All L2
slices are treated as part of a global shared cache for all processors. |
Methodology
We have implemented a full-system execution-driven simulator based on the Bochs system emulator. We added a cycle-accurate cache and memory simulator with detailed models of the primary caches, the L2 caches, the 2D mesh network, and the DRAM. Both instruction and data memory reference streams are extracted from Bochs and fed into the detailed memory simulator at run time. The combined limitations of Bochs and our Linux port restricts our simulations to 8 processors. Results are obtained by running Linux 2.4.24 compiled for an x86 processor on an 8-way tiled CMP arranged in a 4 by 2 grid. To simplify result reporting, all latencies are scaled to the access time of the primary cache, which takes a single clock cycle. The 1MB local L2 cache slice has a 6 cycle hit latency. We assume a 70nm technology and model each hop in the network as taking 3 cycles, including the router latency and an optimally-buffered 5mm inter-tile copper wire on a high metal layer. DRAM accesses have a minimum of 256 cycles of latency. We used a mix of single-threaded and multi-threaded benchmarks to evaluation victim replication. All 12 SpecINT2000 benchmarks are used as single-threaded workloads. The multi-threaded workloads include all 8 of the OpenMP NAS Parallel Benchmarks (NPB), as well as two OS-intensive server benchmarks and one AI benchmark.
Results
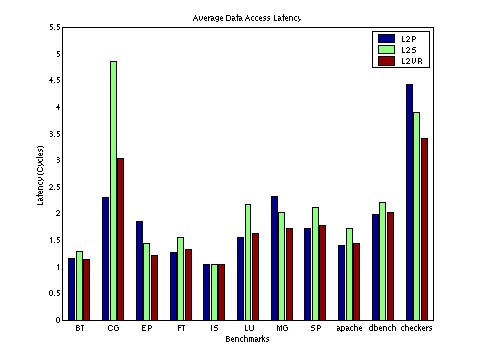
Multi-threaded Benchmark Results: The primary results of our evaluation are shown in Figure 4, which shows the average memory access latency experienced by a memory access from a processor. The minimum possible access latency is one cycle, when all accesses hit in the primary cache. Table 1 shows the per-benchmark savings achieved by L2VR over L2S, on which it is based. Out of the eleven benchmarks, one is unaffected by L2 policy. Three benchmarks perform better with L2S than L2P, but perform best with L2VR. Six benchmarks perform better with L2P than L2S, but L2VR has similar performance to L2P. For only one benchmark, CG, does L2VR fall significantly behind L2P. Figure 5 plots the percentage of total L2 cache capacity allocated to replicas for the eleven multi-threaded benchmarks in our benchmark suite against execution time. This graph shows two important features of L2VR. First, it is an adaptive process that adjusts to the execution phases of the program. Execution phases can be clearly observed in CG, FT, and dbench. Second, the victim storage capacity offered by L2VR is much larger than a realistic implementation of a dedicated hardware victim cache, as five out of the eleven benchmarks reached over 30% replicas, corresponding to over 300KB of victim cache capacity.
 |
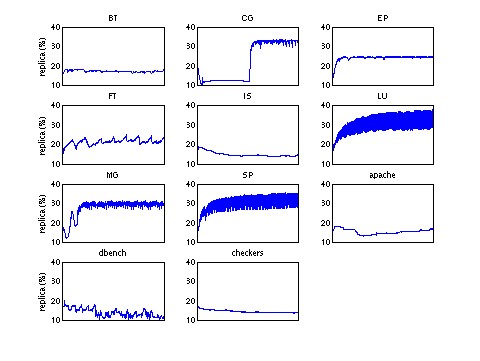 |
| Figure 4: Access latencies of multi-threaded programs. | Figure 5: Time-Varying graph showing percentage
of L2 allocated to replicas in multi-threaded programs. Average of all caches is shown. |
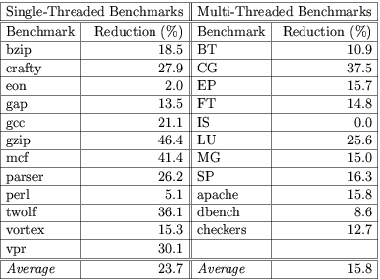
Table 1: Reduction in memory access latency for L2VR over L2S.
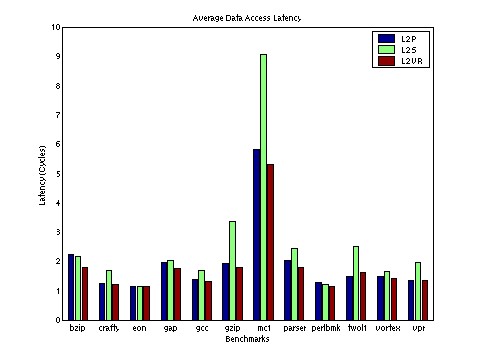
Single-threaded Benchmark Results: Single-threaded code is an important special case for a tiled CMP. The L2VR policy dynamically adapts to a single thread by forming a three-level cache hierarchy: the primary cache, the local L2 slice full of replicas, and the remote L2 slices acting as an L3 cache. This behavior is shown in Figure 7, which plots the time-varying graph of the percentage of replicas in each of the eight individual L2 caches. Because we are performing a full-system simulation, we sometimes observe the single thread moving between CPUs under the control of the operating system scheduler. For benchmarks bzip, gap, parser, and perlbmk, one tile held the thread most of the time. For benchmarks crafty, eon, gzip, twolf, and vpr, the thread seems to bounce between two tiles. We did not attempt to optimize the kernel scheduler to pin the thread on one tile throughout the run. Across the benchmarks, the L2 slice of the tile on which the thread is running holds a very high percentage of replicas, usually over 50%. Figure 6 shows the memory access latencies for the single-threaded benchmarks. In many cases, L2S performs significantly worse than the other schemes, because L2 hit latency is a critical component of performance for these codes. Table 1 summarizes the savings. Nine out of the twelve benchmarks achieved 15% or more savings, with six of them over 25%, and an average of 24%. L2VR is usually comparable or better than the L2P scheme, combining the advantages of fast accesses to the local L2 slice with a large on-chip backup cache.
 |
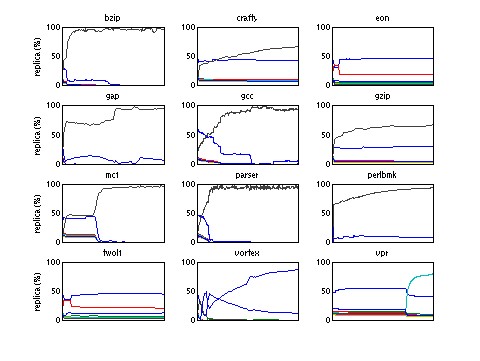 |
| Figure 6: Access latencies of single-threaded programs. | Figure 7: Time-Varying graph showing percentage
of L2 allocated to replicas in single-threaded programs. Individual caches are shown. |
Research Support
This work is partly funded by the DARPA HPCS/IBM PERCS project and NSF CAREER Award CCR-0093354.
References:
[1] Michael Zhang and Krste Asanovic. Victim Replication: Maximizing Capacity while Hiding Wire Delay in Tiled Chip Multiprocessors. In 32nd International Symposium on Computer Architecture, Madison, Wisconsin, June 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |