
Video Matching
Peter Sand & Seth Teller
Given multiple still images of a scene from the same camera center, one can perform a variety of image analysis and synthesis tasks, such as foreground/background segmentation, copying an object or person from one image to another, building mosaics of the scene, and constructing high dynamic range composites.
Our goal is to extend these techniques to video footage acquired with a moving camera. Given two video sequences (recorded at separate times), we seek to spatially and temporally align the frames such that subsequent image processing can be performed on the aligned images. We assume that the input videos follow nearly identical trajectories through space, but we allow them to have different timing. The output of our algorithm is a new sequence in which each "frame" consists of a pair of registered images. The algorithm provides an alternative to the expensive and cumbersome robotic motion control systems that would normally be used to ensure registration of multiple video sequences.
The primary difficulty in this task is matching images that have substantially different appearances (Figure 1). Video sequences of the same scene may differ from one another due to moving people, changes in lighting, and/or different exposure settings. In order to obtain good alignment, our algorithm must make use of as much image information as possible, without being misled by image regions that match poorly.
Traditional methods for aligning images include feature matching and optical flow. Feature matching algorithms find a pairing of feature points from one image to another, but they do not give a dense pixel correspondence. Optical flow produces a dense pixel correspondence, but is not robust to objects present in one image but not the other.
Our method combines elements of feature matching and optical flow. In a given image, the algorithm identifies a set of textured image patches to be matched with patches in the other image (Figures 2 and 3). Once a set of initial matches has been found, we use these matches as motion evidence for a regression model that estimates dense pixel correspondences across the entire image. These estimates allow further matches to be discovered and refined using local optical flow. Throughout the process, we estimate and utilize probabilistic weights for each correspondence, allowing the algorithm to detect and discard (or fix) mismatches.
Our primary contribution is a method for spatially and temporally aligning videos using image comparisons. Our image comparison method is also novel, insofar as it is explicitly designed to handle large-scale differences between the images. The main limitation of our approach is that we require the input videos to follow spatially similar camera trajectories. The algorithm cannot align images from substantially different viewpoints, partially because it does not model occlusion boundaries. Nonetheless, we demonstrate a variety of applications for which our method is useful (Figures 4 and 5).
References:
[1] Peter Sand and Seth Teller. 2004. Video Matching. ACM Transactions on Graphics (TOG) 22, 3, 592-599.
 |
| Figure 1: Our matching algorithm is robust to differences such as an object that appears in only one image (left pair) or changes in lighting and exposure (right pair). The key idea behind our matching algorithm is to identify which parts of the image can be matched (blue arrows) without being confused by parts of the image that are difficult or impossible to match (yellow arrows). |
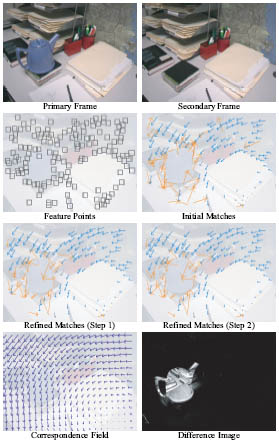 |
| Figure 2: The image matching algorithm typically converges in a few iterations. The blue and yellow arrows denote high and low probability correspondences, respectively. The algorithm successfully recognizes that the teapot pixels cannot be matched with the background. The reconstructed dense correspondences are quite accurate, as illustrated by the difference between the primary frame and the warped secondary frame. The black regions in the difference image indicate that the background pixels are successfully matched (with a pixel difference near zero). |
 |
| Figure 3: These frames were selected by the video matching algorithm from a pair of videos recorded at different exposures. The algorithm first performs local brightness/contrast normalization, then finds high-likelihood correspondences. Once the secondary frame has been mapped to the first, the exposures are combined to create a high dynamic range composite. |
 |
| Figure 4: The top images have been registered using the robust matching algorithm. From these images we can use simple image processing methods (background subtraction and color thresholds) to create a mask for the wire (in red). Inside the mask, we copy pixels from the background. This allows a wire to be automatically removed in each frame of a long sequence from a moving camera. |
 |
| Figure 5: This figure shows primary frames (a), secondary frames (b), and various composites (c). From left to right: (1) a transparent fan created by blending the two frames, (2) color manipulated according to a difference matte, (3) cloning a person by compositing the left half of one image with right half of another, (4) changing the amount of orange juice using a horizontal compositing line, and (5) a dismembered hand with a key-framed compositing line. None of the composites require per-frame manual rotoscoping. |