
Robust Distributed Coordination Of Heterogeneous Robots Through Temporal Plan Networks
Stephen A. Block & Brian C. Williams
Motivation
The ability to command coordinated groups of autonomous agents is key to many real-world tasks. For example, several manipulators constructing a Lunar habitat, or a group of Mars rovers searching for rock samples. Dependable systems must plan and carry out activities in a way that is robust to failure and to uncertainty.

Previous Work
Methods have been developed for the dynamic execution [4] of temporally flexible plans [1]. These methods adapt to failures that fall within the margins of the temporally flexible plans and hence add robustness to execution uncertainties.
To address plan failure, we introduced a system called Kirk [2], that performs dynamic execution of temporally flexible plans with contingencies. These contingent plans are encoded as alternative choices between functionally equivalent sub-plans. In Kirk, the contingent plans are represented by a Temporal Plan Network (TPN) [2], which extends temporally flexible plans with a nested choose operator. A TPN is built from a group of activities and is defined recursively using the choose, parallel and sequence operators, which derive from the Reactive Model-based Programming Language (RMPL) [8]. To dynamically execute a TPN, Kirk continuously extracts a plan from the TPN that is temporally feasible, given the execution history. This provides a capability to deal with plan failure and hence adds robustness at the planning phase.
Kirk uses a centralized architecture in which all computation is performed by a single processor. This approach requires significant computational capabilities, introduces a single point of failure, does not scale well, and suffers from communication a bottleneck. Therefore, in order to robustly command groups of autonomous agents, we must perform robust execution of contingent, temporally flexible plans in a distributed manner.
Overview
We are developing a distributed version of Kirk, which provides an executive for the robust execution of contingent plans. The first component of the executive is our Distributed Temporal Planner (DTP) [9], which dynamically selects a temporally feasible plan from a TPN. DTP consists of the following three stages.
- The TPN is distributed over multiple agents, by creating a hierarchical ad-hoc network and mapping the TPN onto this hierarchy.
- Candidate plans are extracted from the TPN with a distributed, parallel algorithm that exploits the structure of the TPN.
- Temporal consistency of the candidate plans is tested using a distributed Bellman-Ford algorithm.
Prior to dispatching, we restructure the selected plan to permit execution in the face of limited communication. Each portion of the plan in which tight coordination exists and where agents are able to communicate freely is clustered to form a group plan. Conversely, agents may not be able to reliably communicate with those outside their group, but the coordination between group plans is looser. This isolates the problem of limited communication to that of dealing with inter-group communication. Given this two layer plan structure, our Hierarchical Reformulation algorithm [6] compiles the temporal constraints of the plan such that temporal constraints between group plans are scheduled statically, removing the need for communication at execution time, while allowing the activities within each group plan to be scheduled dynamically.
The final component of the distributed executive is the distributed dispatcher, which is the current focus of our work. We leverage off of existing methods for fast reformulation [7] used to prepare the plan for dispatching, and for executing the activities in the plan [4]. Our innovation is a completely distributed dispatcher which allows significant parallel computation. This is made possible by exploiting the hierarchical processor network and corresponding TPN structure established by DTP.
Problem Statement and Example
Given a TPN to be executed by a group of agents, the distributed executive must execute the TPN in a way that is robust to communication limitations and execution uncertainties, all in a fully distributed manner. An example TPN is represented as a graph in Fig. 1, where nodes represent points in time and arcs represent activities. A node at which multiple choices exist for the following path through the TPN is a choice node and is shown as an inscribed circle.
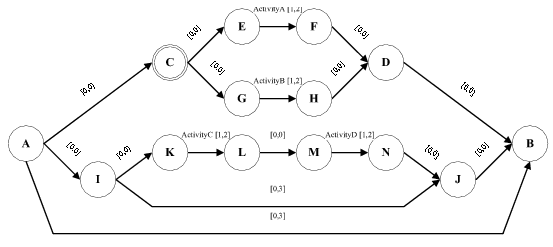
Figure 1 : TPN Example
The TPN is to be executed by a group of seven processors, p1, ..., p7. First, DTP distributes the TPN over the processors to allow the plan selection to take place in a distributed fashion. To facilitate this, a leader election algorithm [5] is used to arrange the processors into a hierarchy, shown in Figure 2. The hierarchical structure of the TPN is then used to map subnetworks to processors. For example, the head processor p1 handles the merging of multiple branches of the plan at the start node (node A) and the end node (node B). It passes responsibility for each of the two main subnetworks to the two processors immediately beneath it in the hierarchy. Nodes C,D,E,F,G,H are passed to p2 and nodes I,J,K,L,M,N are passed to p3. DTP then runs on all processors simultaneously, such that a temporally consistent plan from the TPN is extracted in a distributed, highly parallel manner.
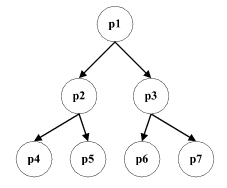
Figure 2 : A three-level hierarchy formed by leader election
Fast Reformulation
The output of the reformulation step is a minimal dispatchable network, which presents the plan so as to minimize the processing required by the dispatcher to ensure successful execution. A dispatchable graph has all temporal constraints exposed, such that only local propagation of execution times is required during dispatching. An All Pairs Shortest Path (APSP) graph of the input TPN is dispatchable, but contains many redundant edges which will cause a loss of efficiency during propagation. A minimal dispatchable graph contains the minimum number of edges required to represent the dispatchable network. Reformulation, therefore, consists of two basic steps: calculation of the APSP distances followed by trimming of redundant edges.
Calculation of the entire APSP graph, followed immediately by trimming of many of its edges, is inefficient. The storage requirements of the APSP graph are large and the edge trimming operation is time consuming. The fast reformulation algorithm interleaves the APSP calculation with the edge trimming operation, thereby avoiding the need to generate the entire APSP graph and the associated explosion in storage and processing requirements. In order to calculate the APSP graph the fast reformulation algorithm uses the distributed Bellman-Ford algorithm [3] to calculate the Single Source Shortest Path distances from each node in turn. Edge trimming is performed by traversing the nodes in reverse post-order and applying a local dominance test at each, allowing the non-redundant edges to be found without search. It is this insight that allows the edge trimming to be performed efficiently.
For the reverse post-order traversal method to succeed, we must extract all rigid components from the plan. A rigid component is a set of nodes who's execution times are exactly fixed with respect to each other. They are extracted by representing each rigid component as a single leader node for the purposes of reformulation. Rigid components appear as strongly connected components in the predecessor graph and can be found by a reverse post-order search on the transposed predecessor graph. When a rigid component is extracted from the plan, all edges to its member nodes are re-routed to its leader. This process depends on edge dominance tests that require the rigid component to be free of zero-related nodes, that is, nodes which must be executed simultaneously. Zero related nodes are therefore merged during the detection phase of rigid component extraction.
The major challenge in developing a distributed dispatcher is to develop an efficient message passing scheme to collapse zero related nodes and to extract rigid components, so that the edge trimming procedure can be performed efficiently. Such a scheme is currently under development.
References
[1] R. Dechter, I. Meiri and J. Pearl. Temporal constraint networks. In Artificial Intelligence, pp. 49:61-95, 1991.
[2] P. Kim, B. Williams and M. Abramson. Executing reactive, model-based programs through graph-based temporal planning. In Proc. of IJCAI 2001, Seattle, WA, 2001.
[3] N. Lynch. Distributed Algorithms. Morgan Kaufmann, 1997.
[4] P. Morris N. Muscettola. Execution of temporal plans with uncertainty. In AAAI-00, 2000.
[5] R. Nagpal and D. Coore. An algorithm for group formation in an amorphous computer. In Proc. of PDCS, Las Vegas, NV, 1998.
[6] J. Stedl. A formal model of tight and loose team coordination. Masters thesis, MIT, Cambridge, MA, September 2004.
[7] I. Tsamardinos, N. Muscettola and P. Morris. Fast transformation of temporal plans for efficient execution. In AAAI-98, 1998.
[8] B. Williams, M. Ingham, S. Chung and P. Elliott. Model-based programming of intelligent embedded systems and robotic explorers. In IEEE Proceedings, Special Issue on Embedded Software, 2003.
[9] A. Wehowsky. Safe Distributed Coordination of Heterogeneous Robots through Dynamic Simple Temporal Networks. Masters thesis, MIT, Cambridge, MA, May 2003.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |