
Learning Subtask Goal to Improve Motion Planning
Sarah Finney, Tomas Lozano-Perez & Leslie Pack Kaelbling
Introduction
Robot motion planning has long been studied as a way to create autonomous agents that can generate low-level motor commands from a high-level description of a task ([1], [2]). Motion planning is particularly important and challenging when the agent has a large number of degrees of freedom to control. There is strong evidence that the time required to solve motion planning problems exactly grows exponentially with the number of the agent's degrees of freedom. Even assuming that the environment is completely known, and that it does not change appreciably over time, motion planning for many degrees of freedom is a hard problem, and solving it often takes more time than is available for an agent acting in the world. If the problem is further compounded by the fact that the state of the environment may change while planning takes place, or that the environment may be only partially or imperfectly sensed, the problem becomes harder to solve with slow planning solutions. If we can speed up the planning process, we could hope to plan repeatedly as we observe changes in or new information about the environment.
Since it is known that complete motion planning solutions are hard to find ([3], [4]), we would like to find aspects of the particular problems that we want to solve that give leverage in speeding up the planning process without overly compromising the resulting planning output. We hope to find such leverage along two different axes, which we hope will operate in concert. First, we believe that many of the tasks that we might wish to accomplish with robots do not require the simultaneous use of all of the robot's degrees of freedom. Secondly, we believe that while previous motion planning experience cannot for the most part be directly applied to a novel environment or task, it should be possible to use that previous experience to speed up the planning process.
Progress
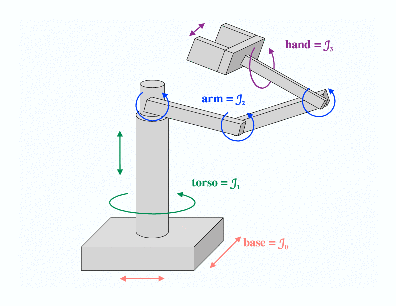
Thus far in the project, we have focused primarily on trying to take advantage of previous planning experience to speed up the planning process in a novel environment. We are currently exploring two parallel approaches. For both approaches we make use of the Motion Planning Kit ([5], shown at right) provided by Latombe's research group at Stanford.
In the first approach, whole successful paths are generated by the planner and stored, along with a bit vector that represents the volume swept out by the agent in performing the plan. This bit vector can be used to quickly evaluate whether a new environment has obstacles that intrude upon the path. Thus, the memory can be used to generate configurations that are very likely collision free and connected to one another in the new environment. If the previous path covers ground along the path between the new start and goal configurations, it is then useful in generating a successful plan more quickly than if we were to plan from scratch. This second approach has met with some success, but we still have several important questions to address before we can feel confident that the approach is useful.
The second approach is one in which we endeavor to learn a function from a description of an environment and a task to a suggested way point. A good way point is one that causes the agent to make progress toward the goal and that can be reached from the agent's current configuration using a simple linear joint controller. The training data for the algorithm is generated by using the planner to find a good path, and then using each configuration on that path as a training point. This learning problem is made particularly difficult by the fact that there is often more than one possible solution. A simple example makes the difficulty clear. Consider a robot that needs to go around an obstacle that is directly between the agent and the goal. Good plans include going left and going right, but going straight ahead causes a collision. If a randomized planner generates several plans for this scenario, some will go left and others right. A function approximation algorithm, given all these points, will likely converge on a forward motion, which is no good. We have not yet found a successful way for solving this problem.
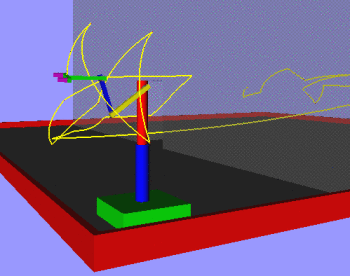
We have also done preliminary work on the issue of decomposing a planning problem into several subproblems, each of which requires planning for only a small subset of the total number of degrees of freedom that the agent has. We have performed simple experiments with a simulated robot as shown in the picture to the left. We have divided the degrees of freedom into four subgroups as shown. We then specify the order in which particular subgroups are allowed to move, and then apply the planner to each stage of the decomposed motion. So far we have seen in an informal way that for particular types of planning problems, the decomposed problems can be solved faster than the original problem. A complete understanding of the limitations of this restriction is yet to be reached.
Future Work
There are obviously many avenues for future work in this research. The most immediate involve pushing ahead with the two learning approaches we have already begun. In our first approach, our next step is to carefully consider the tradeoffs involved in various types of off-line processing that we might do on our stored memory of previous successful paths. Some possibilities include merging multiple paths so that a larger portion of the collision-free road map is available to help the planner find a plan in the new environment. The obvious trade-off here is that this new conglomerate path will be applicable in fewer new environments, since it requires more obstacle-free space.
Clearly another important issue is how to compress our memory so that we don't run out of space. This could be done by trying to get rid of infrequently used paths, or by finding a way to represent several similar paths by one canonical path. Both of these notions risk removing potentially useful information from our memory, and so must be considered carefully. Lastly, we need to address the issue of how to store instances in our memory so that they can be retrieved easily. This aspect is key to applying our improvements to planning problems of any real size, but hopefully such an improvement would not alter the effectiveness of the planning.
In our second approach, we hope to make progress in finding a learning algorithm that is capable of dealing with the issue of multiple valid answers. Most function approximation algorithms will converge to something like an average of the training data it has seen, which for our problem could be a very bad answer.
The next step in the study of planning decomposition is to understand more precisely the way in which enforcing the structure of the decomposition effects the problems the agent can solve. If we conclude this it is a valuable tradeoff, then we must address the question of how to generalize these decomposed plans for new tasks, as well as how to arrive at a useful decomposition and subproblem ordering for a particular robot platform and task.
References
[1] J. C. Latombe. Robot Motion Planning. Kluwer Academic Publishers. 1991
[2] S. M. Lavalle. Planning Algorithms. [Online]. available here.
[3] J. Reif. Complexity of the Mover's Problem and Generalizations. In Proceedings of 20th IEEE Symposium of the Foundations of Computer Science. pp. 421-427.
[4] J. Canny. The Complexity of Robot Motion Planning. MIT Press. 1988
[5] G. Sanchez & J. C. Latombe. A Single-Query Bi-Directional Probabilistic Roadmap Planner with Lazy Collision Checking. In Int. Symposium on Robotics Research (ISRR '01). Lorne, Victoria, Australia, November 2001.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |