
Nondeterminator-3: A Provably Good Data-Race Detector Which Runs in Parallel
Tushara C. Karunaratna
Introduction
This project deals with the implementation of a provably good data-race detector, called the Nondeterminator-3, which runs efficiently in parallel. A data-race occurs in a multithreaded program when two logically parallel threads access the same location while holding no common locks and at least one of the accesses is a write. The Nondeterminator-3 checks for data-races "on the fly", in programs coded in Cilk [2, 3], a shared-memory multithreaded programming language.
The Nondeterminator-3 succeeds the serially running Nondeterminator-2 [5]. Although data-race detectors are only debugging tools, there are many reasons for building an efficient parallel data-race detector. Firstly, a parallel data-race detector would enable faster debugging of races in parallel programs. An on-the-fly data-race detector that preserves the parallelism of an application program would enable the program to be run with race detection options always turned on; a serially-running data-race detector, on the other hand, would not enable such real-time testing. The Nondeterminator-3 implementation also helps in demonstrating the possibility of using the underlying theoretical ideas to obtain a data-race detector that achieves good speed-up in practice.
Main Components of the Program
A key capability needed by the Nondeterminator-3 is the ability to determine
the series-parallel (SP) relationship between two threads. The Nondeterminator-3
is based on a provably good parallel SP-maintenance algorithm known as
SP-hybrid [1]. For a program with 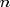 threads,
threads, 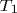 work, and critical-path length
work, and critical-path length 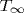 , the SP-hybrid algorithm runs in
, the SP-hybrid algorithm runs in 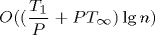 expected time when executed on
expected time when executed on 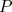 processors.
processors.
The SP-hybrid algorithm uses a two-tiered hierarchy with a shared (global) top tier and a local bottom tier. As a computation is executed, SP-hybrid decomposes it into "subcomputations" on the fly. Each subcomputation is executed serially on a single processor. The top tier uses the technique of English-Hebrew labelling [7], together with an order-maintenance data structure [6], to maintain the SP-relationships between threads belonging to different subcomputations. The bottom tier uses Feng and Leiserson's SP-bags [4] algorithm to maintain the relationship between threads belonging to the same subcomputation.
The Nondeterminator-3 also maintains an access-history, which consists of, for each shared memory location, a representative subset of memory accesses to that location. We use a parallelization of the ALL-SETS access-history algorithm used by the Nondeterminator-2. Assuming that the cost of locking the access-history locations can be ignored, the parallelization does not change the worst-case blow-up of the memory access cost.
Progress and Future work
I have an end-to-end implementation of the Nondeterminator-3. Its correctness has been tested by running it on several example programs. I plan to improve the current implementation and to do more extensive testing.
I plan to obtain accurate performance measurements by using perfctr, a driver for interfacing to the performance-monitoring counters found in many modern processors, in order to demonstrate that the Nondeterminator-3 achieves good speed-up in practice.
Acknowledgments
Thanks to Jeremy Fineman, Charles Leiserson, and other members of the CSAIL Supercomputing Technologies Group, for their guidance and advice.
Research Support
This research was supported in part by the Singapore-MIT Alliance, by NSF Grant ACI-0324974, and by NSF Grant CNS-0305606.
References:
[1] Michael A. Bender, Jeremy T. Fineman, Seth Gilbert, and Charles E. Leiserson. On-the-Fly Maintenance of Series-Parallel Relationships in Fork-Join Multithreaded Programs. In Proceedings of the Sixteenth Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA), Barcelona, Spain, June 27-30, 2004.
[2] Robert D. Blumofe and Charles E. Leiserson. Scheduling multithreaded computations by work stealing. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science (FOCS), pages 356-368, Santa Fe, New Mexico, November 1994.
[3] Matteo Frigo, Charles E. Leiserson, and Keith H. Randall. The implementation of the Cilk-5 multithreaded language. In Proceedings of the ACM SIGPLAN 1998 conference on Programming language design and implementation, pages 212-223. ACM Press, 1998.
[4] Mingdong Feng and Charles E. Leiserson. Efficient detection of determinacy races in Cilk programs. In Proceedings of the Ninth Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA), pages 1-11, Newport,Rhode Island, June 1997.
[5] Guang-Ien Cheng, Mingdong Feng, Charles E. Leiserson, Keith H. Randall, and Andrew F. Stark. Detecting Data Races in Cilk Programs that Use Locks. In Proceedings of the Tenth Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA '98), pages 298-309, Puerto Vallarta, Mexico, June 28 - July 2, 1998.
[6] Michael A. Bender, Richard Cole, Erik D. Demaine, Martin Farach-Colton, and Jack Zito. Two simplified algorithms for maintaining order in a list. In Proceedings of the 10th European Symposium on Algorithms (ESA), pages 152-164, 2002.
[7] Itzhak Nudler and Larry Rudolph. Tools for the efficient development of efficient parallel programs. In Proceedings of the First Israeli Conference on Computer Systems Engineering, May 1986.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |