|
The Intelligent Book
H. Abelson, C. Hanson, G.J. Sussman
in collaboration with
W. Billinsgley, K. Rehman, P. Robinson (University of
Cambridge)
People generally use the Web to access passive information. Educational
materials on the Web are generally fixed presentations of predetermined
content. Intelligent books are different, because the information they
present is only partly composed by the authors: most of an intelligent
book is dynamically constructed and accumulated through conversations
with its readers. More concretely, an intelligent book understands the
principles and strategies of the subject matter, and uses those to answer
questions, to fill in details, and to accumulate new examples as suggested
by the conversations with its readers.
An intelligent book has several components:
- Content presentation (including graphics and other media),
as one would expect in an actual Web-based book, together with appropriate
user interfaces.
- The content presentation is backed up by a modelling
system. In an intelligent book on circuit theory, for example, all the
diagrams and equations would be active, with the equations linked to
an algebraic manipulator and the diagrams linked to symbolic and numeric
simulators. Thus, a student could point to any node on a circuit diagram
and ask for the voltage at that node in symbolic form.
- The modelling system is backed up by a simple reasoning
and deductive system that uses constraint propagation and dependency-directed
backtracking in order to make simple deductions and explain its deductions.
For example, a student could point to a node on a circuit and ask the
book to explain why the voltage is what it is; or point to an equation
and ask the book to explain its derivation.
- Integrated into the book are techniques for assessing
a reader's progress and forming simple assessment. For example, the
same underlying modelling and reasoning components that are used to
explain the derivation of an equation, can be used to check a student's
derivation of the equation, and offer hints to students who are stuck.
- All of this is incorporated into a framework for automatically
improving the books' presentation, based on "learning" from large numbers
of users accessing the book via the Web. One aspect of this is the ability
for the book to learn new examples, based on questions and suggestions
from users. Another is increasing reliability of the assessment, based
on aggregating the behaviour of large numbers of users.
In our work so far, we have concentrated on examples from digital
electronics and discrete mathematics at Cambridge, and transistor
circuits at MIT. The MIT materials have been tested in experimental
versions of the introductory electronic subject, which uses circuit
models backed up by constraint propagation and truth maintenance systems
to guide students through problems in amplifier design.
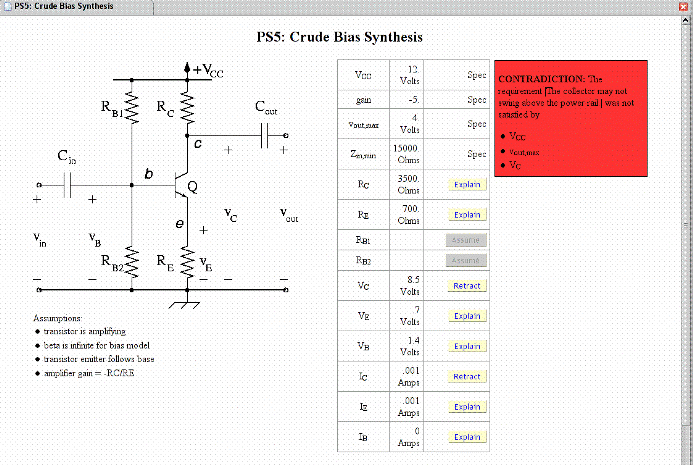
In the figure below, a student is attempting to synthesize an amplifier,
using a heuristic "crude bias model" to deduce value for the components.
At the point shown in the figure, the student's proposed design violates
the given specifications for the amplifier, and the system signals
this as a contradiction.
This work is funded by the Cambridge-MIT Institute.
|
|
