| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Machine Understanding of Narrated Guided ToursAlbert S. Huang & Seth Teller
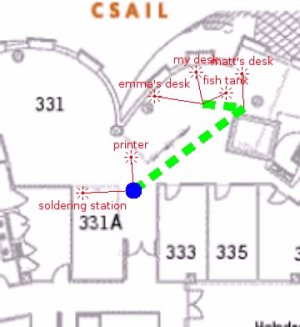
AbstractA standard way to introduce a person to a new physical environment is to give a guided tour, gesturing towards objects and points of interest while simultaneously providing verbal descriptions. Being able to introduce a robot or computational device to the same space in the same manner has numerous applications in areas where such devices maintain close interaction with people. To explore this possibility, we have constructed a sensory platform consisting of an omnidirectional camera, inertial sensors, and a microphone. This paper presents the motivation, design, and ideas underlying the Ladypack sensor platform. IntroductionWhen one arrives at a new, unfamiliar environment, it is typical for someone already familiar with the surroundings to give a brief, guided tour. This tour may consist of walking around while gesturing at and verbally describing objects and points of interest (e.g. "This is the meeting room", "This is your desk", etc.) During the course of the tour, one acquires a mental representation of the physical geometry of the space, along with semantic labels for specific locations. In the future, this information is used to navigate the space and interact with others. Being able to introduce a robot or computational device to a new environment in the same way, while at the same time conveying the same or a similar amount of geometric and semantic information, opens up a number of possibilities in areas where the device maintains close interaction with people. For example, interaction with a robotic courier could be as simple as, "Bring this to the radiology lab". A robotic vacuum cleaner could be told to "Go vacuum the kitchen." Device logs could be searched with natural language queries such as, "Where are my keys?" Maintaining and updating the device's representation and semantic labels can also be as simple as giving a short tour lasting a few seconds long. We propose that recent advances in speech recognition, simultaneous localization and mapping, and machine vision have made it feasible to approach this problem. To do so, we have constructed a sensor platform containing a variety of sensors designed to record a tour guide's movements, gestures, and verbal utterances made during the course of a narrated tour. Figure 1 shows a sample image from the sensor platform alongside a diagram of what the system might produce after a guided tour. DesignIn our system, there are three primary sensors - a Ladybug 2 spherical camera, an inertial measurement unit (IMU), and a microphone. The spherical camera is attached to the tour guide's chest and effectively captures everything in the guide's field of view. The IMU is rigidly attached to the spherical camera to assist in egomotion estimation, while the microphone captures the guide's verbal utterances. Additionally, a handheld laser range finder with a second, rigidly attached IMU is used to point out objects of interest. A laptop computer, mounted on a backpack, is used to synchronize and record all the data streams to a hard disk. We have named the platform, shown in figure 2, the Ladypack, after its most prominent sensor. To give a tour, a user walks around while wearing the Ladypack. Objects of interest are pointed to using the laser range finder, and a limited domain vocabulary is used to verbally describe them. The laser dot is used to precisely identify the object pointed to by the user. We emphasize that the form factor of the Ladypack is a consequence of available technology, and that a wearable design was found to be the most convenient and inexpensive method of integrating all the sensors into a portable platform. While the system may have applications in wearable computing, its primary purpose is to collect data sets suitable for analysis in the context of machine understanding of narrated tours.
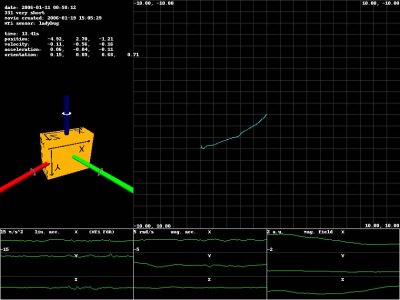
Prior workOur approach relies upon combining continuously developing techniques in simultaneous localization and mapping [3], scene understanding [7], speech recognition [4], and object recognition [6]. While mobile robotic assistants and location aware devices have been effectively deployed for decades [2, 5], the maps and semantic labels used by these robots are typically entered by a skilled operator and are difficult, if not impossible, for a casual user to modify. StrategyDuring the tour, the user is restricted to a limited domain grammar consisting of simple utterances such as, "This is X" and "Here is Y". These utterances are used in conjunction with the video stream and laser range finder to associate semantic labels with visually distinctive features. Extracted features are stored in a database for future indexing and retrieval. Optical flow and the IMU attached to the camera are used to obtain a rough estimate of the camera motion. Constraints on camera motion are introduced with verbal utterances (e.g. "We're back at X") and visually distinctive features. The camera trajectory is then optimized with a non-linear optimization algorithm [3] to produce a globally consistent estimate of the path taken. ProgressA first version of the Ladypack platform and data collection software has been completed. As shown in Figure 3, implementation of data analysis software has begun and initial results are promising.
References[1] A. Brusss and B. K. Korn, Passive navigation. Computer Graphics and Image Processing, 21:3--20, 1983. [2] W. Burgard and A. B. Cremers and D. Fox and D. Hahnel and G. Lakemeyer and D. Schulz and W. Steiner and S. Thrun. Experiences with an interactive museum tour-guide robot. Artificial Intelligence, 114, pp. 3--55, 1999 [3] Edwin Olson and John Leonard and Seth Teller. Fast iterative alignment of pose graphs with poor initial estimates. To appear, Proceedings of the International Conference on Robotics and Automation. Orlanda, FL, 2006 [4] Jim Glass and Eugene Weinstein. SPEECHBUILDER: Facilitating Spoken Dialogue System Development. Proc. European Conference on Speech Communication and Technology, pp. 1335--1339. Aalborg, Denmark, 2001. [5] S. King and C. Weiman. Helpmate autonomous mobile robot navigation system. Proceedings of the SPIE Conference on Mobile Robots, pp. 190--198, Boston, MA, 1990. [6] David G. Lowe. Object recognition from local scale-invariant features. Proc. of the International Conference on Computer Vision ICCV, Corfu, pp. 1150--1157, 1999 [7] A. Oliva and A. B. Torralba, Modeling the shape of the scene: A holistic representation of the spatial envelope. International Journal of Computer Vision, 42, pp. 145--175, 2001 |
||||||||||||||
|
|||||||||||||||