
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
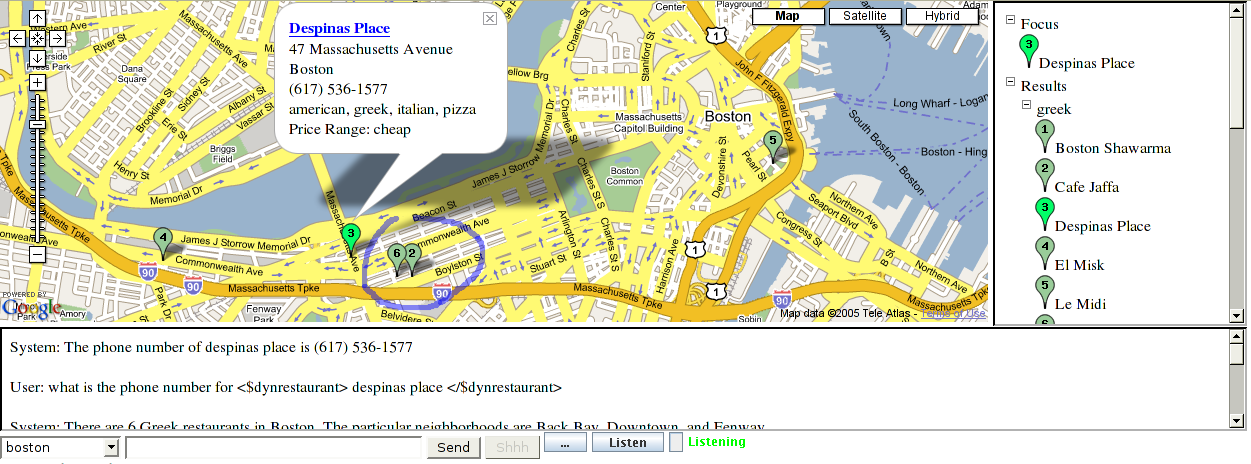
Web-Based Multimodal Dialogue SystemsAlexander Gruenstein & Stephanie SeneffIntroductionWe are developing a generic infrastructure for rapidly building web-based multimodal dialogue systems for database access. We focus on the portability and scalability of such systems in the context of databases containing geographical content; as our example application in this domain, we build a map-based spoken dialogue system for accessing restaurant information. In previous research, we have shown progress with regard to the portability of dialogue management [1], and we have shown how cross-domain fertilization and simulation can create portable language models [2,3]. In this abstract, we focus on techniques for building a generic web-interface, and for dealing with "messy" databases which must be adapted for use with speech. Figure 1 shows a screenshot of the multimodal interface, while figure 2 shows an example dialogue with the system. Videos highlighting the capabilities of the system may be viewed here. Preparing the DatabaseWe harvest the data for the system by crawling web-based restaurant databases. Currently, we have data for seven major metropolitan areas in the United States: Austin, Boston, Chicago, Los Angeles, San Francisco, Seattle, and Washington D.C. We are in the process of acquiring more data using a custom-built web spider. After the data are downloaded, processing leads to a vocabulary of proper nouns for the speech recognizer, and a structured database which can be used to filter user queries. This process consists of using contextualized rules from a configuration file to convert abbreviations such as "pzzr" into "pizzeria" and create aliases such as "steves" for "steves restaurant." Most of the clean-up is generic and can be applied to all cities; for any exceptions that might arise the configuration file may be tweaked. Both actions are necessary in order for the system to be naturally accessible via speech and for the speech synthesizer to function properly. Finally, a rather sophisticated processing step takes place in which any natural language which must be parsed is turned into a structured representation. In this application, this involves processing any information about the opening hours of each restaurants gleaned from the web. A context free grammar is used to turn this free-form text into a structured meaning representation, allowing the system to answer questions such as "Are they open for dinner on Monday?". Using natural language generation rules, answers to these questions may be fluently formulated. System ArchitectureThe overall system architecture is depicted in figure 3. The user interface is presented on a dynamic web page. The client sends speech, typed, and gesture inputs to the server, where dialogue processing occurs. The client plays synthesized speech and displays database query results sent to it from the backend. The dialogue processing architecture on the server side is configured via the Galaxy architecture [7]. GUI and Audio Front End A screenshot of the GUI appears in figure 1. It is implemented as a dynamic web page, whose interaction
with the web server is moderated by the GUI Controller Servlet. A Java
applet embedded in the page provides a push-to-talk button and endpointing,
and streams recorded speech and synthesized audio across the network.
The GUI can display any type of geographically situated entity, and as
such serves as a generic map-based front-end. The user can draw on the
map while speaking, which makes multimodal commands such as those shown
in figure 2 possible. Visible entities
may be circled, as in Speech Recognition:The SUMMIT system, specifically the version in [4] which allows for the
dynamic manipulation of language models, is used. The Language Understanding and Language Modeling:For language understanding we utilize a lexicalized stochastic syntax-based
context free grammar, specialized for database query applications. The
recognizer's class Multimodal Context Resolution:All entities introduced into the discourse either verbally (by the user or by the system) or through gesture are added to a common discourse entity list. A heuristic algorithm described in [11] resolves plausible anaphors for deictic, pronominal, and definite NP's. Response Planning and Generation:A generic dialogue manager [1] filters the database based on user-supplied constraints and prepares a reply frame encoding the system's intended response, which is then converted to a surface-form string using the Genesis generation system [12] and finally to a synthesized waveform using a commercial speech synthesizer. A separate multimodal reply frame is converted to XML by Genesis to update the set of entities shown on the GUI.
References:
|
||||
|

![\includegraphics[width=.4\textwidth]{diagram}](diagram.png)