| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
SVM Learning of IP Address Structure for Latency PredictionRobert Beverly & Karen SollinsIP Address Structure as a Basis for LearningThe hierarchical structure of the Internet and address allocation policies [1] provide locality to IP addresses. Is it possible for agents to exploit the IP address structure in order to predict network properties? In this research, we cast the problem of predicting round-trip network latency to an IP destination as an application of machine learning. IP addresses must be globally unique and are therefore assigned by regional registries governed by a central body, the Internet Assigned Numbers Authority (IANA). Wherever possible, addresses are delegated in a semi-organized and hierarchical fashion with the intention that networks, organizations and geographic regions receive contiguous blocks of IP address space. Contiguous allocations permit aggregation of routing announcements, preserving router memory and BGP convergence time. While the IP address space maintains hierarchy and structure, it has evolved organically over time. As a result it is discontinuous, variable and fragmented as evidenced by the approximately 250,000 BGP entries in the global routing table. A central question first explored in [2] is where in the network, if at all, intelligence should be placed. In this work, we consider end-nodes as intelligent participants in the network, through learning, prediction and classification. This research has the potential to equip a variety of network architectures with intelligence including service selection, user-directed routing, resource scheduling and network measurement. Our preliminary results reveal:
MethodologyWe hypothesize that agents can exploit the Internet's inherent IP address locality to their advantage. An agent in the network can be any device that is attempting to make decisions based upon previous interactions with the network. An initial experiment we preform is agent prediction of round-trip network latency to random destinations. The implication of the semi-structured IP address space on learning latency is that while we may expect all machines in a particular subnetwork to be within a tight bound, there may be a another subnetwork with an identical bound that is not numerically adjacent in the IP space. For example, assume that from Alice's perspective the latency to both Bob and Charlie is 10ms, however they reside on different, numerically distant, networks. Further, Dean may have an IP address numerically between Bob and Charlie, yet Alice's latency to Dean is 200ms. Because of this discontinuity, we turn to kernel functions to transform the input IP space into a higher dimensional feature space where a separating hyper-plane may exist. To collect data for our experiments, we use a simple active measurement procedure. We select unsigned 32-bit integers at random until one is found as a valid IP address in a public global routing table. If the randomly selected destination responds to ICMP echo requests, i.e. "ping," we record the average of five ping times from our measurement host as the round-trip latency. Our data set consists of 10,000 randomly selected (IP,Latency) pairs. The probability distribution of latencies is non-trivial, with multiple modes and a long tail, posing a reasonable challenge to a learning algorithm. We transform the IP addresses into a 32 dimension input space where each bit of the address corresponds to a dimension. However, because the most significant bits of an IP address are descriptive of the network rather than the host, we initially select just the first 24 bits as our input vector. Later in the results, we examine the dimensionality of the address space in detail. Thus, the input to our learning algorithms are a 24-bit vector while the labels are floating point round-trip latency numbers. Initial Results:We experiment with linear, polynomial and Gaussian kernels and obtain the best results with a third-degree polynomial. The remainder of our results use a third-degree polynomial kernel. To reduce bias, our results represent the average of five independent tests where the order of the data set is randomly permuted between experiments. We use SVM regression to produce a latency prediction. Accuracy is measured in terms of deviation from the true latency in the data set. First, however, we establish a baseline against which to determine the effectiveness of the learning. The most naive approach is to simply always predict the mean latency of the training samples. The mean latency of our data set is 147ms. A mean prediction strategy with a regularized least squares loss function yields a mean absolute loss of 87ms. Thus, results lower than this loss metric indicate effective learning. Figure 1 shows the mean absolute error in milliseconds as a function of training size along with an 87ms line indicating the learning bound. Considering 20% of the data points as training and 80\% as test, we obtain an average relative error of 25ms for latency prediction. 23% of the predictions are within 2ms of the correct value, while more than 60% are within 40ms of our measured latency. Given the inherent noise in the network, the ability to predict latencies within 25ms of their actual value is readily acceptable for applications such as resource scheduling, CDNs and user-directed routing.
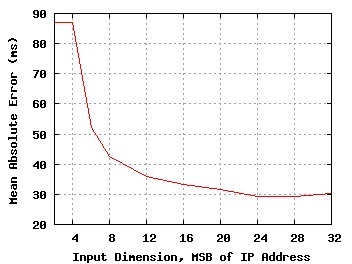
A second metric of performance is to run SVM regression on a false data set identical in size to our real data, but with random features. In other words, for every measured latency, we assign a random IP address to create the false data set. Regression on the false data set with the same kernel parameters and training size yields a mean absolute error of 94ms. Finally, we examine the informational content of each feature in the IP address. Intuitively, the most significant bits correspond to large networks and provide the most discriminatory power. We run the regression SVM algorithm against our data set using the same kernel parameters and training size, but varying the number of input features. For example, the first 12 features of IP address 192.168.1.1 is the bit vector 110000001010. We plot the SVM prediction mean error as a function of the dimensionality of the input space in Figure 2. We see that four or fewer bits yields virtually no information; the mean error is nearly identical to that in a mean prediction strategy. However, with only four more bits of input address, the regression achieves a mean error around 40ms. Thus, the majority of the discriminatory power is comprised of the first eight bits of address. This is a powerful result, but perhaps unsurprising given the traditional assignment of classful "net A" address blocks to large organizations and networks. Error continues to decrease to a minima around 25 bits after which the additional features add little to the regression performance.
Our results are the first to examine latency prediction from machine learning on the IP address space. The high level of performance of our results is encouraging to enable a range of applications. We plan to continue the research, particularly investigating means to perform on-line learning and network inference. References:[1] K. Hubbard, M. Kosters, D. Conrad, D. Karrenberg and J. Postel. Internet Registry IP Allocation Guidelines. Internet Engineering Task Force RFC 2050. November, 1996. [2] M. Blumenthal and D. Clark. Rethinking the design of the Internet: the end-to-end arguments vs. the brave new world. In ACM Transactions on Internet Technology. 2001. [3] T. Joachims. Making Large-Scale SVM Learning Practical. In Advances in Kernel Methods MIT Press, 1999. |
|||||||
|