| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
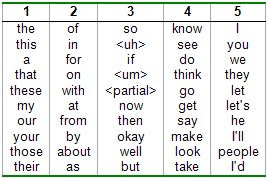
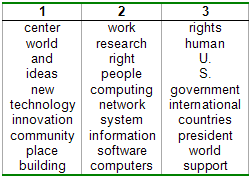
Adaptive Language Modeling Using HMM-LDABo-June (Paul) Hsu & James GlassIntroductionA language model (LM) predicts the probability of future words based on previously observed words and has applications in speech recognition, machine translation, and other natural language processing tasks. For lecture transcription, a good language model involves adapting generic lecture style models with topic-specific content relevant to the target lecture. While transcripts of unrelated, but spoken lectures best characterize the lecture speaking style, they rarely match the content or topic words of the target lecture. Although textbooks, slides, and other textual resources relevant to the target lecture exist, written language poorly predicts spoken words. Further exasperating the lack of training data that matches the target lecture style and topic, the exact topic within a lecture varies and is generally unknown a priori. In this work, we investigate the use of the Hidden Markov Model with Latent Dirichlet Allocation (HMM-LDA) [6] to assign each word in the training corpus to a syntactic state and semantic topic. Through adaptive interpolation of style and topic models built using these context-dependent labels, initial experiments have reduced the perplexity by 11.8% over a trigram baseline. BackgroundIn previous work on adaptive language modeling, cache models [8] leverage the observation that previously appearing words tend to reappear and interpolates a LM built from previous n-gram word sequences with a baseline LM. Although this technique reduces perplexity, it is highly sensitive to recognition errors. Alternatively, to better fit topic variations across sentences, sentence mixture models [7] interpolate topic models trained from clusters of training sentences. Adaptive topic mixture models [3,4] extend the intuition of cache models to topics and increase the weight of topics corresponding to previously observed words. Existing research has applied Latent Semantic Analysis (LSA) clustering [1] and Probabilistic Latent Semantic Analysis (PLSA) [4] to generate topic unigram models. However, recent work on topic modeling has shown promise to not only improve the resulting topics, but also provide context-dependent labels to words in the training corpus. HMM-LDALatent Dirichlet Allocation (LDA) [2,5] improves upon PLSA by placing a Dirichlet prior on topic distributions to reduce overfitting and bias the topic weights for each document towards skewed distributions with few dominant topics. Instead of forcing topics to account for frequent function words, HMM-LDA [6] models general words with syntactic HMM states and only fits the words that vary across documents with a special HMM state mapping to the current document topic mixture. By using HMM, we not only group common words according to their local syntactic behavior, but also assign content words to specific topics according to their global distribution across documents. Applying HMM-LDA to a set of lecture transcripts, we see that while the syntactic states can capture traditional part of speech groupings, it can also identify the hesitation class unique to spontaneous speech (Figure 1). Furthermore, the resulting topics demonstrate strong coherence among their most representative words (Figure 2). Within a paragraph, most content words are assigned to a common topic (Figure 3). Note that of the 7 occurrences of the words "and" and "or" in the excerpt, 6 are correctly labeled as a content (and gate) or syntactic (conjunction) word, demonstrating the ability of HMM-LDA to leverage context in assigning the labels.
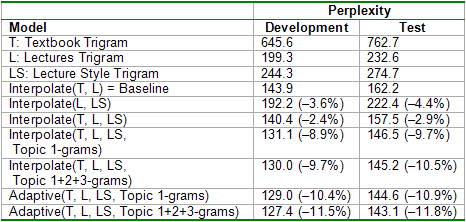
LM ExperimentsTo evaluate the effectiveness of HMM-LDA, we performed several language modeling experiments that leverage the context-dependent topic labels. For these experiments we trained the models on a set of 150 general lectures and an introductory computer science textbook, tuned model parameters on the first 10 lectures from a class based on the textbook, and tested the model on the remaining 10 lectures. To avoid out-of-vocabulary issues, we used the combined vocabulary of 27,244 words for all of our models. First, we observed that standard trigram trained on general lectures tends to place too much weight on words from the training set topics, topics that are not representative of the potential topics of target lectures. Thus, by training a trigram only on n-grams without topic words (LS), we distribute the probability assigned to training set topic words to general content words. When linearly interpolated with the original trigram model (L), the combined model better matches the target topic distribution and reduces perplexity by more than 4%, as shown in Table 1. By utilizing the context-dependent topic labels, we extend beyond the traditional unigram topic models and build topic n-gram models from n-gram sequences that end in words assigned to each topic. This not only captures topic key phrases, but also common transitions from common words to topic words, as shown in Figure 4.
Since each lecture only covers a subset of topics, we determine the minimum perplexity achievable via an optimal linear interpolation of the topic n-gram models with lecture and textbook trigram models. From this cheating experiment, we find that perplexity can be reduced by over 10% over the tuned interpolation of lectures and textbook models baseline by matching the mixture weights to the unknown, but skewed, topic weights in the target lectures. To track the unknown topic weights in the target lectures, we adapt the current mixture distribution according to the posterior topic distribution given the current word. Surprisingly, we obtain lower perplexity than the optimal static mixture interpolation. Evidently, adaptive mixture interpolation not only learns the underlying topic weights of the target lectures, but also tracks them as the distribution shifts over long lectures, yielding 11.8% reduction in perplexity over the baseline model.
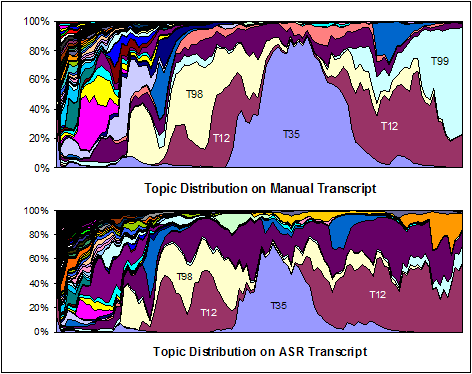
Since the transcript from an automatic speech recognizer (ASR) often contains significant amount of errors, we investigated the effect errors have on the overall trend in topic distribution. As seen in Figure 5, even with a word error rate of 39.7%, the topic distribution on the ASR output still maintains most of the dominant topic components, suggesting that adapting at the topic level is less sensitive to recognition errors.
Future WorkIn this work, we have leveraged the context-dependent topic labels from HMM-LDA to build simple adaptive language models that reduces perplexity by 11.8%. In future work, we plan on evaluating the models on recognition experiments. Furthermore, we hope to apply the changes in topic distribution to improve lecture segmentation. Finally, we are investigating changes to the HMM-LDA model to better capture content word distributions and speaker-specific variations. AcknowledgementsSupport for this research was provided in part by the National Science Foundation under grant #IIS-0415865. References[1] Jerome R. Bellegarda. Exploiting Latent Semantic Information in Statistical Language Modeling. In Proc. IEEE, pp. 1279--1296, Aug. 2000. [2] David M. Blei, Andrew Y. Ng and Michael I. Jordan. Latent Dirichlet Allocation. In Journal of Machine Learning Research, pp. 993--1022, Jan. 2003. [3] P. R. Clarkson and A. J. Robinson. Language Model Adaptation Using Mixtures and an Exponentially Decaying Cache. In Proc. ICASSP, pp. 799--802, Munich, Germany, Apr. 1997. [4] Daniel Gildea and Thomas Hofmann. Topic-Based Language Models Using EM. In Proc. Eurospeech, pp. 2167--2170, Budapest, Hungary, Sept. 1999. [5] Thomas L. Griffiths and Mark Steyvers. Finding Scientific Topics. In Proc. National Academy of Science, pp. 5228--5235, Apr. 2004. [6] Thomas L. Griffiths, Mark Steyvers, David M. Blei, and Joshua B. Tenenbaum. Integrating Topics and Syntax. Advances in Neural Information Processing Systems 17, pp. 537--544, 2005. [7] Rukmini M. Iyer and Mari Ostendorf. Modeling Long Distance Dependence in Language: Topic Mixtures Versus Dynamic Cache. In IEEE Transactions on Speech and Audio Processing, pp. 30--39, Jan. 1999. [8] Roland Kuhn and Renato De Mori. A Cache-Based Natural Language Model for Speech Recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 570--583, June 1990. |
||||||||||
|