| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
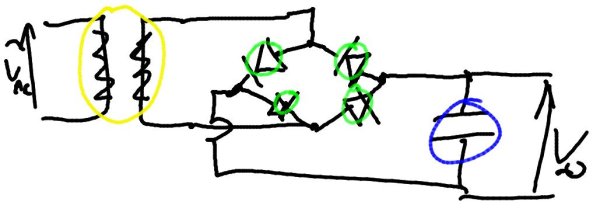
Creating a Human-Computer Dialogue using Speech and SketchingAaron D. Adler & Randall DavisIntroductionSketches are used in the early stages of design in many different domains, including electrical circuits, mechanical engineering, and chemistry. Some aspects of a design are more easily expressed using a sketch, while other aspects are more easily communicated verbally. Our research aims to create a more natural interaction for the user by combining speech and sketching, enabling the user to employ both when interacting with the system. Similarly, the system will be able to use both speech and sketching to interact with the user. This will enable the system to clarify or confirm parts of the user's design that are messy or ambiguous. MotivationThe circuit diagram in Figure 1 (taken from the user study described below) provides several good examples of messy or ambiguous components. There are four diodes in the center of the circuit (circled in green), which should all be identical. However, some of them are sufficiently messy that they might not be recognized by the sketch understanding component. The traditional approach would simply have the system do the best it could (including make a mistake in this case), and then rely on the user to correct it. We suggest instead that, when confused or uncertain, the system ought to be able to query the user, using the same modalities: In the current example the system should circle the component in question and ask the user what it was. The user's speech might provide the system with additional clues about the sketch. For example, the user might mention the word "capacitor" which could help the system distinguish the capacitor (circled in blue) from a similar symbol.
Newton's Cradle (Fig. 2) is a good example of a mechanical device that has some components that are more easily drawn and others that are more easily described verbally. It is a set of pendulums consisting of a row of metal balls on strings. When you pull back and release a number of balls on one end, after a nearly elastic collision, the same number of balls move outward on the opposite end. Although this appears to be easily sketched, the precision required for correct operation makes it nearly impossible. If the user could supply information verbally by saying that "there are five identical, evenly spaced and touching pendulums," it would be far easier to create the device.
Previous WorkWe conducted an empirical study of multimodal interaction in which users were asked to sketch and verbally describe six mechanical devices at a whiteboard. By transcribing and analyzing videotapes of these sessions, we developed a set of approximately 50 rules based on clues in the sketching and the highly informal and unstructured speech. The rules segment the speech and sketching events, then align the corresponding events. Some rules group sketched objects based on timing data, while others look for key words in the speech input such as "and" and "there are," or disfluencies such as "ahh" and "umm." The system has a grammar framework that recognizes certain nouns like "pendulum," and adjectives like "identical." We combined ASSIST[1], our previous system that recognizes mechanical components (e.g., springs, pulleys, pin joints, etc.), a speech recognition engine, and the rules, creating a system that combines sketching and speech. This system allows the user to draw Newton's Cradle casually and then describe the necessary properties verbally making the task far easier. Current WorkAs described in the motivation section, our current research focuses on engaging the user in a two-way conversation using both speech and sketching. This will enable the system to resolve ambiguities in the sketch. The combination of speech and sketching would also allow the system to acquire new vocabulary. If the user drew a new symbol, the system could learn what the symbol looked like and what it was called. The system could also learn additional names for components; for example, the system could learn that "FPGA" was the same as "Field-Programmable Gate Array." These capabilities would create a more natural interaction and enable the computer to be more of a partner in the design process. In order to better understand how users converse about a design, we are conducting a user study that examines how two people use speech and sketching to talk about circuit diagrams. To conduct the study, we have created a real-time shared sketching surface so that the two people can see and use a shared sketching surface to draw circuit diagrams. Each participant in the study sketches and talks about several circuits and the experimenter asks questions and sketches as a computer might. The results of the study will provide us with data about how the computer should respond to the user and how to make the interaction both beneficial and natural. Related ResearchThere are several similar multimodal systems that incorporate speech and sketching. QuickSet[4] is a collaborative, multimodal, command-based system targeted toward improving efficiency in a military environment. The user can create and position items on an existing map using voice and pen-based gestures. QuickSet differs from our system because it is command-based and users start with a map, which provides context, while our system uses natural speech and users start with an empty screen. AT&T Labs has developed MATCH[3], which provides a speech and pen interface to restaurant and subway information. Users can make simple queries using some multimodal dialogue capabilities. However, it uses command-based speech rather than natural speech, and it only has basic circling and pointing gestures for the graphical input modality, not full sketching capabilities. Another system, distributed Charter[2], allows users to use gesture, speech, and sketching for a project scheduling application. This system can use gestures and speech to perform some disambiguation and can learn new vocabulary when a user writes and speaks the new word. Funding sourcesThis work is supported in part by the MIT/Microsoft iCampus initiative and in part by MIT's Project Oxygen. References:[1] Christine Alvarado and Randall Davis. Resolving ambiguities to create a natural computer-based sketching environment. In Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence, pp. 1365--1374, August 2001. [2] Paulo Barthelmess, Ed Kaiser, Xiao Huang, and David Demirdjian. Distributed pointing for multimodal collaboration over sketched diagrams. In Proceedings of the 7th International Conference of Multimodal Interfaces, pp 10--17, Torento, Italy, October 2005. [3] Michael Johnston, Srinivas Bangalore, Gunaranjan Vasireddy, Amanda Stent, Patrick Ehlen, Marilyn Walker, Steve Whittaker, and Preetam Maloor. MATCH: An architecture for multimodal dialogue systems. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 376--383, 2002. [4] Sharon Oviatt, Phil Cohen, Lizhong Wu, John Vergo, Lisbeth Duncan, Berhard Suhm, Josh Bers, Thomas Holzman, Terry Winograd, James Landay, Jim Larson, and David Ferro. Designing the user interface for multimodal speech and pen-based gesture applications: State-of-the-art systems and future research directions. In Human Computer Interaction, pp. 263--322, August 2000. |
|||||||
|