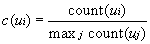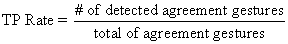| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
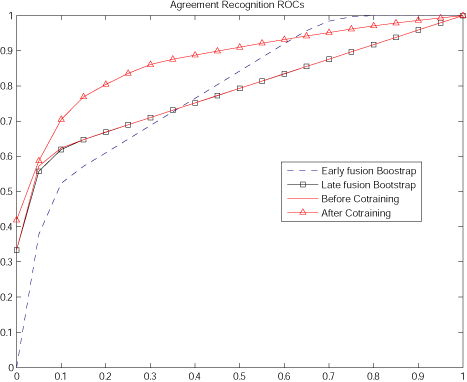
Multimodal Co-training of Agreement Gesture ClassifiersC. Mario Christoudias, Louis-Philippe Morency, Kate Saenko & Trevor DarrellWhatIn this work we investigate the use of multimodal semi-supervised learning to train a classifier which detects user agreement during a dialog with a robotic agent. Separate views of the users agreement are given by head nods and keywords in the users speech. We develop a co-training algorithm for the gesture and speech classifiers to adapt each classifier to a particular user and increase recognition performance. Multimodal co-training allows user-adaptive models without labeled training data for that user. We evaluate our algorithm on a data set of subjects interacting with a robotic agent and demonstrate that co-training can be used to learn user-specific head nods and keywords to improve overall agreement recognition. WhyMany state-of-the-art human-computer interfaces use general purpose gesture and speech recognizers to interact with a user. Not all users interact the same way, however. To the contrary, it is believed that each person has their own individual idiolect [3], their unique understanding and use of language and gesture. The goal of this work is to investigate the effectiveness of multimodal semi-supervised learning for the construction of recognition algorithms that adapt to the users visual and spoken idiolect to improve recognition performance without requiring any labeled training data for that user. In particular, we look at the application of multimodal co-training to the domain of agreement recognition during multimodal interaction with a conversational agent. In this setting, the user interacts with an agent using speech and head gestures; the agent uses recognized head nods and keywords in the recognized speech to determine when the user is in agreement with the agent. In what follows, we develop a multimodal co-training algorithm to automatically adapt the agreement recognizer of the conversational agent to its users and increase recognition performance. HowCo-training is a semi-supervised learning algorithm developed by Blum and Mitchell [1]. It relies on multiple, independent views of the same classification task to perform semi-supervised learning. With co-training a classifier is trained in each view using an initial seed set of labeled examples. Each classifier is then run in turn on the unlabeled data-set, and confidently classified examples are added to the seed set along with their assigned labels. This process is iterated until either a target size training set is reached, or the algorithm cannot label any of the remaining examples confidently with any of the classifiers. In practice, it is assumed that each classifier outputs confidence values and confidently classified examples are those examples whose confidences are above a threshold. The intuition is that each classifier will be able to label examples that other classifiers cannot and the training set is able to grow in this semi-supervised manner. The use of co-training to adapt the speech and head nod classifiers of the conversational agent to its user is complicated by the asynchrony between the user's speech and head gesture. Additionally, the user can say an agreement utterance without head nodding, or head nod without saying anything or saying extraneous speech. We refer to the later as the missing data problem. To solve for the asynchrony between the speech and head gesture modalities we use a time window approach to map confidently labeled examples across modalities. To be specific, head gestures are labeled as a head nod if they occur within a time window, Δt, of an agreement keyword and a keyword is labeled as agreement if it occurs within Δt of a head nod. We address the missing data problem in the gesture modality with a no motion detector. We discuss a simple no motion detector in the following section. We currently ignore missing data in the speech and assume that missing speech is handled by the speech recognizer. We co-train two classifiers: (1) a support vector machine (SVM)-based head nod classifier and (2) a keyword-based classifier. To detect head nods, we use a head gesture recognition technique similar to [6]. The input to the SVM-based head nod recognizer are 3D head rotation frequencies computed using a windowed fast-Fourier transform (FFT) on the x, y and z head rotation velocity signals of each subject obtained from a six-degree of freedom head pose tracker [5]. The frequency responses of the x, y and z head rotation velocities at each time window are concatenated into a single vector to form the feature vectors supplied as input to the SVM classifier. To compute the confidence of a classified head nod during co-training we use the pseudo-likelihood algorithm described in [7]. The keyword-based classifier is a rote learner: it maintains a list of keywords/key-phrases and their associated counts of how many times they each appear in the training corpus. It classifies a word or phrase as signifying agreement if it appears in its list. The confidence, c, of a classified keyword, ui, is computed as its count divided by the maximum count stored by the keyword-based classifier, This is a relatively simple language model and more sophisticated techniques can be used (e.g., n-grams). Nevertheless, we show that this model can aid in the agreement recognition task and can be improved with co-training. The final agreement classifier is formed by fusing the decision outputs of both the head nod and keyword classifiers. We do this by applying a logical OR operator between the binary labels output by each classifier where 1 means agreement and -1 disagreement. In the following section we report results with this final, combined classifier. ProgressFor our experiments we use video sequences of 16 subjects interacting with an embodied-conversational agent, Mel, a robotic penguin [8]. The robot gives a demo to the user, each interaction consisting of several head gestures and spoken utterances from the user and being a few minutes in length (between 3 and 8 minutes long). To evaluate the performance of our agreement classifier, we used labeled head nods obtained from two independent labelings from two labelers. We kept the labels for which both the labelers agreed upon as ground truth. We defer the problem of speech recognition as future work; for the results in this work speech is manually annotated and time-stamped with Anvil [4] a video annotation toolkit. We use a no motion detector for ignoring still head motion samples during co-training that looks at the variance of the non-DC components of each head gesture sample's frequency spectrum. If the variance is below a threshold, then we treat that sample as either noise or no head motion and ignore it during co-training. In our experiments, we used a threshold of 10-4. The no motion detector did not work for two of the subjects in our database; these subjects were discarded from our evaluation set. In our experiments we perform leave-one-out experimentation, where we evaluate co-training on each subject individually. The data from the rest of the subjects is used to train the initial SVM classifier improved with co-training. We use a non-linear SVM with RBF kernels and we learn its parameters using a 3-fold cross-validation on the training set. To compute the FFT samples that are used as input to the SVM, we use a window of 32 frames sampled at 25Hz (approximate speed of our camera). For each user, the keyword-based classifier is initialized with the keyword yes and count equal 1. During co-training we chose a confidence threshold of 0.95 for the SVM and 0.1 for the keyword classifier. We found these thresholds to work well in our experiments; further investigation is needed to determine how to set these thresholds automatically. Words in the speech and head rotation velocity sequences were labeled as positive across modalities during co-training using an overlap window of size Δt = 2.0 seconds. As a baseline, for each subject, we compare co-training to bootstrapping [2] in each modality individually (referred to as late-fusion) as well as to bootstrapping an early-fusion multimodal classifier. The late-fusion bootstrap model is formed by bootstrapping the initial head nod SVM of the agreement recognition model on its own and then combining the final SVM with the initial keyword classifier. The early-fusion classifier is defined as an SVM whose observation vector is the keyword label concatenated with the head frequency samples that co-occur within a time window of the keywords. To fuse the keywords and head frequency samples in this model, we used a time window of 2.0 seconds, the same used during co-training. The SVM type and setup is the same as for the head nod recognizer used in multimodal co-training. As in the keyword model used by co-training, the multimodal classifier is initialized with only the yes keyword. During bootstrapping, each classifier is adapted by classifying the unlabeled examples and then adding those examples whose confidence is above a threshold to the training set. This process is iterated until no more examples can be classified confidently in the unlabeled data set. In our experiments, we use a threshold of 0.95 for each classifier during bootstrapping as is done with multimodal co-training. Figure 1 displays the receiver-operator curves (ROCs) for the co-training, and the early and late fusion bootstrapping experiments. These ROCs result from averaging the ROC of each of the subjects in our database resulting from the leave-one-out experiment.
The ROC curves of Figure 1 are computed as follows. A head nod is deemed correctly classified if a head frequency sample within the start and end time of the head nod is classified as positive. A keyword is correctly classified if it is in the keyword list of the keyword-based classifier and its confidence is above a threshold that we vary to generate the ROC. Correctly classified head nods or keywords that are within Δt = 2.0 seconds (the time-overlap window used by co-training and the early bootstrap models discussed above) contribute to the same true positive (TP); i.e., we compute a logical OR operator between them and treat them as part of the same underlying agreement label. Otherwise, each correctly classified head nod or keyword contributes its own true positive. Thus we have, Any frame labeled as an agreement gesture that is outside the start and end time of a ground truth head nod label constitutes a false positive (FP). Similarly, any nonagreement keyword that was misclassified as positive is also a false positive. The false-positive rate is therefore, As demonstrated by Figure 1, co-training between the head nod and keyword classifiers achieves significantly better results than the other methods evaluated in this work. The early-fusion bootstrap model is unable to improve its initial performance. We hypothesize that the early fusion makes this model committed to the labels in its training set, making it difficult for new agreement keywords and head nods to be learned. Similarly, the late-fusion bootstrap model is unable to improve its recognition performance because the keyword based classifier cannot adapt on its own and the head nod classifier is only able to add the high confidence examples to its training set during bootstrapping. The low-confidence positive examples are un-attainable with the late-fusion model and it therefore cannot improve. In contrast, our multimodal co-training algorithm is able to adapt the agreement recognizer to new users and increase overall recognition performance. FutureIn this work we introduced co-training in the context of multimodal sequence classification. We demonstrated that multimodal co-training can be used to automatically adapt the agreement recognizer of a conversational agent to new users and improve overall agreement recognition. Our experiments show that for a fixed false positive rate of 0.1 co-training improves recognition rates from 62% to 71%. Unlike co-training, the early and late- fusion bootstrapping algorithms are not able to significantly improve agreement recognition performance. We are currently investigating more general techniques for addressing the alignment and missing data issues discussed above, including clustering of head gesture and speech frames to handle missing data and the use of dynamic time-warping for achieving a better alignment between modalities. SupportThis research was carried out in the Vision Interface Group, which is supported in part by DARPA, Project Oxygen, NTT, Ford, CMI, and ITRI. This project was supported by one or more of these sponsors, and/or by external fellowships. References:[1] A. Blum and T. Mitchell. Combining labeled and unlabeled data with co-training. In COLT: Proceedings of the Workshop on Computational Learning Theory, Morgan Kaufmann Publishers , pages 92100, 1998. [2] B. Efron and R. Tibshirani. An Introduction to the Bootstrap. Chapman and Hall, 1993. [3] V. Fromkin, R. Rodman, and N. Hyams. An Introduction to Language. Michael Rosenberg, 2003. [4] M. Kipp. Gesture generation by imitation - from human behavior to computer character animation. Boca Raton, Florida: Dissertation.com, December 2004. [5] L.-P. Morency, A. Rahimi, and T. Darrell. Adaptive view-based appearance model. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition, volume 1, pages 803810, 2003. [6] L.-P. Morency, C. Sidner, C. Lee, and T. Darrell. Contextual recognition of head gestures. In Proceedings of the International Conference on Multi-modal Interfaces, October 2005. [7] J. C. Platt. Advances in Large Margin Classifiers, chapter Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods, pages 6174. MIT Press, 1999. [8] C. Sidner, C. Lee, C.D.Kidd, N. Lesh, and C. Rich. Explorations in engagement for humans and robots. Artificial Intelligence, 166(12):140164, August 2005. |
|||||||
|
||||||||