| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
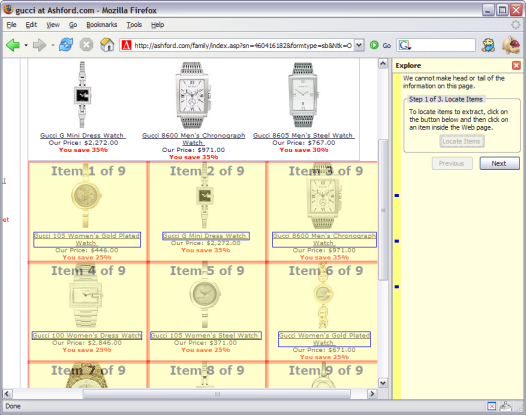
Supplementing the Web Experience Using Semantic Web TechnologiesDavid F. Huynh, Robert C. Miller & David R. KargerProblem and DirectionFor all the riches of the World Wide Web, gathering resources to accomplish a complex information-centric task is not trivial. Relevant resources supporting the task may be scattered across many corners of the Web. Although one can use search engines to reach most of these corners, it remains challenging at best and impossible at worst to bring back only the relevant bits, pool them together, perform analysis on the aggregate, and visualize the data in ways that support the task at hand. Boundaries of the Web’s information model are felt today as evidence by the buzz of new “Web 2.0” technologies and hacks, such as RSS and microformats. Web users are no longer content with simply looking at pre-canned presentations that Web sites serve up. They want to merge news stories by topics of their interests regardless of which news sites the stories came from. They want to map street addresses found on Web pages that do not embed maps (e.g., [1]). They want to combine information from multiple sites as none of the sites is sufficient for their needs. They are enlightened by client-side tools that promise the ability to customize their Web experience [2,3]. Ironically, the Semantic Web project [4] has long envisioned the next step of the Web wherein structured data can be exchanged independent of presentation. While on the Web structured data from back-end databases is stripped of its structure and serialized into presentational HTML, data on the Semantic Web flows with its structure intact. A street number and a price tag arriving at a Web browser will look different to the user’s machine and can thus be processed differently. Structured data can be lifted off Web pages, reused, recombined in ways that suit each individual user’s needs. Yet, this powerful vision of the Semantic Web comes with the price tag of difficult implementation, both in technical challenges and in deployment strategies. Over almost a decade, efforts have been spent in developing infrastructure and developer’s tools. Some SW work has focused on benefits for end-users’ while the majority of research projects attempt to address information needs of large-scale organizations. Still, the Semantic Web as a global medium for structured data exchange remains elusive. This research work explores the use of Semantic Web technologies in the small, right inside the familiar Web browser, to counter the limitations of the Web today. In addressing real, apparent user needs and providing a richer experience on the current Web, we hope to show the value of the Semantic Web, thus appealing for the construction of such a global medium. ProgressWe are developing Web browser extensions (of note is Piggy Bank [5]) that let users extract data from within Web pages, recovering some of the structure that has been lost from the conversion into HTML. The recovered data is encoded in Semantic Web’s data model, RDF. The following screenshot shows a one-mouseclick operation that a user can perform to identify items of interest for extraction.
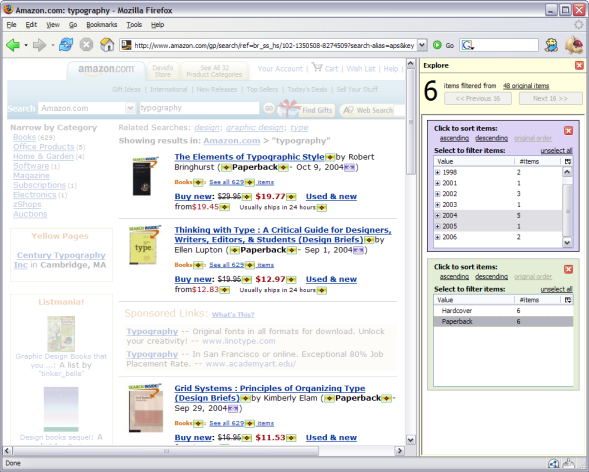
The extraction process automatically discovers informational fields within the items’ HTML, which are then used to offer supplemented browsing and sorting features. In the screenshot below, 48 items have been extracted from an Amazon.com search. They are then refined down to only 6 items that are “Paperback” and published in 2004 and 2005. These two filtering operations are not provided by the Web site itself but supplemented by our Web browser extension.
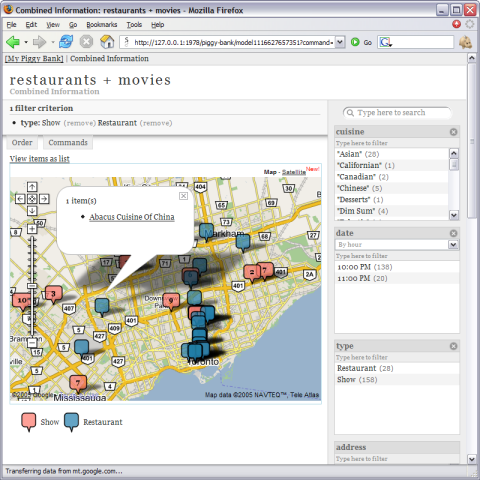
Our Web browser extensions are also capable of re-displaying extracted information in different views and merging information from different Web sites. The following screenshot shows movie shows and restaurants extracted from 2 different sites but plotted together on a single map.
We will be exploring many more ways for users to manipulate information extracted from the Web—sharing it with other people, performing calculations on it, persisting it for long-term use, building up personal values for the publicly available information that they now can only look but not “touch.” References[1] Housing Maps. http://housingmaps.com/. [2] Greasemonkey. http://greasemonkey.mozdev.org/. [3] Michael Bolin, Matthew Webber, Philip Rha, Tom Wilson, and Robert C. Miller. Automation and Customization of Rendered Web Pages. In The Proceedings of the Conference on User Interface Software and Technology (UIST), pp 163-172, 2005. [4] Tim Berners-Lee, James Hendler, and Ora Lassila. The Semantic Web, Scientific American, May 2001. [5] David F. Huynh, Stefano Mazzocchi, and David R. Karger. Piggy Bank: Experience the Semantic Web Inside Your Web Browser. In The Proceedings of the International Semantic Web Conference, Galway, Ireland, November 2005. |
|||
|