| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Transparent Accountable Data Mining InitiativeHarold Abelson, Tim Berners-Lee, Chris Hanson, Lalana Kagal, Gerald Jay Sussman, K. Krasnow Waterman & Daniel J. WeitznerMotivationAttempts to address issues of personal privacy in a world of computerized databases and information networks -- from security technology to data protection regulation to Fourth Amendment law jurisprudence -- typically proceed from the perspective of controlling or preventing access to information. We argue that this perspective has become inadequate and obsolete, overtaken by the ease of sharing and copying data and of aggregating and searching across multiple data bases, to reveal private information from public sources.[1] To replace this obsolete framework, we propose that issues of privacy protection currently viewed in terms of data access be re-conceptualized in terms of data use. From a technology perspective, this requires supplementing legal and technical mechanisms for access control with new mechanisms for transparency and accountability of data use. In this project is part of a larger effort at developing a technology infrastructure -- the Policy Aware Web[2] -- that supports transparent and accountable data use on the World Wide Web, and elements of a new legal and regulatory regime that supports privacy through provable accountability to usage rules rather than merely data access restrictions. OverviewInformation systems upon which we depend are becoming ever more complex and decentralized. While this makes their power and flexibility grow, it also raises substantial concern about the potential for privacy intrusion and other abuses. Understanding how to incorporate transparency and accountability into decentralized information systems will be critical in helping society to manage the privacy risks that accrue from the explosive progress in communications, storage, and search technology. A prime example of a growing, decentralized information system is the World Wide Web, recently augmented with structured data capabilities and enhanced reasoning power. As the Web gets better and better at storing and manipulating structured data it will become more like a vast global spreadsheet or database, than merely a medium for easy exchange and discovery of documents. Technologies such as XML, Web Services, grids, and the Semantic Web all contribute to this transformation of the Web. While this added structure increases inferencing power, it also leads to the need for far greater transparency and accountability of the inferencing process. By transparency we mean that the history of data manipulations and inferences is maintained and can be examined by authorized parties (who may be the general public). By accountability we mean that one can check whether the policies that govern data manipulations and inferences were in fact adhered to. Transparency in inferencing systems enables users to have a clear view into the logical and factual bases for the inferences presented by the system. Accountability in inferencing enables users or third parties to assess whether or not the inferences presented comply with the rules and policies applicable to the legal, regulatory or other context in which the inference is relied upon.Today, when an individual or an enterprise uses a single, self-contained set of data and applications, the controls necessary to assure accuracy and contextualize the results of queries or other analyses are available and generally well understood. But as we leave the well-bounded world of enterprise databases and enter the open, unbounded world of the Web, data users need a new class of tools to verify that the results they see are based on data that is from trustworthy sources and is used according to agreed upon institutional and legal requirements. Hence, we must develop technical, legal and policy foundations for transparency and accountability of large-scale aggregation and inferencing across heterogeneous data sources. We can expect a wide range of legal and regulatory requirements on inferencing systems, and some requirements may well overlap or contradict others. This expected diversity of rulesets makes in all the more important to have one common technical framework for managing accountability to rules. Privacy requirements for data miningIn analyzing data mining system, we have identified three distinct classes of potential privacy rule violations:
The first two cases can be handled with audit and verification mechanisms of the sort that are technically well understood and commercially available today. However, the third problem requires a posteriori assessment of rules compliance i.e., accountability. It is only when the data is actually used (long after collection) for an impermissible purpose that the rule violation can be discovered. In logical terms, the conclusion of the proof relies upon antecedents that logically support the conclusion but are not legally permitted to be used to support such a conclusion. Basic Architecture for Transparent, Accountable Data MiningIn order to meet the above requirements, we propose an information architecture consisting of general-purpose inferencing components connected in a manner (Figure 1) that provides transparency of inferencing steps and accountability to rules.
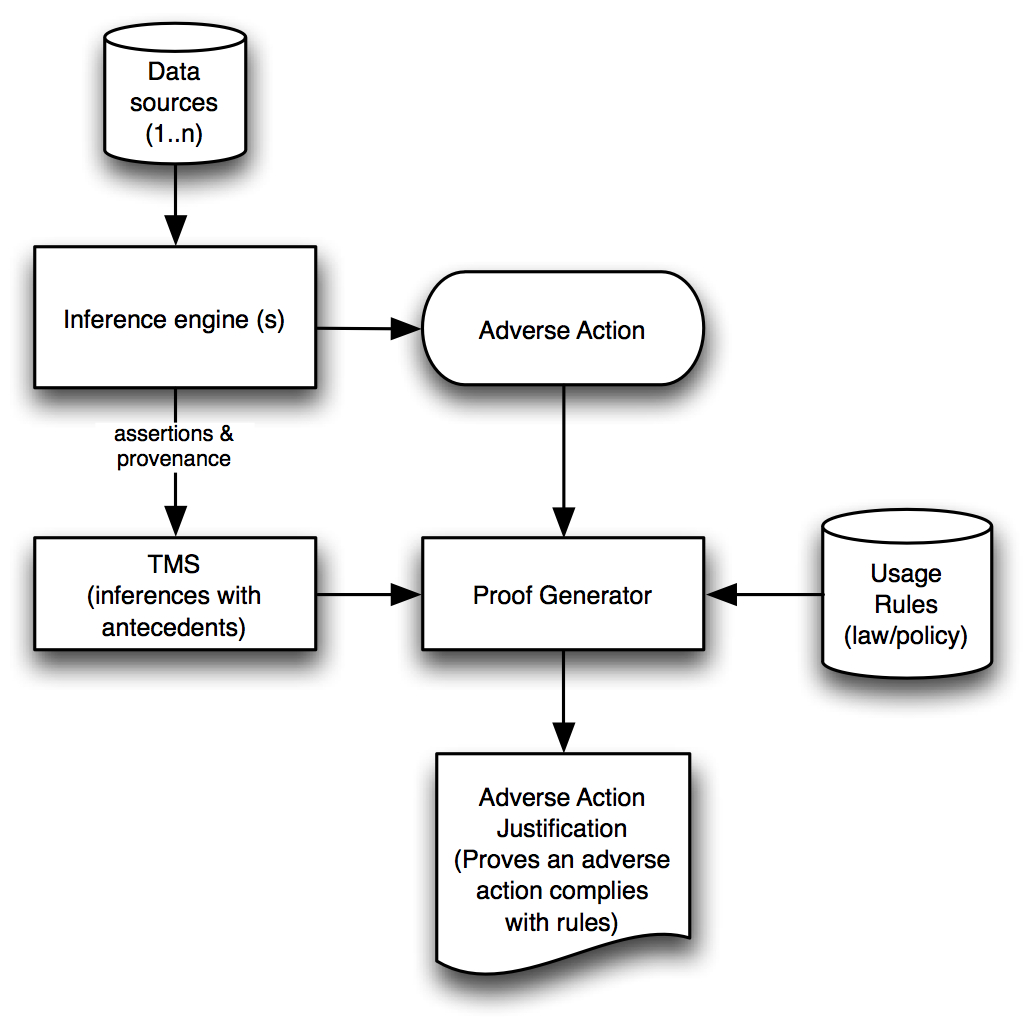
TAMI Functional Architecture (Figure 1) The transparency and accountability architecture depends upon three components:
The inference engine provides assistance to the government investigator or analyst in identifying suspicious profiles in those data sets accessible for this purpose. This data would then be processed through an inferencing engine (we use the cwm engine [3] in this case) that provides investigative results. In addition to these investigatory inferences, a record of the inferences and their justifications will be stored in the Truth Maintenance System (TMS) [4] . The TMS combined with a proof generator allows anyone with access to the system to determine whether or not the personal information in the system is being used in compliance with relevant rules and consistent with known facts. At critical stages of the investigation, such as sharing of information across agency boundaries or use of information to support an adverse inference (secondary screening, criminal indictment, arrest, etc.), the proof generator will attempt to construct a proof that the use proposed for the data at that transition point is appropriate. The proof generator would be able to draw on information collected in the TMS and bring to bear the relevant rule sets. ConclusionOur goal is to develop technical and legal design strategies for increasing the transparency of complex inferences across the Semantic Web and data mining environments. We believe that transparent reasoning will be important for a variety of applications on the Web of the future, including compliance with laws and assessing the trustworthiness of conclusions presented by reasoning agents such as search engines. Our particular focus is on using transparent inferencing to increase accountability for compliance with privacy laws. We also expect that this technical research will provide important guidance to policy makers who are considering how to fashion laws to address privacy challenges raised by data mining in both private sector and homeland security contexts. Funding SourcesNational Science Foundation grants: the Transparent Accountable Data Mining Initiative (award #0524481) and Policy Aware Web project (award #0427275). References:[1] Weitzner, Abelson, Berners-Lee, et al., "Transparent Accountable Data Mining: New Strategies for Privacy Protection", MIT CSAIL Technical Report MIT-CSAIL-TR-2006-007 (27 January 2006). [2] Weitzner, Hendler, Berners-Lee, Connolly, Creating the Policy-Aware Web: Discretionary, Rules-based Access for the World Wide Web in Elena Ferrari and Bhavani Thuraisingham, editors, Web and Information Security. IOS Press, 2005. [3] Berners-Lee, T., CWM A general purpose data processor for the Semantic Web, 2000. http://www.w3.org/2000/10/swap/doc/cwm.html [4] [Do87] J. Doyle. A Truth Maintenance System. In Readings in Nonmonotonic Reasoning, pages 259279. Morgan Kaufmann Publishers, San Francisco, CA, USA, 1987. |
|||
|