| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
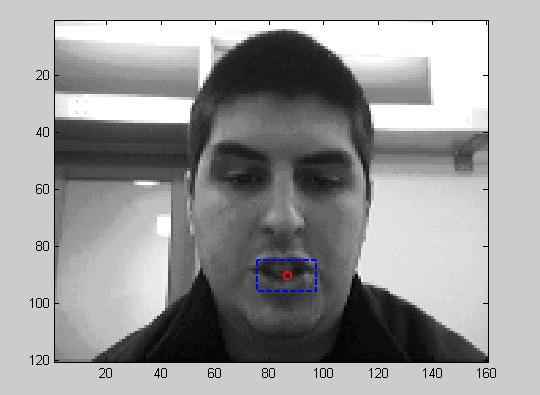
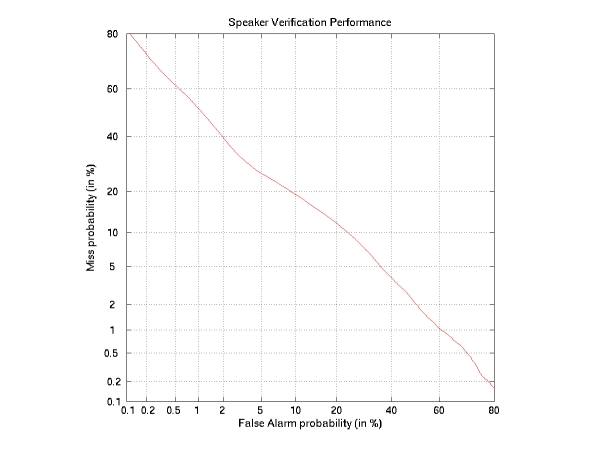
Robust Audio-Visual Person Verification Using Web-Camera VideoDaniel Schultz, Timothy J. Hazen & James R. GlassIntroductionIn this project we are investigating methods for improving the accuracy and robustness of an audio-visual person verification system. The system detects faces and facial features in video frames and attempts to classify the detected face as that of an enrolled user or that of an imposter. We test the effectiveness of several statistical techniques to improve the accuracy with which the verification system classifies users into the enrolled or imposter groups. The robustness of verification is tested using video data recorded in various lighting conditions and with irregular backgrounds. The combination of visual and audio information for person verification will also be investigated. This project builds on previous work in the area of speaker identification using handheld devices[1]. This research will benefit person verification systems making them more robust in environments with significant background noise, poor lighting conditions, or inconsistent visual backgrounds. Data CollectionAudio-visual data was recorded using a laptop with a web-camera. Each subject read 11 short utterances in each of three locations: a quiet office setting, an indoor common area with heavy foot traffic, and an outdoor area near a busy intersection. There were two rounds of data collection. In the first round, fifty subjects were recorded. These fifty subjects became the enrolled users for the user verification and were used for training purposes. In the second round, there were one hundred subjects. Fifty of the second round subjects were repeat recordings of the enrolled users. The other fifty subjects in the second round became the imposters. The set of data from the second round is used to evaluate the effectiveness of systems trained using data from the first round training set. Face Detection and Feature ExtractionAfter data collection, face detection software is applied to the video and faces and facial features are extracted. Figure 1 shows an example of a frame with a detected face and a blue box indicating the detected location of the mouth region. An example of an extracted face image can be seen in Figure 2. We have conducted experiments using full face images and plan to conduct experiments using sub-regions or individual features of the face such as the mouth, nose, eyes, or the top half of the face. Classifier Training and TestingAfter the features have been extracted, classifiers are built for combinations of these facial features to determine their effectiveness for person verification. First, a support vector machine (SVM) is trained using images from the enrolled users' first round data. A separate SVM is trained for each facial feature being tested. Then feature images extracted from the second round data are run through the SVM and scores are recorded. The scores from the individual SVMs are then combined into feature vectors and used to train a classifier. The classifier will seek to minimize the equal error rate of user verification based on the given features. We hope to achieve results similar to those from [2] in which equal error rates as low as 2.57% were achieved using multiple features from single image data collected on a handheld device. The classifier will also be used to evaluate which features are the best suited for person verification. Some preliminary results can be seen below in Figure 3. The results show the miss probability (the likelihood of an enrolled user being rejected) versus false alarm probability (the likelihood of an imposter being accepted) for individual frame scores from an SVM trained and tested on data from the office setting using full facial images as the feature. Ongoing and Future WorkWe plan to implement an audio speaker verification system in addition to the video-only verification system. The separate results of the audio and visual speaker verification systems will be combined with the goal of achieving a higher accuracy with the combined results than either system can achieve alone. AcknowledgmentsSupport for this research has been provided by ITRI. Special thanks to Kate Saenko for her help on this project, especially with the video processing and the face detection software. References:[1] R. Woo. Robust Limited Enrollment Speaker Identification for Handheld Devices. M.Eng. Thesis. June 2005. [2] T.J. Hazen, E. Weinstein, R. Kabir, A. Park, and B. Heisele. Multi-modal face and speaker identification on a handheld device. In Proceedings of the Workshop on Multimodal User Authentication, Santa Barbera, December 2003. |
|||
|