| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
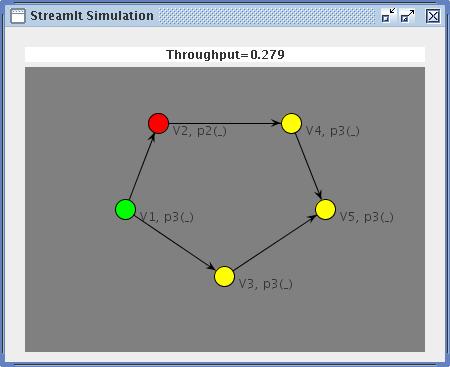
Market-Based Dynamic Load Balancing for StreamIt ProgramsEric Fellheimer & Una-May O'ReillyIntroductionThe StreamIt programming language [1] is well-suited for parallel computations over streams of data. Its compiler divides a program into a complex graph or pipeline of simpler filters. When the computation will be executed on a processor cluster, the compiler also attempts to optimize the overall computation via load balancing. However, this static optimization cannot account for unexpected loads on processors of the cluster. The goal of this project is to implement a dynamic load balancing mechanism using a decentralized, market-based approach. A market is a natural-system "solution" to the problem of allocating resources to consumers. It allows adaptive behavior on the part of consumers and resource sellers by giving them a means to express their reaction to dynamic circumstances such as climbing prices, decreasing budgets or changing resources levels. Our hypothesis is that an artificial "computation" market will be an efficient means of arbitrating the allocation of resources to StreamIt filters. Previous work, see [2,3] in the domain of grid computing and distributed computer network resource allocation lend support to our hypothesis. The StreamIt SimulatorIn order to ease the experimentation process, we have implemented a simplified model of a StreamIt computation on a processor cluster. While removing complexities such as network latency, the model still maintains much of the richness of the computation dynamics (ie. workload per filter, input-output relations of each filter, buffer sizes) while it simulates dynamic resource allocation circumstances such as somewhat predictable but noisy load from processes exogenous to the program and unpredictable load due to processor assignments of the program's filters. The simulation takes as input a stream graph and the cluster graph generated by the StreamIt compiler when appropriate flags are used. The stream graph is a concise representation of the StreamIt program that has sufficient details to simulate the program. It includes the graph (i.e. pipleine) topology of the computation as well as information about each filter (a node in the graph), such as an estimate of working time needed for each execution of the filter. The cluster graph provides information about the processor allocation for the StreamIt computation's execution. Each node in this graph is a description of a processor in the cluster, which includes its relative base speed (related to its processor type), as well as a model of its load. The simulation model is data-driven. That is, data elements in buffers are timestamped as they move throughout the stream graph. The simulation models two main events in ascending time order. These are:
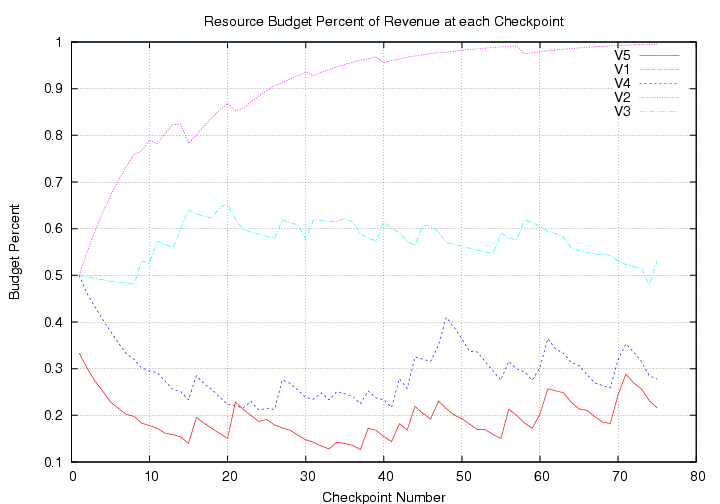
Another important concept in the simulation is that of the checkpoint. Checkpoints occur periodically throughout the computation. When it is time for a checkpoint, all the data in the system is flushed: no new data is injected, and the system waits until all data currently in the system is processed by the final filter in the stream graph. The utility of these checkpoints is that the filters no longer carry state (i.e. data buffers are all empty). Thus, the system is free to move the filters to different processors in the cluster without affecting the correctness of the computation. The MarketWe have implemented our initial design of the load balancing market and anticipate refinements as we experiment with it and investigate its behaviour. The goal of the market is to maximize throughput of the entire computation through local policies at each of the individual filters. A policy, in general, expresses a split of "money" between payments for inputs and processor usage to complete the filter's work. We regard the graph computation of the StreamIt program as a supply chain where the input data of the program represents the raw materials that enter a supply chain. Each filter between the first and last filter of the the stream pipeline is a middle-man in the supply chain. Each middle-man refines the raw materials of its producers (i.e. data from its input buffers) into an enhanced good or data element and sells them to the filter(s) downstream from it. At the output end of the supply chain, the final producer takes its refined goods to market and is paid for them. Allocation of money through the pipeline sweeps upstream from final filter to initial filter. Each filter considers how to split the income it gets per unit of output (i.e. we arbitrarily set the final filter's income per unit to the unit price) between the prices it will pay for its input goods from its producers and the price it is willing to pay for the processing of its input goods. If the filter has found itself idle for some fraction of the previous checkpoint interval, with available inputs, then it should logically allocate more money to processing and pay less for its inputs which would potentially slow down their delivery. Optimally, a filter would never be idle and not be over-paying its producers. If a filter is always busy and has more than enough resources in its input buffers, it should pay a little less for the resources and pay a little more to get a faster processor. If a filter is idle because its downstream buyer's buffers are too full for new items, it should decrease what it pays for a processor (since the speed is wasted). These "spending behaviours" constitute a filter's disbursement policy. We intend to implement at least one disbursement policy (which will be parameterized) and will investigate how a policy (whether the same one for all filters or a different per filter) affects throughput of the pipeline and achieves high performing dynamic load balancing. The interface between the market and StreamIt simulator is the runtime handler, whose job is to derive the mapping from filters (stream graph nodes) to computers (cluster graph nodes). We have implemented a baseline instantiation of the runtime handler, the static load balancer, which maps according to the cluster graph produced by the StreamIt compiler. We are optimistic that the runtime overhead introduced by the runtime handler will be minimal compared to the speedup we get. We have also implemented our first alternative runtime handler whose mappings can change dynamically throughout the computation according to the prices filters post as an indication of what they are willing to spend for executing their work on a processor. As per a "natural" market, processors that are faster and less loaded will cost the most. The runtime handler is parameterized and we intend to explore the impact different parameter regimes have on stream throughput. At this date, the initial experimental framework is already in place: the first set of experiments will test simple variations of stream and cluster graphs with the different runtime handlers and disbursement policies.
References:[1] Michal Karczmarek, William Thies and Saman Amarasinghe. Phased Scheduling of Stream Programs. In LCTES'03, San Diego, California, USA, June 2003. [2] Carl A. Waldspurger and Tad Hogg and Bernardo A. Huberman and Jeffrey O. Kephart and W. Scott Stornetta. Spawn: A Distributed Computational Economy. In IEEE Transactions on Software Engineering, February 1992. [3] Brent N. Chun and Philip Buonadonna and Alvin AuYoung and Chaki Ng and David C. Parkes Mirage: A Microeconomic Resource Allocation System for Sensornet Testbeds. In Proceedings of the 2nd IEEE Workshop on Embedded Networked Sensors, May 2005. |
|||||||
|