| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
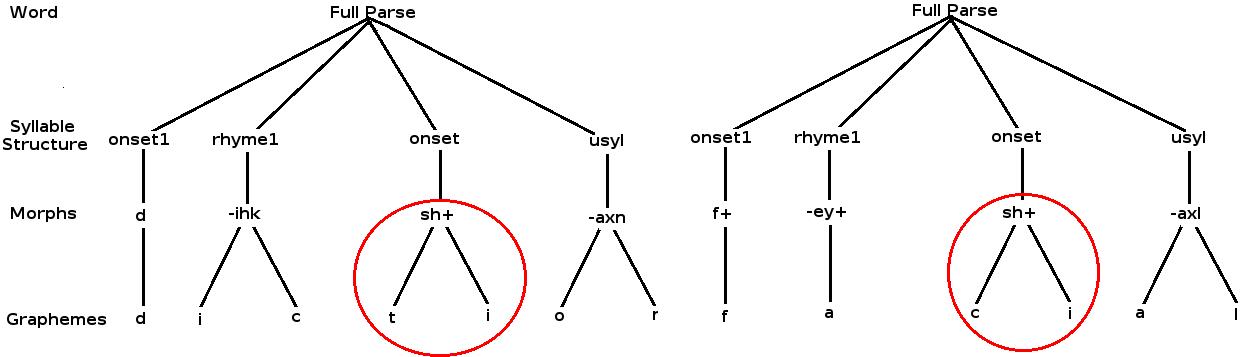
Out-Of-Vocabulary Modeling for Open Vocabulary Speech RecognizersGhinwa F. Choueiter & James R. GlassIntroductionIn speech recognition applications, out-of-vocabulary (OOV) words are a major cause of increased word error rates. Unfortunately, the occurrence of OOV words is unavoidable because vocabulary sizes are finite. Therefore approaching the problem by increasing the vocabulary size is not a permanent solution since new words will always occur. Furthermore, OOV words are often keywords or content words, such as proper names and cities, that should be detected properly by the recognizer. In this research, we are investigating an approach for modeling OOV words using sub-word units consisting of hybrid clusters of graphemes and phonemes. Such a model has the capability of generating spellings of the OOV words. The flexibility of the model lies in its ability to generate reasonable spellings for both in-vocabulary as well as out-of-vocabulary words. The potential applications of this OOV model are many such as automatic transcription and query answering where the query can contain novel keywords. In this abstract, we briefly describe the implemented OOV model, the experiments set up for far, as well as the results obtained and the future work that we aim to pursue. The Out-of-Vocabulary ModelIn this research we implement a sub-word based OOV model that allows any unknown word to be represented as a sequence of sub-word units. The units are currently obtained using a grammar defined by hand-written rules that encode positional, phonological, and morphological constraints. The rule-based grammar has the capability to parse words into two different types of sub-lexical units:
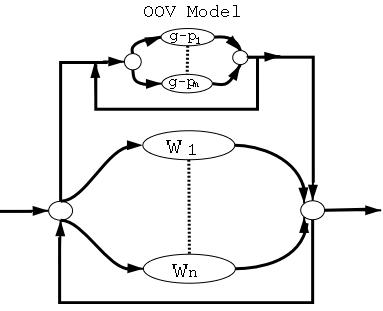
Figure 1 illustrates two hierarchical parse trees for the words diction and facial generated using the rule-based grammar. One can read off the morphs from the third level branches and can obtain the grapheme-phonemes by combining both the graphemes and the morphs. Figure 1 also illustrates how the same morph sh+ occurs in both diction and facial but is spelled with different graphemes: ti and ci respectively. With the rule-based grammar, we are able to generate our sub-word units by parsing a large dictionary. For the purpose of our current experiments, we only use the grapheme-phonemes to build a sub-lexical language model. Figure 2 (left) shows how the OOV model is integrated with the speech recognizer. As illustrated, the recognizer can either hypothesize a word or an OOV in which case, the OOV model is activated and a sequence of grapheme-phonemes is generated.
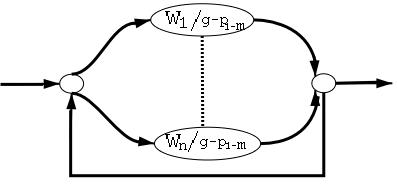
The idea of implementing a sub-word based OOV model is not a new one. Bazzi and Glass proposed a phone-based OOV model which represents unknown words as a sequence of phones[1]. Our model has the additional capability of generating the spelling of OOV words but the underlying mechanism of integrating the OOV model with the recognizer is similar to theirs as illustrated in Figure 2. Bisani and Ney also worked on a sub-lexical OOV model[2]. However, in their work there is no distinction between words and sub-word units, and the recognizer can either hypothesize a word or one of the sub-word units as illustrated in Figure 2. We have also implemented the Bisani-Ney model using the grapheme-phoneme units. ExperimentsIn order to assess the effect of introducing an OOV model into our recognizer, we set up a 16kWrd baseline speech recognizer which includes no OOV modeling. To build a word trigram, we use lecture data collected at MIT. The baseline is tested on a physics lecture and language modeling adaptation is performed using a companion physics textbook. To evaluate the performance of the baseline recognizer with a larger vocabulary, we increase it to 38kWrd. We also set up a cheating experiment with no OOV words by augmenting the vocabulary with all the unknown words. Results
The sample results in Tables 1 are promising and show that our OOV model is capable of generating reasonable and sometimes correct spelling of OOV words. We are currently still conducting experiments and assessing the performance of the OOV model in terms of word and letter error rate. So far, the OOV model is introducing a slight degradation in error rate compared to the baseline. Conclusions and Future WorkWe presented a grapheme-phoneme OOV model for detecting and spelling unknown words, and we compared its performance to a baseline which contains no OOV modeling showing that the model is in fact capable of generating adequate spellings of unknown words. We are still facing several challenges with the OOV model. First, although the model does not overfire, it sometimes fires at the wrong locations causing unknown words to be merged or split for example. Furthermore, the recognizer does not always do a good job at recognizing the underlying phonemes making it even harder to generate a correct spelling. So far, most of our approaches use the grapheme_phoneme units. However, we also have access to morphs units which only incorporate sound information. It would be interesting to implemented a morph OOV model and then generate a spelling from the morph sequence. Finally, the sub-word units used so far are obtained using a rule-based grammar. We also plan on investigating the performance of the recognizer with units derived using a data-driven approach. References:[1] I. Bazzi and J. R. Glass. Modeling Out-of-Vocabulary Words for Robust Speech Recognition. In The Proceedings of ICSLP, Beijing, China, October 2000. [2] M. Bisani and H. Ney. Open Vocabulary Speech Recognition with Flat Hybrid Models. In The Proceedings of Eurospeech, pp. 725--728, Lisbon, Portugal, September 2005. |
|||||||||||||
|