| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
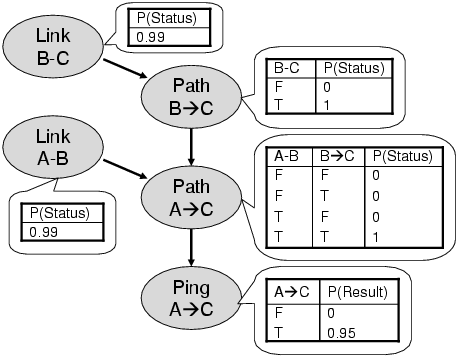
CAPRID: A Common Architecture for Autonomous, Distributed Diagnosis of Internet Faults using Probabilistic Relational ModelsGeorge J. LeeIntroductionInternet fault diagnosis requires the application of diagnostic knowledge, performing diagnostic tests, and distributed diagnostic reasoning. When a user reports a network fault such as an IP reachability failure to a network administrator, the administrator diagnosing the fault uses their diagnostic knowledge to identify the data they need for diagnosis. Then they perform diagnostic tests to collect data about the fault, using tools ranging from simple ping and traceroute measurements to sophisticated SNMP network management consoles. Next they interpret the results of these tests to infer possible causes of failure. Due to the distributed administration of the Internet and dependencies among network components, frequently the administrator may also need to coordinate with users and administrators in other domains to diagnose the failure. Finally, the administrator identifies the root cause of failure and informs the user. Today, humans perform all of the steps of diagnosis manually, but as the Internet grows in size and complexity this will become increasingly impractical. Though we have many tools for data collection[8][11] and sophisticated diagnostic reasoning[5], unfortunately we do not have a way to automate distributed Internet fault diagnosis using these tools. To address this problem we need a common architecture for distributed diagnosis of Internet faults using autonomous agents. Therefore we are developing the Common Architecture for Probabilistic Reasoning for Internet Diagnosis (CAPRID), which uses probabilistic relational models (PRMs)[4] to support autonomous diagnosis of IP reachability and other failures. Our research seeks to apply recent AI research in PRMs to provide a general yet expressive framework for autonomous distributed probabilistic diagnosis of Internet faults. Requirements of a Diagnostic ArchitectureAccurate diagnosis of network failures requires knowledge of the properties of both the classes of network components that might fail and the classes of tools available for testing these components. Network components include both processes such as TCP connections and devices such as Ethernet switches; diagnostic tests include both passive observations as well as active measurements. For example, to diagnose an IP path failure, one needs to know that an IP path failure results from a failure in one of the links along that path, and that a failed traceroute along an IP path can indicate a path failure. Today such knowledge mostly resides in the heads of network administrators; in order for autonomous agents to make use of such information we need a common language for expressing this diagnostic knowledge. Most previous architectures for exchanging diagnostic information in the Internet[10][9] do not support the communication of such high-level diagnostic knowledge. The high-level approach to diagnosis that we take in this paper fits with the concept of the Knowledge Plane[1], which aims to provide a common framework for exchanging and reasoning about network knowledge. Diagnostic agents also need a common language for expressing the diagnostic data produced by diagnostic tests and reasoning. A common language for expressing diagnostic data can unify the incompatible array of diagnostic tests and reasoning methods available today. Like the Internet Protocol (IP) that glues together heterogeneous link layer technologies to provide a standard interface for higher-level communication protocols and applications, a common language for diagnostic data glues together different methods for diagnostic tests and reasoning to provide a standard platform for distributed diagnosis. Simply exchanging low-level measurements such as packet round trip times or TCP traces is neither general nor expressive; instead, we need to translate such information into a meaningful high-level diagnostic language that can express statements such as "The link between A and B is down," or "A ping along the path from A to C failed." Diagnosis requires distributed probabilistic reasoning. Reasoning must be probabilistic because many diagnostic tests only indicate a probability of failure. Probabilistic systems that use centralized reasoning such as SCORE[6] are inadequate because diagnostic knowledge and data may be distributed across multiple administrative domains. In addition, an architecture for Internet-scale fault diagnosis must deal with the huge volume of diagnostic requests that may result from a serious high-impact failure that simultaneously affects a large number of users at a time when the network is already stressed. When such failures occur, agents must perform diagnosis without introducing network congestion or computational overhead. CAPRID: Common Architecture for Probabilistic Reasoning for Internet DiagnosisIn order to address the requirements above, we propose a Common Architecture for Probabilistic Reasoning for Internet Diagnosis (CAPRID) that provides a framework for distributed probabilistic diagnostic reasoning. Unlike previous architectures for Internet fault diagnosis, CAPRID represents diagnostic knowledge and data using probabilistic relational models (PRMs)[4], combining the strengths of probabilistic Bayesian inference with the descriptive power of first-order logic. Expressing Diagnostic Data using Bayesian NetworksBayesian networks compactly represent the conditional probability of related events and enable efficient inference based on available evidence[7]. Bayesian networks have several important features that make them especially suitable for reasoning about failures in the Internet. Firstly, Bayesian networks can model both deterministic and probabilistic dependencies among many types of Internet components and diagnostic tests. The variables in the Bayesian network represent component status and test results. Component status nodes in this Bayesian network represent the functional status of a component while test result nodes represent the output of a diagnostic test. Edges in the Bayesian network represent dependencies among component status and diagnostic test results. The CPT for a component status node represents the probability that it is functioning given the status of its parent components. The CPT for a test node indicates the probability of a successful test given the status of its parent components. Figure 1 illustrates a Bayesian network for IP path diagnosis.
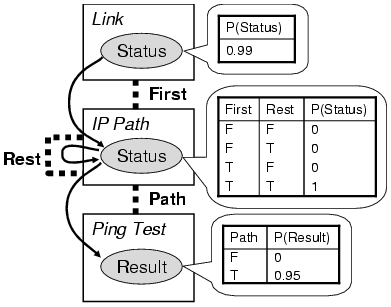
Bayesian networks provide an abstract high-level representation for diagnostic data suitable for reasoning while minimizing the cost of performing diagnostic tests. Representing diagnostic data in terms of variables, evidence, and dependencies rather than passing around low-level measurements such as packet traces allows an agent to reason about the causes and consequences of failures without any deep knowledge of the behavior and characteristics of components and diagnostic tests. In addition, when high-impact failures occur and an agent receives many failure requests with the same root cause, Bayesian inference enables an agent to infer the root cause with high probability without additional tests. The conditional independence assumptions of a Bayesian network facilitate distributed reasoning. For example, an agent can infer that an IP path has failed if that agent has evidence that a link along that path has failed without knowing the cause of the link failure. This structure minimizes the number of other agents with which an agent needs to communicate to infer a diagnosis. Thus each agent can maintain only a local dependency model and perform distributed inference using a variation of loopy belief propagation[2], requesting updated beliefs from other agents when new evidence becomes available. Expressing Diagnostic Knowledge using PRMsPRMs provide agents in CAPRID with a language for expressing shared diagnostic knowledge about component and test classes in a form suitable for Bayesian reasoning. A PRM defines classes and properties of individuals belonging to each class, together with parent relationships and CPTs for those properties. Figure~\ref{fig:rm} illustrates the PRM representing the diagnostic knowledge for IP path failures. The boxes in the figure represent classes, the entries within a box represent properties of individuals of that class, dotted lines represent foreign key relationships relating individuals of two classes, and arrows represent parent relationships. Using this PRM, an agent can construct a Bayesian network such as the one in Figure~\ref{fig:bn} using runtime dependency analysis and local information.
Diagnostic knowledge may come either from human experts or from Bayesian learning. For many component classes such as IP paths, CPTs simply deterministically encode truth tables for AND or OR. In such cases application developers or other experts can easily specify the CPT. Even if the exact conditional probabilities are unknown, however, agents can learn them collectively using Bayesian learning[4]. For extensibility to support new classes, CAPRID allows subclassing where each subclass may have a different CPT. For instance, rather than modeling all individuals belonging to the \emph{Link} class as having the same probability of failure, for increased accuracy we can distinguish between two subclasses \emph{Wired Link} and \emph{Wireless Link}. Agents can share knowledge of new classes to create a distributed, extensible ontology using the Web Ontology Language (OWL)[3]. Progress and Future WorkWe are currently conducting experiments on Planetlab to quantify the accuracy and communication cost of TCP path diagnosis in the Internet using CAPRID. The results of these experiments will help us better model the diagnostic data and knowledge agents need for autonomous diagnosis. In future work we plan to investigate the use of dynamic probabilistic relational models (DPRMs) for modeling temporal dependencies among components and diagnostic tests. References:[1] D. D. Clark, C. Partridge, J. C. Ramming, and J. T. Wroclawski. A Knowledge Plane for the Internet. In Proceedings of SIGCOMM '03, 2003. [2] C. Crick and A. Pfeffer. Loopy belief propagation as a basis for communication in sensor networks. In Proceedings of the 19th Annual Conference on Uncertainty in Artificial Intelligence (UAI-03), 2003. [3] M. Dean, G. Schreiber, S. Bechhofer, F. van Harmelen, J. Hendler, I. Horrocks, D. L. McGuinness, P. F. Patel-Schneider, and L. A. Stein. Owl web ontology language reference. W3C Recommendation, February 2004. [4] N. Friedman, L. Getoor, D. Koller, and A. Pfeffer. Learning Probabilistic Relational Models. In Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence (IJCAI-99), Stockholm, Sweden, August 1999. [5] S. Kandula, D. Katabi, and J.-P. Vasseur. Shrink: A Tool for Failure Diagnosis in IP Networks. In ACM SIGCOMM Workshop on mining network data (MineNet-05), Philadelphia, PA, August 2005. [6] R. R. Kompella, J. Yates, A. Greenberg, and A. C. Snoeren. IP Fault Localization via Risk Modeling. In Proceedings of the 2nd ACM/USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2005. [7] U. Lerner, R. Parr, D. Koller, and G. Biswas. Bayesian Fault Detection and Diagnosis in Dynamic Systems. In Proceedings of the Seventeenth National Conference on Artificial Intelligence (AAAI-00), pp. 531–537, Austin, Texas, August 2000. [8] N. Spring, D. Wetherall, and T. Anderson. Scriptroute: A public internet measurement facility. In Proceedings of USENIX Symposium on Internet Technologies and Systems (USITS), 2003. [9] D. G. Thaler and C. V. Ravishankar. An Architecture for Inter-domain Troubleshooting. Journal of Network and Systems Management, 12(2), 2004. [10] M. Wawrzoniak, L. Peterson, and T. Roscoe. Sophia: an information plane for networked systems. SIGCOMM Comput. Commun. Rev., 34(1):15--20, 2004. [11] M. Zhang, C. Zhang, V. Pai, L. Peterson, and R. Wang. Planetseer: Internet Path Failure Monitoring and Characterization in Wide-area Services. In Proceedings of Sixth Symposium on Operating Systems Design and Implementation (OSDI '04), 2004. |
|||||||
|