
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Probabilistic Models for Retrieving Fewer Relevant Documents in an Information Retrieval SystemHarr Chen & David R. KargerIntroductionTraditionally, information retrieval systems aim to maximize the number of relevant documents returned to a user within some window of the top. For such a purpose, the probability ranking principle (PRP), which ranks documents in descending order according to their probability of relevance, is (provably) optimal [3]. In many situations, however, such a single-minded fixation on retrieving many relevant documents can be counterproductive. In particular, it leads to all the top documents being quite similar, as they are all chosen independently to match the same criteria. It may be a waste of time to see so many similar documents. We see this phenomenon frequently at the Google search engine, which often reports that "similar documents have been omitted" from the top search results. Even worse, if the system's model of relevance is wrong, it will be wrong over and over again, returning an entire list of irrelevant documents. We are exploring retrieval methods that hedge their bets. Rather than seeking to maximize the number of highly ranked relevant documents, we aim to maximize the chances of finding some relevant documents near the top. This approach is driven by three, related issues. First, a system's best guess may simply be wrong. By seeking a diversity of answers, we hope to avoid "falling into a rut" and returning all irrelevant documents. Second, a system's best guess might be right, but only for a subset of the population. It is common wisdom that some queries such as "java" can express multiple, distinct information needs - about a programming language, a drink, or an island. Without knowledge of the user, it is hard to predict which answer is right. Third, a user may desire a survey of results related to a particular subject. A query for a song title on Google will often return multiple lyrics results, at the cost of other song-related information such as artist or album information. Our approach will implicitly aim to cover all the bases, providing some answers that are appropriate for each possible meaning of the query. We are also exploring in a more general sense the notion of optimizing for alternative objective functions. Some of the techniques we develop can be naturally viewed as optimizing for other metrics such as mean reciprocal rank and expected search length. ApproachWe explore hedged retrieval in the context of a typical Bayesian model of documents and relevance. Efficient algorithms for computing and ranking by individual probability of relevance are well known for the model [2]. We aim to develop corresponding metrics, objectives, and algorithms for maximizing the odds of overall relevance. As an example, let us consider a situation in which finding a single relevant document suffices. If we take ri to be the event that the ith document in a certain ordering is relevant, the probability ranking principle aims to order the documents according to decreasing Pr[ri], thus maximizing 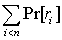 , ,
which is the expected number of relevant documents among the first n. However, if we postulate that one relevant document suffices, then finding more than one is a waste of time. It instead makes sense to maximize: 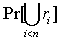 , ,
which is the probability that at least one document among the top n is relevant. Our objective functions can be formulated in a similar manner for the general case where we want some number k of the top n results to be relevant. In that case, the objective becomes a conjunctive normal form (CNF) expression of the relevance variables. Exact optimization of our objective function is intractible, because it involves computing a score for every size n result set, rather than just every document. Thus, we develop heuristics for approximating the optimum using a greedy algorithm. Rather than considering every possible result set in its entirety, we iteratively consider adding a result to the result set, and choosing documents that maximize our objective at each step. Intruigingly, our greedy algorithm can be seen as a kind of blind relevance feedback, in which we fill a position in the ranking by assuming that the previous documents in the ranking are some combination of relevant and irrelevant. ExperimentsWe have conducted experiments over standard TREC corpora and queries comparing our techniques against a standard PRP baseline. Our results show that the greedy optimization of our alternative objective function produces a result set that is more likely to have at least one relevant result, than the PRP baseline, when we direct our technique to maximize the probability of finding at least one relevant result. Similarly, when we maximize the probability of finding all relevant results, we are more likely to find a result set whose results are all relevant. The event of returning zero relevant documents, whose probability we try to minimize in the "one relevant result" case of our technique, is precisely one event that the TREC robust retrieval track set out to avoid [4]. Our experiments over this track show that we return more result sets with at least one relevant result. The improvements are especially pronounced over the subset of 50 queries that the TREC annotators labelled as "difficult." Related WorkIn recent work on subtopic retrieval, Zhai et al. posit, as we do, that there may be more than one meaningful interpretation of a query [5]. They assume that a query may have different subtopic interpretations, and reorder the results so that the top includes some results from each subtopic. Such an approach is particularly natural if we assume a user is seeking to explore the range of possible answers to their query. However, for a user seeking only "their" answer, such an approach is arguably overkill. Their system also involves separate consideration of novelty and redundancy in a result set, which are then combined via differential weighting. We aim for a more direct path that incorporates both variables into a single model. Carbonell and Goldstein argue for the value of diversity or "relevant novelty" in the results of a query, and propose the maximum marginal relevance (MMR) ranking function as an objective that introduces such diversity in a ranked result set [1]. When our objective is to maximize the odds of finding at least one relevant document near the top, our greedy heauristic for optimizing the objective simplifies to a computation that bears some relation to the MMR computation. However, unlike MMR which is advanced as a heuristic model for achieving the hard-to-define notion of diversity, our ranking function arises naturally from the application of a simple greedy heuristic algorithm to the optimization of a clear, formally defined objective - the probability of finding at least one relevant document. In addition, while the iterative greedy approach is implicit in the definition of MMR, our greedy approach is simply one heuristic applied to optimizing our well-defined objective function; we expect that better optimization algorithms might yield improved values for our objective, which should translate into improved retrieval performance. Research SupportThis work is partially supported by the HP-MIT alliance and MIT's Project Oxygen. Harr Chen is supported by a Department of Defense National Defense Science and Engineering Graduate Fellowship. References:[1] J. Carbonell and J. Goldstein. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of ACM SIGIR 1998, pages 335336, 1998. [2] D. D. Lewis. Naive (Bayes) at forty: The independence assumption in information retrieval. In Proceedings of ECML 1998, pages 415, 1998. [3] S. E. Robertson. The probability ranking principle in IR. In Readings in Information Retrieval, pages 281286. Morgan Kaufmann Publishers Inc., 1997. [4] E. M. Voorhees. Overview of the TREC 2003 robust retrieval track. In Proceedings of TREC 2003, pages 113, 2003. [5] C. Zhai, W. W. Cohen, and J. Lafferty. Beyond independent relevance: Methods and evaluation metrics for subtopic retrieval. In Proceedings of ACM SIGIR 2003, pages 1017, 2003.
|
|||
|