| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
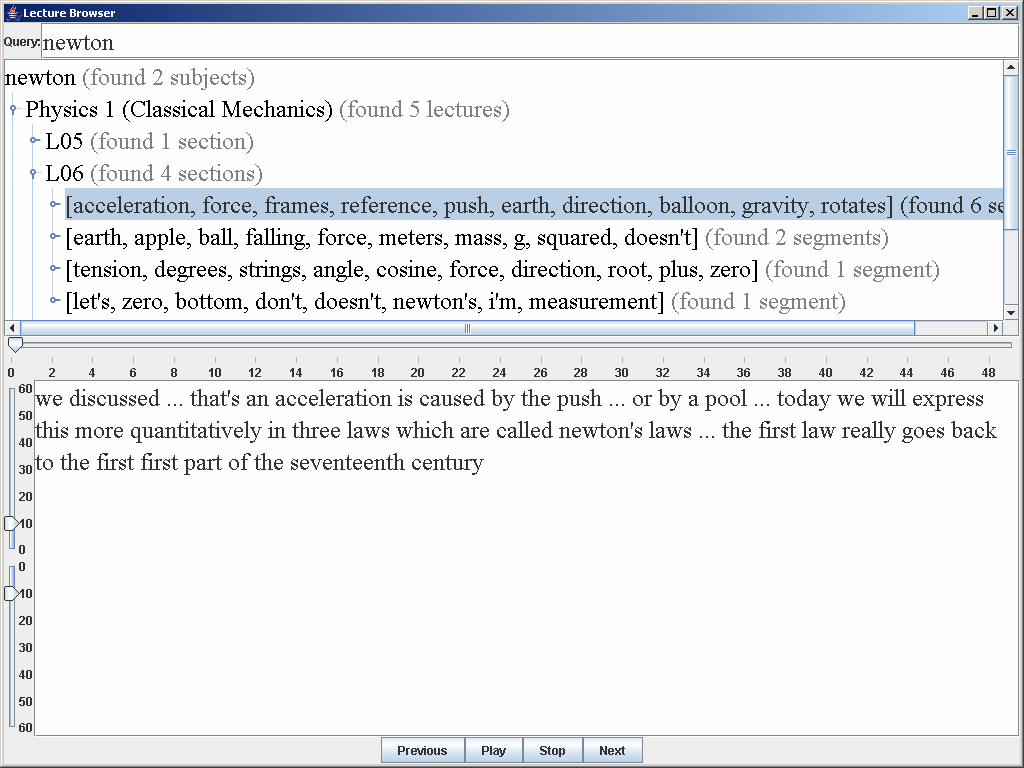
The MIT Spoken Lecture Processing ProjectJames R. Glass, Timothy J. Hazen, D. Scott Cyphers & Jason Katz-BrownIntroductionOver the past decade there has been increasing amounts of educational material being made available online. Projects such as MIT's OpenCourseWare provide continuous worldwide access to educational materials to help satisfy our collective thirst for knowledge. While the majority of such material is currently text-based, we are beginning to see dramatic increases in the amount of audio and visual recordings of lecture material. Unlike text materials, untranscribed audio data can be tedious to browse, making it difficult to utilize the information fully without time-consuming data preparation. Moreover, unlike some other forms of spoken communication such as telephone conversations or television and radio broadcasts, lecture processing has until recently received little attention or benefit from the development of human language technology. Lectures are particularly challenging for automatic speech recognizers because the vocabulary used within a lecture can be very technical and specialized, yet the speaking style can be very spontaneous. As a result, even if parallel text materials are available in the form of textbooks or related papers, there are significant linguistic differences between written and oral communication styles. Thus, it is a challenge to predict how a written passage might be spoken, and vice versa. By helping to focus a research spotlight on spoken lecture material, we hope to begin to overcome these and many other fundamental issues. While audio-visual lecture processing will perhaps be ultimately most useful, we have initially focused our attention on the problem of spoken lecture processing. Within this realm there are many challenging research issues pertaining to the development of effective automatic transcription, indexing, and summarization. For this project, our goals have been to a) help create a corpus of spoken lecture material for the research community, b) analyze this corpus to better understand the linguistic characteristics of spoken lectures, c) perform speech recognition and information retrieval experiments on these data to benchmark performance on these data, d) develop a prototype spoken lecture processing server that will allow educators to automatically annotate their recorded lecture data, and e) develop prototype software that will allow students to browse the resulting annotated lectures. Project DetailsAs mentioned earlier, we have developed a web-based Spoken Lecture Processing Server in which users can upload audio files for automatic transcription and indexing. To help the speech recognizer, users can provide their own supplemental text files, such as journal articles, book chapters, etc., which can be used to adapt the language model and vocabulary of the system. Currently, the key steps of the transcription process are as follows: a) adapt a topic-independent vocabulary and language model using any supplemental text materials, b) automatically segment the audio file into short chunks of pause-delineated speech, and c) automatically annotate these chunks using a speech recognition system. Language model adaptation is performed is two steps. First the vocabulary of any supplemental text material is extracted and added to an existing topic-independent vocabulary of nearly 17K words. Next, the recognizer merges topic-independent word sequence statistics from an existing corpus of lecture material with the topic-dependent statistics of the supplemental material to create a topic-adapted language model. The segmentation algorithm is performed in two steps. First the audio file is arbitrarily broken into 10-second chunks for speech detection processing using an efficient speaker-independent phonetic recognizer. To help improve its speech detection accuracy, this recognizer contains models for non-lexical artifacts such as laughs and coughs as well as a variety of other noises. Contiguous regions of speech are identified from the phonetic recognition output (typically 6 to 8 second segments of speech) and passed alone to our speech recognizer for automatic transcription. The speech segmentation and transcription steps are currently performed in a distributed fashion over a bank of computation servers. Once recognition is completed, the audio data is indexed (based on the recognition output) in preparation for browsing by the user. We have developed a lecture browser that provides a graphical user interface to one or more automatically transcribed lectures. An example screenshot of the browser is shown in the figure below. At the top of the browser, a user can type a text query to the browser ("Newton" in the example figure) and receive a list of academic courses containing the query terms ("Physics 1: Classical Mechanics" in the example). Each course can be expanded to show the individual lectures containing the query terms (lectures "L05" and "L06" in the example). Each lecture is further segmented into sections, which are displyed in the browser with relevant keywords (i.e., the highlighted section in the example is described by the keywords "acceleration", "force", "frames", etc.). Individual utterances containing the query terms can be selected and the automatically recognized transcript surrounding a selected utterance hit is displayed in the lower window. The user can adjust the duration of context preceding and following the hit, navigate to and from the preceding and following parts of the lecture, and listen to the displayed segment. Transcribed words are synchronously highlighted as they are played.
Figure: A screenshot of the MIT Audio Lecture Browser. Experimental ResultsTo date we have collected and analyzed a corpus of approximately 300 hours of audio lectures including 6 full MIT courses and 80 hours of seminars from the MIT World web site [2]. We are currently in the process of expanding this corpus. From manual transcriptions we have generated and verified time-aligned transcriptions for over 200 hours of our corpus, and we are in the process of time-aligning transcriptions for the remainder of our corpus. We have performed initial speech recognition experiments using 10 computer science lectures. In these experiments we have discovered that, despite high word error rates (in the area of 40%), retrieval of short audio segments containing important keywords and phrases can be performed with a high-degree of reliability (over 90% F-measure when examining precision and recall results) [2]. Additionally, word errors rates of under 20% can be achieved when large amounts of data from a speaker (i.e. a whole semester's worth of lectures) are available to adapt the recognizer's acoustic models. Ongoing WorkWe are currently in the process of developing a web-based version of our lecture browser which allows the user to play the videos of the portions of the lectures selected by the user. Our goal is to deploy this browser for public use in order to allow easier access to the videos contained on the MIT OpenCourseWare website. AcknowledgementSupport for this research was provided in part by the MIT/Microsoft iCampus Alliance for Educational Technology. References:[1] J. Glass, T. Hazen, L. Hetherington, and C. Wang, Analysis and processing of lecture audio data: Preliminary investigations. In Proceedings of the HLT/NAACL Speech Indexing Workshop, pp. 9-12, Boston, May 2004. [2] A. Park, T. Hazen, and J. Glass, Automatic processing of audio lectures for information retrieval: Vocabulary selection and language modeling. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, March 2005. |
|||
|