
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Minimum Cut Model for Spoken Lecture Topic SegmentationIgor Malioutov & Regina BarzilayIntroductionThe development of computational models of text structure is a central concern in natural language processing. Text segmentation is an important instance of such work. The task is to partition a text into a linear sequence of topically coherent segments and thereby induce a content structure of the document. The applications of the derived representation are broad, encompassing information retrieval, question-answering, and text summarization. Most unsupervised text segmentation algorithms assume that variations in lexical distribution indicate topic changes. When documents exhibit sharp variations in lexical distribution, these algorithms are likely to detect segment boundaries accurately. For example, most algorithms achieve high performance on synthetic collections, generated by concatenation of random text blocks [1]. The difficulty arises, however, when transitions between topics are smooth and distributional variations are subtle. This is evident in the performance of existing unsupervised algorithms on less structured datasets, such as spoken meeting transcripts [2]. Therefore, a more refined analysis of lexical distribution is needed. Our work addresses this challenge by casting text segmentation in a graph-theoretic framework. We abstract a text into a weighted undirected graph, where the nodes of the graph correspond to sentences and edge weights represent the pairwise sentence similarity. In this framework, text segmentation corresponds to a graph partitioning that optimizes the normalized-cut criterion [3]. This criterion measures both the similarity within each partition and the dissimilarity across different partitions. A robust analysis is achieved by jointly considering all the partitions in a document, moving beyond localized decisions. We show that the exact solution can be found in polynomial time, using dynamic programming. In general, the problem of minimizing normalized cuts is NP-complete, but for the case of chain graphs with a linearity constraint on the segmentation we formulate an exact dynamic programming solution. Previous WorkThere are two broad classes of algorithms devised for text segmentation: supervised, feature-based systems formulated in the discriminative framework [4, 5], and unsupervised systems based on the assumption of lexical cohesion within segments [1,6]. Our work fits most closely with this latter line of research. Most unsupervised algorithms assume that fragments of text with homogeneous lexical distribution correspond to topically coherent segments. The homogeneity is typically computed by analyzing the similarity in the distribution of words within a segment. Other approaches determine segment boundaries by locating sharp changes in similarity of adjacent blocks of text [7]. In contrast to previous approaches, the minimum cut algorithm simultaneously optimizes the similarity within each segment and the dissimilarity across segments. Thus, the homogeneity of a segment is determined not only by the similarity of its members, but also by their relation to other words in a text. We show that optimizing this objective refines the analysis of the lexical distribution and enables us to detect subtle topical changes. Another advantage of this formulation is its computational efficiency. Similarly to other segmentation approaches [1, 6], we employ dynamic programming to find the globally optimal solution. ApproachWhereas previous unsupervised approaches to segmentation rested on intuitive notions of similarity density, we formalize the objective of text segmentation through cuts on graphs. We aim to jointly maximize the intra-segmental similarity and minimize the similarity between different segments. In other words, we want to find the segmentation with a maximally homogeneous set of segments that are also maximally different from each other. Let The cut between two disjoint sets of nodes We consider the problem of partitioning the graph into disjoint sets
of nodes Papadimitriou proved that the problem of minimizing normalized cuts
on graphs is NP-complete [3]. However, in our case, the
graph assumes the form of a linear, fully-connected, chain of nodes and
the multi-way cut is constrained to preserve the linearity of the segmentation.
By segmentation linearity, we mean that all of the nodes between the leftmost
and the rightmost node of a particular partition have to belong to that
partition. With this constraint, we formulate a dynamic programming algorithm
for directly finding the minimum normalized multiway cut in polynomial
time. The time complexity of our dynamic programming algorithm is Experimental ResultsWe tested our algorithm on a corpus of spoken lectures. Segmentation in this domain is challenging in several respects. Being less structured than written text, lecture material exhibits digressions, disfluencies, and other artifacts of spontaneous communication. In addition, the output of speech recognizers is fraught with high word error rates due to specialized technical vocabulary and lack of in-domain spoken data for training. Finally, pedagogical considerations call for fluent transitions between different topics in a lecture, further complicating the segmentation task. Our first corpus consists of spoken lecture transcripts from an undergraduate Physics class taught at MIT. The Physics lecture transcript segmentations were produced by the teaching staff of the course. Their objective was to facilitate access to lecture recordings available on the class website. This segmentation conveys the high-level topical structure of the lectures.We have access both to manual transcriptions of these lectures and also output from an automatic speech recognition system, the SUMMIT segment-based Speech Recognizer [8]. We also evaluated our system on the lecture transcripts from the graduate Artificial Intelligence class taught at MIT. In order to evaluate our system, we compute the Pk measure, one of the more widely used metrics for assessing text segmentation performance [4]. Pk measure estimates the probability that a randomly chosen pair of words within a window of length k is inconsistently classified.
We use the state-of-the-art system by Utiyama and Isahara [6] as our point of comparison, which has been shown to outperform or compare favorably with other top-performing segmentation systems. Our system outperforms the baseline on both domains; the performance improvement is consistent across the two datasets (See Table 1). Another attractive property of the algorithm is robustness to noise: the accuracy of our algorithm does not deteriorate significantly when applied to automatically recognized speech. On the set of lecture transcripts obtained from a speech recognition system, our method achieved 0.311 Pk measure while manual transcripts yield 0.299 Pk measure (4% relative increase in Pk measure). The baseline system performance degrades from 0.311 to 0.352 Pk measure (13.2% relative increase). Considering long-distance lexical relations contributes to the effectiveness of the algorithm. Many other existing unsupervised segmentation algorithms are unable to exploit these non-local dependencies. We analyzed variations in the segmentation performance on a range of testing conditions. Not surprisingly, the performance of the algorithm depends on the distributional properties of the input text. We found that the segmentation accuracy on a synthetic text corpus is not predictive of the performance on the real data. These results strongly suggest that segmentation algorithms have to be evaluated on a collection of texts displaying real-world variability. SupportThis material is based upon work supported under a National Science Foundation Graduate Research Fellowship. Any opinions, findings, conclusions or recommendations expressed in this publication are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. References:[1] Freddy Y. Y. Choi. Advances in domain independent linear text segmentation. In Proceedings of the NAACL, pages 2633, 2000. [2] Michel Galley, Kathleen McKeown, Eric Fosler-Lussier, and Hongyan Jing. Discourse segmentation of multiparty conversation. In Proceedings of the ACL, pp. 562--569, 2003. [3] Jianbo Shi and Jitendra Malik. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence , 22(8):888905, 2000. [4] Doug Beeferman, Adam Berger, and John D. Lafferty. Statistical models for text segmentation. Machine Learning, 34(1-3):177210, 1999. [5] Rebecca J. Passonneau and Diane J. Litman. Discourse segmentation by human and automated means. Computational Lingustics, 23(1):103139, 1997. [6] Masao Utiyama and Hitoshi Isahara. A statistical model for domain-independent text segmentation. In Proceedings of the ACL, pp. 499-506, 2001. [7] Marti Hearst. Multi-paragraph segmentation of expository text. In Proceedings of the ACL , pages 916, 1994. [8] James R. Glass. A probabilistic framework for segment-based speech recognition. Computer Speech and Language, 17(23):137152, 2003. |
||||
|
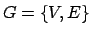 be an undirected,
fully-connected, weighted graph, where
be an undirected,
fully-connected, weighted graph, where 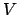 is the set of nodes corresponding to sentences in the text and
is the set of nodes corresponding to sentences in the text and 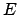 is the set of weighted edges. The edge weights,
is the set of weighted edges. The edge weights, 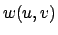 ,
define a measure of similarity between pairs of nodes
,
define a measure of similarity between pairs of nodes 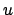 and
and 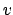 , where higher scores indicate higher
similarity.
, where higher scores indicate higher
similarity. 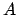 and
and 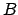 is defined to be the sum of the crossing
edges between the two sets of nodes:
is defined to be the sum of the crossing
edges between the two sets of nodes: 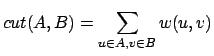 .
We need to ensure that the two partitions are not only maximally different
from each other, but also that they are themselves homogeneous by accounting
for intra-partition node similarity. We adopt the normalized cut on graphs,
introduced by Shi and Malik
.
We need to ensure that the two partitions are not only maximally different
from each other, but also that they are themselves homogeneous by accounting
for intra-partition node similarity. We adopt the normalized cut on graphs,
introduced by Shi and Malik 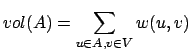 .
.
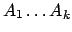 ,
which form a partition of the graph to minimize the normalized cut:
,
which form a partition of the graph to minimize the normalized cut: 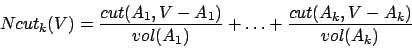 ,
where
,
where 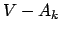 is the set difference
between the set of nodes in the entire graph and the set of nodes in partition
is the set difference
between the set of nodes in the entire graph and the set of nodes in partition
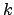 . By minimizing this objective we simultaneously
minimize the similarity across partitions and maximize the similarity
within partitions.
. By minimizing this objective we simultaneously
minimize the similarity across partitions and maximize the similarity
within partitions. 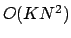 ,
where
,
where 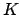 is the number of partitions and
is the number of partitions and
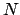 is the number of nodes in the graph or
sentences in the transcript.
is the number of nodes in the graph or
sentences in the transcript. 