
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Flexible Multi-Stream Framework for Speech Recognition Using Multi-Tape Finite-State TransducersI. Lee Hetherington, Han Shu, & James R. GlassIntroductionWe present a framework for modeling multiple streams of features within a speech recognition system with modeling expressed using multi-tape finite-state transducers [1]. Traditional speech recognition systems utilize a single stream of features, most often a fixed-rate sequence of observation vectors such as mel-frequency cepstral coefficients (MFCCs) and their derivatives modeled using Hidden Markov Models (HMMs). In contrast, our segmental speech recognition system, SUMMIT, utilizes two streams: (1) a variable-rate sequence of potential acoustic landmark features and (2) a graph of segmental features each from a starting landmark to an ending landmark [2]. One of our goals is to combine HMMs with our segmental models within an integrated search in order to achieve improved accuracies. Similarly, when performing audio-visual speech recognition (utilizing speech audio plus video of the mouth) [3], we again are faced with performing modeling on different feature streams and unifying the scores within a search. Note that when combining different feature streams, it can be quite important to allow some degree of asynchrony between the feature streams. For example, different model types may prefer different phonetic alignment [4], and video of speech may show the mouth and lips preparing for an upcoming sound. ApproachIn this work we present a framework to recognize an arbitrary number of feature streams (and graphs) within an integrated search while offering control over the degree of inter-stream asynchrony allowed. We utilize a multi-tape finite-state transducer (FST) representation, in which a tape is assigned to each feature stream, a tape is assigned to express the allowable degree of asynchrony among the streams, and the topology of the multi-tape FST determines the synchronization points. A dynamic-programming beam search is used to jointly find the optimal paths through the feature streams and the multi-tape FST. Consider the following two streams as might be used by our landmark and segmental system: 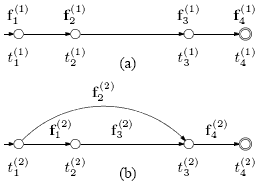
In (a), we have the landmark feature stream 1, in which fi(1) represents the feature vector at landmark i at time ti(1). In (b), we have the segment feature stream 2, in which fj(2) represents the feature vector for segment j and tk(2) represents the time of a segment boundary (or landmark) k. The multi-tape FST representing landmark and segment models for a single phone is as follows: 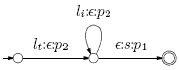
Here, lt and li represent phone-transition and phone-internal landmark models operating on stream 1, and s represents the phone segment model operating on stream 2. Synchronization is controlled by p1 and p2, with p1 enforcing hard synchronization at the end of each phone, in which both feature streams must be at exactly the same point in time. p2 is used as an optimization to eliminate cases where stream 1 gets too far ahead of stream 2 to pass p1 at the end of the phone. (We have simplified the FST in this figure and are not showing the word output or weight tapes.) ProgressWe have implemented this multi-stream representation within our segmental speech recognition system and performed a number of experiments with it. When combining traditional fixed-rate triphone HMM models with our variable-rate diphone landmark models, we have found that a suprisingly large degree of asynchrony between the two streams can be critical in achieving optimal performance: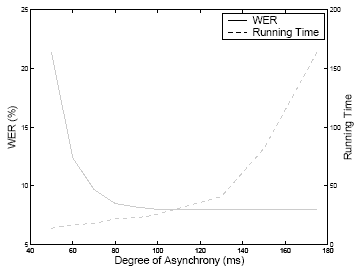
Here we see that up to 100ms of asynchrony at phone boundaries can be required to achieve the best combination of the two model types, and that increasing the degree of allowed asynchrony increases computation time due to the larger search space. The task is recognizing read speech from Wall Street Journal news articles with a 5,000-word vocabulary and bigram language model [5][6]. HMM only achieves 8.8% word error rate (WER), landmark only achieves 10.4% WER, and the combination with 95ms allowed asynchrony between the two achieves 8.0% WER. We have also applied the same framework to audio-visual speech recognition in which three streams are used: (1) landmarks, (2) segments, and (3) visual frames. With our more flexible framework, we achieve idential accuracy and similar speed to our group's previous system for performing such audio-visual recognition [3]. References:[1] I. L. Hetherington, H. Shu, and J. R. Glass. Flexible multi-stream framework for speech recognition using multi-tape finite-state transducers. In Proc. ICASSP, Toulouse, May 2006. [2] J. R. Glass. A probabilistic framework for segment-based speech recognition. In Computer Speech and Language, vol. 17, no. 2, pp. 137-152, 2003. [3] T. J. Hazen, K. Saenko, C. La, and J. R. Glass. A segment-based audio-visual speech recognizer: data collection, development, and initial experiments. In Proc. ICMI, State College, Pennsylvania, Oct. 2004. [4] D. T. Toledano, L. A. Hernández Gómez, and L. V. Grande. Automatic phonetic segmentation. In IEEE Trans. Speech and Audio Processing, vol. 11, no. 6, pp. 617-625, Nov. 2003. [5] F. Kubala, et al. The hub and spoke paradigm for CSR evaluation. In Proc. ARPA Human Language Technology Workshop, Princeton, pp. 37-42, Mar. 1994. [6] J. Odell. The Use of Context in Large Vocabulary Speech Recognition. Ph.D. thesis, Cambridge University, Cambridge, UK, 1995. |
|||
|