| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
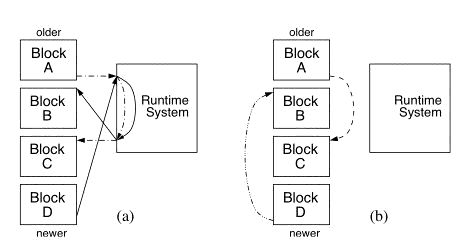
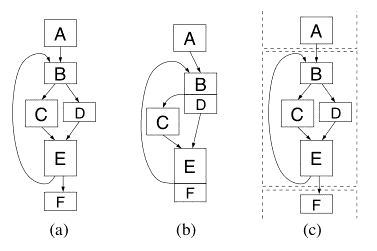
Software Based Instruction Caching for the Raw ArchitectureJason E. Miller, Paul R. Johnson & Anant AgarwalIntroductionInstead of a traditional instruction cache, the Raw architecture [1] provides an explicitly managed instruction memory on each tile. Instructions must be loaded into this memory (using a special store instruction) before they can be executed. How and when this takes place is up to the software running on each tile. This project seeks to design and implement a system which allows programs that are larger than the instruction memory to be run efficiently on Raw. The elimination of instruction cache hardware saves both area and design verification time but also provides us with an opportunity to customize cache behavior to an individual program. If the caching system is integrated with each program, its operation can be optimized for that particular program's needs. This customization could take the form of static, off-line analysis and modification in, for example, a compiler or binary rewriter. It could also take the form of a run-time system which dynamically monitors and optimizes code based on actual execution. In fact, there is no reason why both of these choices couldn't be combined and operate together. ApproachConceptually, a cache works by providing data from a local buffer when it is available and retrieving it from a larger, distant memory when it is not. A hardware cache operates by checking every address that is requested to see if it is present in the cache. In a software based system, it would be impractical to perform this check for every instruction of the user program. For every useful instruction executed, several instructions of overhead would be required. Therefore, we divide the user program up into blocks which are loaded into the cache as a unit. As long as execution proceeds within a block, no checks are needed. Only when the flow of control leaves a block is it necessary to check to see if the next block has already been loaded. This model is a good fit for an instruction cache where execution normally proceeds sequentially but is interrupted by an occasional change of direction. The system we have implemented is composed of two components: a binary rewriter and a small run-time system. The rewriter takes a normally compiled program and modifies it to make use of the run-time system. It breaks the program up into blocks and alters instructions which could cause execution to leave a block. These can include jumps and branches as well as "fall-through" instructions where execution simply proceeds sequentially off the end of a block. Such instructions are modified to transfer control to the run-time system instead of their intended destination. In making these modifications, the rewriter must also make sure that the original flow of control can be reconstructed by the run-time system later on. In our case, the original destination addresses of modified instructions are stored in a table which becomes part of the rewritten program. The run-time system is responsible for managing the instruction memory as a cache during program execution. It keeps track of the blocks that are currently in the instruction memory and loads new blocks in as needed. It must decide how to arrange these blocks in instruction memory and how to evict blocks when the memory is full. Because all of these operations are performed in software, it is not practical to directly emulate the behavior of hardware caches. For example, hardware can perform searches by checking tags in parallel and then choosing the one that matches while software must check the tags one at a time. On the other hand, using software may create the opportunity to use different, possibly more complex, schemes than hardware would allow. A software scheme has the full power of the processor core at its disposal to make decisions. ProgressA complete system has been implemented and is being used in the Raw group. It supports both compiler and hand generated programs. There is also support for interrupts and pinning code down within the cache. We have implemented several optimizations and are currently able to provide performance within 9% of a hardware cache of several benchmarks. In the current implementation, each cache block contains one basic block from the original program. A basic block has the nice property that all of its code is executed sequentially. Each block can only contain one control transfer instruction (e.g. a jump or branch) and it must be at the end. This makes it simple to identify and rewrite all the instructions which might cause execution to leave each block. The problem with basic blocks is that they can be any size. To simplify bookkeeping and avoid memory fragmentation, a fixed size cache block is desirable. Therefore, small basic blocks are padded with NOPs and large basic blocks are broken into smaller ones until they are all the same size. The run-time system is implemented as a library which is linked into the rewritten program. It allows blocks to be placed in any slot within the instruction memory (a fully-associative cache) and maintains the list of currently loaded blocks in a hash table. We have implemented two different replacement policies: FIFO and flush. Blocks are placed into the cache sequentially as they are loaded from DRAM. When the cache fills, the FIFO version evicts the oldest block. The flush version empties the entire cache and starts fresh. To reduce run-time overhead, we have implemented an optimization called chaining [2] which rewrites calls to the run-time system so that they jump directly to the appropriate block if that block is known to be in the cache (see Figure 1). Using the FIFO replacement policy, if the block that is chained to is evicted, the modified jump must be changed back into a jump to the run-time code. Using the flush policy greatly reduces the required bookkeeping because chains never need to be undone. The key to good performance is chaining as many jumps as possible since calls to the run-time system are very expensive, even in the case of a cache hit. Therefore, most of our optimizations have focused on chaining various different types of jumps. Because accessing the instruction memory does not require a tag check (as accessing a hardware cache does) it is inherently more energy-efficient than a hardware cache. However, the software caching system must execute extra instructions which consume additional energy. Our studies show that the break-even point is at roughly 10%. In other words, if a software cache has less than 10% performance penalty versus a hardware cache, it will consume less total energy for a given computation. Our current system can achieve as much as 3% energy savings on some benchmarks. FutureAlthough basic blocks are an easy choice for cache blocks, their average length is only about 6 instructions, creating frequent calls to the run-time system. There are many other possible ways to form cache blocks which may reduce the frequency of such calls. As a simple example, consider a basic block which ends with a conditional branch. In the existing system, the "fall-through" case of the branch is another block. However, these two blocks could be fused together to form extended basic blocks (Figure 2b) where only the "taken" case of the branch creates a call to the run-time system. Going even further, we could imagine creating clusters of basic blocks (Figure 2c) which contain their own control-flow sub-graphs. Branches within the block would incur no cache overhead. Similarly, there are other choices for replacement policy, bookkeeping data structures and cache block sizes. In the existing system, we have found that it is very inefficient to have a single, fixed size for blocks. Blocks which contain only one or two instructions waste a huge amount of space while breaking up large blocks creates extra, unnecessary calls to the run-time system. We would like to investigate different methods of using variable-sized blocks to increase efficiency. Other topics we plan to explore are: dynamic run-time optimizations, additional customization to individual programs and simple architectural changes to assist software instruction caching. Research SupportThis research is supported by DARPA, the NSF and the Oxygen Alliance. References:[1] Michael B Taylor, Jason Kim, Jason E Miller, David Wentzlaff, et al. The Raw microprocessor: A computational fabric for software circuits and general-purpose programs. In IEEE Micro, vol. 22, no. 2, pp. 25--35, March 2002. [2] Robert F Cmelik and David Keppel. Shade: A Fast Instruction-Set Simulator for Execution Profiling. Technical Report UWCSE 93-06-06, University of Washington, 1993. |
|||
|