| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
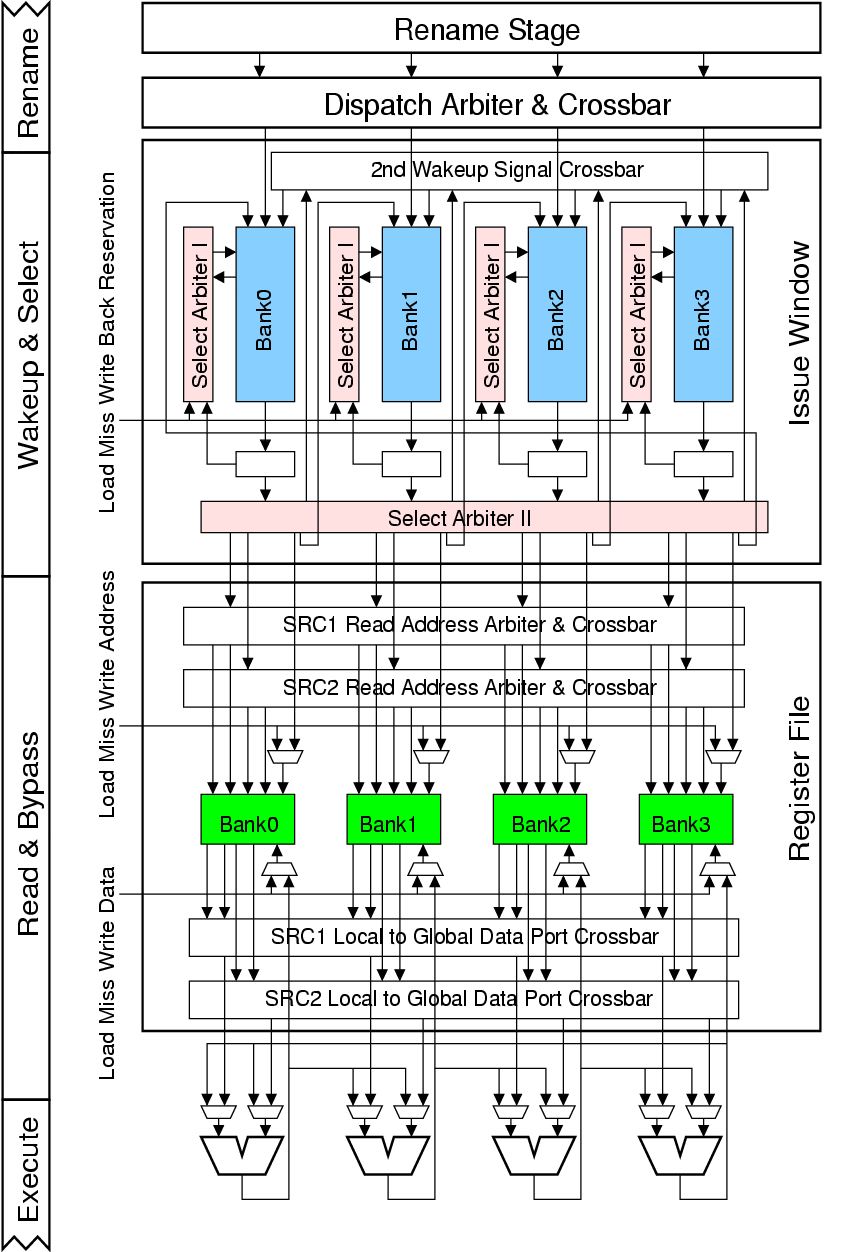
RingScalar: A complexity-Effective Out-of-Order Superscalar MicroarchitectureJessica Tseng & Krste AsanovicIntroductionOut-of-order superscalar microarchitectures provide high single-thread performance, but at a significant cost in area and power. This overhead is due to large centralized structures with global communications, including issue windows, register files, and bypass networks. These structures scale poorly to future technologies, which have increasing global interconnect delay and rising leakage power. The advent of chip-scale multiprocessors, which integrate multiple cores per die, provides additional motivation to improve the area and power efficiency of each core. Conventional superscalars use fully orthogonal structures, which simplify control logic but which are over-engineered for typical usage. For example, it is well known that register file read ports are underutilized because the bypass network supplies many values and that issue window source tags are underutilized because many operands are ready before the instruction is dispatched into the window. Several proposals have attempted to reduce the cost of one component of a superscalar architecture (e.g., just the register file or just the issue window), but often with a large increase in overall pipeline control complexity or possibly needing compensating enhancements to other portions of the machine (e.g., extending the bypass network to forward values queuing to use limited regfile write ports). We introduce ``RingScalar'', a new centralized out-of-order superscalar microarchitecture that simplifies all the major components in the instruction flow to increase area and power efficiency without excessive pipeline control complexity. RingScalar builds an N-way superscalar from N columns, connected in a unidirectional ring. Each column contains a portion of the issue window, a bank of the physical register file, and an ALU. Most communication is kept within a column to reduce global interconnect costs and the number of ports on each component. The restricted ring topology reduces electrical loading on latency-critical communications between columns, such as instruction wakeup and value bypassing. We exploit the fact that most decoded instructions are waiting on only one operand to use just a single source tag in each issue window entry, and dispatch instructions to columns according to data dependencies to reduce the performance impact of the restricted communication. Detailed simulations of the SPECint2000 benchmarks on four-issue machines show that a RingScalar design has an average IPC only 13% lower than an idealized superscalar, while having much reduced area, power, and circuit latency. RingScalar OverviewThe RingScalar design builds upon earlier work in banked register files [3], tag-elimination [1], and dependence-based scheduling [2]. The overall structure of the RingScalar microarchitecture is shown in Figure 1. RingScalar divides an N-way issue machine into N columns connected in a unidirectional ring. Each column contains a portion of the issue window, a portion of the physical register file, and an ALU. Physical registers are divided equally among the columns, and any instruction that writes a given physical register must be dispatched and issued in the column holding the physical register. This restriction means each bank of the regfile needs only a single write port directly connected to the output of the ALU in that column.
A second restriction is that any instruction entering the window while waiting for an operand must be dispatched to the column immediately to the right of the column containing the producer of the value (the leftmost column is considered to be to the right of the rightmost column in the ring). This restriction has two major impacts. First, when an instruction executes, it need only broadcast its tag to the neighboring column which reduces the fanout on the tag wakeup broadcast by a factor of N compared to a conventional window. Second, the bypass network can be reduced to a simple ring connection between ALUs as any other value an instruction needs should be available from the register file. The bypass fanout is reduced by a factor of N, and each ALU output now only has to drive the regfile write port and the two inputs of the following ALU. These restrictions are key to the microarchitectural savings in RingScalar. To evaluate the impact on instructions per cycle (IPC) of RingScalar, we modified the SMTSIM [4] simulator, a cycle-accurate simulator that models an out-of-order superscalar processor with simultaneous multithreading. The SPEC CINT2000 benchmarks compiled with optimization for the Alpha instruction set were used to evaluate performance. Progress and Future WorkWe have finished the modeling of RingScalar and evaluated it with SPEC CINT2000 benchmarks. Compared with idealized superscalar architectures, there is only a small (10.3-13.3%) drop in IPC but with a large reduction in area, power, and latency of the issue window, register file, and bypass network. RingScalar should be even more competitive against realistic conventional superscalar processors, and should provide a suitable design point for CMP cores that need both high single thread performance and lower power and area. Research SupportThis work was funded in part by an NSF graduate fellowship, NSF CAREER award CCR-0093354, and DARPA HPCS/IBM PERCS project. References[1] D. Ernst and T. Austin. Efficient Dynamic Scheduling Though Tag Elimination. In 29th International Symposium on Computer Architecture, Anchorage, AK,May 2002. [2] S. Palacharla, N. Jouppi, and J. Smith. Complexity-Effective Superscalar Processors. In 24st International Symposium on Computer Architecture, Denver, CO, June 1997. [3] J. Tseng and K. Asanovic. A Speculative Control Scheme for an Energy-Efficient Banked Register File. In IEEE Transactions on Computers, 54(6):741-751, June 2005. [4] D. Tullsen, S. Eggers, and H. Levy. Simultaneous multithreading: Maximizing on-chip parallelism. In 22nd International Symposium on Computer Architecture, Santa Margherita Ligure, Italy, June 1995. |
||||
|