| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
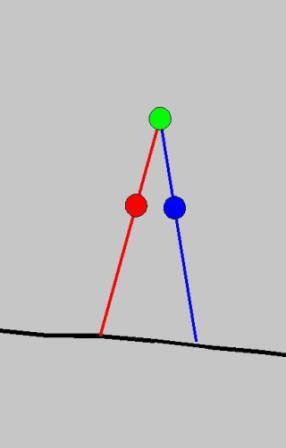
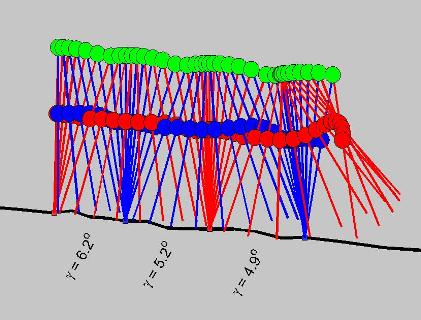
Biped Locomotion in Uncertain EnvironmentsKatie Byl, Arlis Reynolds, Stephen Proulx & Russ TedrakeOverviewRobotic biped locomotion is a difficult problem for several reasons. Walking is underactuated: the stance leg acts as a pivot about which the walker falls forward at each step. In contrast, a typical robotic arm is fully actuated and can freely control each degree of freedom independently. Environmental uncertainties for a real-world walker (such as the upcoming profile and compliance of terrain) are more unpredictable and can have greater impact on the dynamics as compared to the disturbances a robotic arm typically experiences in a factory setting, and efficiency becomes more critical for a machine that must carry its own power source as it travels. The underactuation of the process makes implementing traditional multi-link robot control in uncertain real-world environments quite challenging. We believe (as do many researchers in locomotion) that efficient biped walking will instead best be achieved by exploiting the inherent coupling between degrees of freedom rather than "cancelling" them (as one would for a robot arm or a walker such as ASIMO). This is a biomimetic strategy: there is strong evidence that human walking also exploits the coupled pendulum dynamics of the stance and swing legs, and mechanical walking machines which have been built on these "passive dynamic" principles often exhibit very natural (human-like) gaits. Our biped research attacks this problem of developing efficient and robust biped walking from several directions: (1) Theory (2) Control (using Reinforcement Learning) and (3) Experimental Verification. Theoretical AnalysisWe seek to establish a better analytical understanding of the passive (unactuated) dynamics of the system, particularly when subjected to disturbance forces and/or uncertain terrain. The basic model we are using, shown in Figure 1, is the "compass gait" walker, so named because it resembles a compass. It has two straight legs with distributed masses and a single pivot. Given appropriate initial conditions, such a device can walk down a small, even slope forever: it reaches a steady limit cycle where the energy lost at each foot impact is exactly recovered by the change in potential energy (height) of each step. However, motions on a rough surface, like the one depicted in Figure 1, will be less predictable. This is a 2D theoretical model of walking which assumes all motion is constrained to a single plane; a real walker must also maintain lateral stability to avoid falling. Another piece of this work is to appropriately quantify what "stability" means for walking in uncertain environments. For instance, we suggest that measuring performance in terms of actual expected number of steps taken (or "mean first passage time" until falling) provides a more meaningful metric than less-direct methods now used, which depend on instantaneous (geometric) measures [e.g. "center of mass" location or the "zero moment point"] which do not incorporate the inherent stability (or its lack) of the coupled-dynamic system as a whole in judging the stability of a walking gait. We view successful walking as a "metastable" state: a state which is expected to persist for a very long time but which is also expected to fail occasionally, given large enough disturbances from the environment (and cannot therefore be defined as strictly "stable"). While any one walker design may not be guaranteed to continue walking forever given any eventuality, some walkers can be expected to perform much better than others. We wish to quantify the baseline stability of a passive walker both (1) to provide a benchmark against which we can judge the performance of an actuated and actively-controlled walker and also (2) to identify how particular (passive) mechanical designs can enhance the stability of the compass gait, and to develop these results into principles for creating inherently stable mechanical biped design. Control Using Reinforcement LearningCreating control policies for these non-linear systems is a challenge of its own. Linearization about a particular path of expected operating points only suffices if disturbance forces or uncertainties (in sensor information or upcoming terrain) can be guaranteed to be sufficiently small. But a real-world walker must expect the unexpected. This requires knowledge of a "policy" to deal with the types of uncertainties (tripping, slipping, etc) one expects with walking, rather than a less flexible "plan" which depends on staying closely on-track to one particular path of motion. As an analogy, imagine you have learned an effect plan for driving in a car from point A to point B in a particular city. You can negotiate small deviations (passing other traffic, stopping at stop lights, etc), but if a road is closed, you are now forced either to find an alternate route to avoid failure. Having a policy is more robust than a plan, for it allows you to deal with unexpected eventualities that would have resulted in failure if you were forced to stray from the "plan" you would ideally wish to take. Reinforcement learning can be employed to learn a policy for selecting control actions. As a walker is exposed to a variety of disturbances (walking on carpet instead of tile flooring, recovering from a push, etc), it can test and evaluate the performance of various actions to compile a policy for acting that does not rely on sticking to one specific plan-of-action for success. Experimental HardwareTo test the validity of our theoretical models, we are building two robots, shown in Figure 2. Locomotive power for each robot is provided through a torque source at the pivot between the legs (which we refer to as the "hip"). The first of these hip-actuated walkers has curved feet, to provide added stability from falling. Because it is actuated with a geared motor, there is a clutch which can disengage the coupling between the motor and legs, allowing the robot to take advantage of the passive dynamics during particular phases of the gaits. The second robot has point feet, to more closely match the idealized compass gait model of walking. It employs a direct-drive (backdriveable) motor transmission to permit us to apply smaller (more efficient) perturbations to the natural, passive gait than a geared motor would. To provide lateral (side-to-side) stability, this walker will be mounted on a rotating boom. The feet have retractable tips (to avoid "scuffing" during the swing phase of the gait). We are particularly eager to quantify the performance of these underactuated walkers on bumpy terrain. We hope to use both the rough terrain and the motion capture capabilities provided through our in-lab Little Dog project to test the walkers and to record motions of the walker in all degrees of freedom. References:[1] Katie Byl and Russ Tedrake. Stability of passive dynamic walking on uneven terrain. (abstract) In The Proceedings of Dynamic Walking 2006, Ann Arbor, Michigan, May 2006. [2] Steven H. Collins, Andy Ruina, Russ Tedrake, and Martijn Wisse. Efficient bipedal robots based on passive-dynamic walkers. Science, 307:1082-1085, February 18 2005. |
|||
|