| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Branch Trace Compression for Snapshot-Based SimulationKenneth C. Barr & Krste AsanovicIntroductionAs full-system simulation of commercial workloads becomes more popular, methodologies such as statistical simulation and phase detection have been proposed to produce reliable performance analysis in a small amount of time. With such techniques, the bulk of simulation time is spent fast-forwarding the simulator to relevant points in a program rather than performing detailed cycle-accurate simulation. To amortize the cost of lengthy fast-forwarding, snapshots can be captured at each sample point and used later to initialize different machine configurations without repeating the fast-forwarding. If the snapshot contains just register file contents and memory state, one must perform lengthy "detailed warming" of caches and branch predictors to avoid cold-start bias in the results. Microarchitectural state can also be captured in the snapshot, but this will then require regeneration of the snapshot every time a microarchitectural feature is modified. Ideally a snapshot should contain information about microarchitectural state, yet be independent of microarchitecture so that, once generated, the snapshot is sufficient to perform evaluations of many configurations. A lengthy warming period is replaced with a quick reconstruction period during which information from the snapshot is interpreted according to the concrete microarchitectural structures under evaluation. For caches, various microarchitecture-independent snapshot schemes have been proposed, which take advantage of the simple mapping of memory addresses to cache sets. Branch predictors, however, are much more difficult to handle in the same way, as they commonly involve branch history in the set indexing function which smears the effect of a single branch address across many locations in a branch predictor. One possibility is to store microarchitectural state snapshots for a set of of potential branch predictors, but this limits flexibility and increases snapshot size, particularly when many samples are taken of a long-running multiprocessor application. We explore an alternative approach in this paper, which is to store a compressed version of the complete branch trace in the snapshot. This approach is microarchitecture-independent because any branch predictor can be initialized before detailed simulation begins by uncompressing and replaying the branch trace. The main contribution of our paper is a branch predictor-based compression scheme (BPC), which exploits software branch predictors in the compressor and decompressor to reduce the size of the compressed branch trace snapshot. When BPC is used, the snapshot library can require less space than one which stores just a single concrete predictor configuration, and it allows us to simulate any sort of branch predictor. This work was presented at ISPASS 2006 [1]. Copies of the paper and presentation slides are available at the SCALE group webpage. DesignBPC uses a collection of internal predictors to create an accurate, adaptive model of branch behavior. A software branch predictor has two obvious advantages over a hardware predictor. First, the severe constraints that usually apply to branch prediction table sizes disappear; second, a fast functional simulator can provide oracle information to the predictor such as computed branch targets and directions. When the model correctly predicts many branches in a row, those branches need not be emitted by the compressor; instead, it concisely indicates the fact that the information is contained in the model. The output of the compressor is a list of pairs. The first element indicates the skip amount, the number of correct predictions that can be made beginning with a given branch; the second element contains the data for the branch record that cannot be predicted. We store the output in two separate files and use a general-purpose compressor called PPMd [3] to catch patterns that we have missed and to encode the reduced set of symbols. The decompressor reads from these files and outputs the original branch trace. After reversing the general-purpose compression, the decompressor first reads from the skip amount file. A positive skip amount, x, indicates that BPC's internal predictors are sufficient to produce x correct branch records in a row. When x=0, the unpredictable branch may be found in the branch record file. As the decompressor updates its internal predictors using the same rules as the compressor, the state matches at every branch, and the decompressor is guaranteed to produce correct predictions during the indicated skip intervals. We define a concrete branch predictor to be a predictor with certain fixed parameters such as size of global history, number of branch target buffer entries, etc. To measure the performance of various concrete branch predictors, the output of the BPC Decompressor is used to update state in each concrete predictor according to the update policies of that predictor. EvaluationTo evaluate BPC, we use the 20 traces from the Championship Branch Prediction (CBP) competition [4]. The trace suite comprises four categories: integer, floating point, server, and multimedia. Traces contain approximately 30 million instructions comprising both user and system activity and exhibiting a wide range of traits in terms of branch frequency and predictability. The state of a given branch predictor (a concrete snapshot in our terminology) has constant size of q bytes. However, to have m predictors warmed-up at each of n detailed sample points (multiple short samples are desired to capture whole-program behavior), one must store mn q-byte snapshots. Concrete snapshots are hard to compress so p, the size of q after compression, is roughly constant across snapshots. Since a snapshot is needed for every sample period, we consider the cumulative snapshot size: mnp. In our experiments, cumulative snapshots grow faster than a BPC-compressed branch trace even for reasonable p and m=1. On average, BPC+PPMd provides a 3.4x, 2.9x, and 2.7x savings over a
concrete snapshot compressed with gzip, bzip2, and PPMd respectively.
When broken down by workload, the savings of BPC+PPMd over concrete+PPMd
ranges from 2.0x (integer) to 5.6x (floating point). Note that this represents
the lower bound of savings with BPC: if one wishes to study m
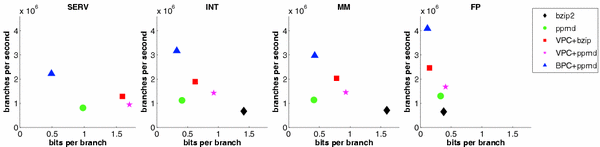
branch predictors of size Figure 1 summarizes space and time results of our experiments with one plot for each application category. The most desirable techniques, those that decompress quickly and yield small file sizes, appear in the upper left. For each application domain, BPC+PPMd performs the fastest. In terms of bits-per-branch, BPC+PPMd is similar to VPC [2] for highly-compressible floating point traces and similar to PPMd for integer benchmarks. For multimedia, PPMd alone edges-out BPC+PPMd, while BPC+PPMd performs significantly better than all its peers for hard-to-predict server benchmarks. BPC decompression also outpaces fast functional simulation (not shown) by 3x (integer) - 12x (floating point). High speed and small files across application domains are the strengths of our technique.
Related workValue-predictor based compression (VPC) is a recent advance in trace compression [2]. Its underlying predictors are more general than BPC's branch direction and target predictors. With its specialized predictors and focus on chains of correct predictions, we have found that BPC compresses branch trace data better than VPC in 19/20 cases and is between 1.1x and 2.2x faster. CBP uses a simpler set of branch predictors than BPC to generate and read compressed traces. Though it uses similar techniques, direct comparison is not possible as CBP obtains near-perfect program counter compression due to the interleaving of non-branch instructions. With perfect PC prediction, CBP+bzip2 outperforms BPC in 10/20 cases, but when perfect prediction is not allowed, BPC produces smaller files. FundingThis work was partly funded by the DARPA HPCS/IBM PERCS project, NSF CAREER Award CCR-0093354, and an equipment grant from Intel Corp. References[1] Kenneth C. Barr and Krste Asanovic. Branch trace compression for snapshot-based simulation. In Int'l Symp. on Perf. Analysis of Systems and Software, Mar. 2006. [2] Martin Burtscher, Ilya Ganusov, Sandra J. Jackson, Jian Ke, Paruj Ratanaworabhan, and Nana B. Sam. The VPC trace-compression algorithms. IEEE Trans. on Computers, 54(11), Nov. 2005. [3] Dmitry Shkarin. PPM: one step to practicality. In Data Compression Conf., 2002. [4] Jared W. Stark, Christopher Wilkerson, et al. The 1st JILP championship branch prediction competition. In Workshop at MICRO-37 and Journal of ILP, Jan. 2005. http://www.jilp.org/cbp |
|||||
|
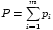 ,
the size of the concrete snapshot will grow with mnP, while the
BPC trace supports any set of predictors at its current size.
,
the size of the concrete snapshot will grow with mnP, while the
BPC trace supports any set of predictors at its current size.