
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Transcription of Acoustic Mixtures and Robust Speech RecognitionKen Schutte & James GlassIntroductionThe vast amount of audio data being created by new portable devices offers a wealth of information, but much will be largely useless without effective indexing to allow for search. One major difficulty in dealing with such real-world recordings is that of transcribing overlapping events, or acoustic mixtures. Standard automatic speech recognition (ASR) approaches begin with the fundamental assumption that the problem is one of sequence labeling - where the output is assumed to be a linear string of labels. However, real-world acoustic events almost never occur in complete isolation, and thus this sequence labeling paradigm immediately removes the ability to fully "describe" (or transcribe) the majority real-world auditory scenes. It could also be argued that the long-standing problem of noise robust speech recognition should (for many realistic noise sources) be treated as a special case of this problem, in which both the "noise" and the speech are tracked simultaneously as two additive sources in a mixture. Even when knowledge of only one source is desired, performance could be improved by exploiting patterns in the interference. MotivationThe methods being explored are motivated by observing two major properties of signals of interest (such as speech): sparsity and redundancy [1]. The speech signal is sparse in the sense that much of its energy is contained in a small percentage of time-frequency (T-F) cells. Even when noise is added at a low global signal-to-noise ratio (SNR), these regions of T-F will retain a favorable local SNR (often close to the level of clean speech). To illustrate, Figure 1 shows the distribution of local SNR for a two speaker mixture with 0 dB global SNR for a range of sizes of T-F cell. Secondly, the redundancy of the speech signal implies that decoding might be possible using only a relatively small proportion of all T-F cells (presumably those with high local SNR). The redundancy of speech has been well documented by recording human intelligibility after various methods of filtering and masking have blocked portions of the T-F plane [2]. 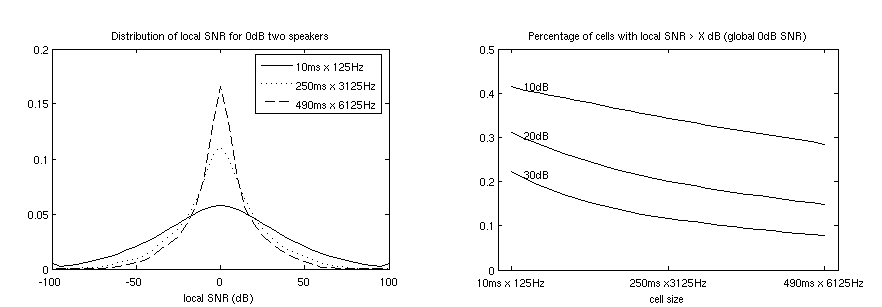 Figure 1. Distribution
of local Signal-to-Noise Ratio (SNR) for two speech utterances added at
0 dB global SNR. "Cell sizes" were generated by applying a moving average
filter to a narrowband spectrogram. The filter size was varied while keeping
a fixed time-freq ratio (12.5Hz/ms).
This motivates an approach to speech recognition which is robust to additive noise that is based not on finding inherently robust features, or suppressing/removing interference; rather, one that is based on focusing recognition around those "glimpses" of the target signal which are largely unaffected by interference. Recent work has shown the promise of this method for machine recognition of noisy speech, as well as suggest a model for human speech perception which fits closely to measured human performance [1]. General Framework for Acoustic MixturesWith these properties in mind, acoustic mixtures may be dealt with by considering binary spectral masks which specify the reliable T-F regions for each source in the mixture. Subjective listening on a wide variety of mixtures of speech, music, tones, noise, etc, suggests that for realistic N-source mixtures, there does exist a set of N binary spectral masks which both (a) removes essentially all information from interfering sources, while (b) retaining the essential information of the target source. While this is only a subjective observation, it suggests that the seemingly daunting task of decoding an N-source mixture can be reduced to three distinct (yet inter-related) problems:
Now, the "decoders" (e.g. an ASR system for speech sources) need not be robust to additive interference. The masking step has (presumably) produced a single isolated source (perhaps with missing data). Top-down mask estimationThe estimation of binary time-frequency masks has been proposed as the goal of computational auditory scene analysis [3]. While there have been a variety of proposed methods of estimating spectral masks [7,8], few have effectively utilized high-level information and approached the problem from the general case of multiple sources. Again considering the "glimpsing" model described above, it is likely that there are regions where a good initial hypothesis can be made. If so, it may be possible to use high-level information (for example in the form of an ASR system) to extrapolate the hypothesis into corrupted regions, thus providing some information to estimate masks. In a purely top-down approach to mask estimation, knowledge about one (or more) of the sources is used to estimate reliable T-F regions, and the N-source decoding problem is reduced to two steps (temporarily ignoring estimating N):
Iteration of these steps may allow bootstrapping information from different sources to jointly decode overlapping events. Ultimately, a more satisfactory approach would be to perform this feedback in a real-time tracking scenario, rather than long-term iteration. However, iteration may be a more practical way to begin. These ideas are related to and motivated by prediction-driven techniques proposed previously [4,5]. For speech sources, the "source hypothesis" might consist of word or subword-unit transcriptions. In this case, the feedback step must estimate spectral masks based on these hypothesis transcriptions. There are a wide variety of methods which could be explored to accomplish this, but the results of some preliminary methods are shown in Figure 2. This figure evaluates mask estimation by measuring the percentage of energy the mask retains from the target vs. the percentage of energy the mask discards from the interference (here, a second speaker). Mask estimates are made by comparing speaker-dependent average spectra for the phonetic label at each frame (equivalent to maximum likelihood binary classification with single, diagonal Gaussian models). The perfect mask would be in the upper-left corner. How points on this plane map to recognition accuracy will need to be determined. However, if a missing feature recognizer is used and an initial phonetic hypothesis can create a mask above the diagonal, it may be possible to "step" from the upper-right corner towards the optimal upper-left with iteration. 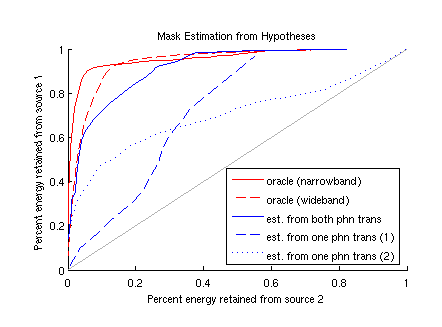 Figure 2. Comparison
of oracle masks to masks estimated from phonetic transcriptions. Oracle
masks use the original spectrograms of individual sources, while estimates
use only (known) phonetic transcriptions. Ranges swept out by varying
mask threshold from 0dB.
Recognition from masked spectrogramsThe second major step in this approach is to perform decoding given a spectral mask. Subjectively, for many mixtures, the "ideal" spectral mask can be used to produce a reconstructed waveform which is perceptually indistinguishable from the original. Therefore, one approach is to perform this reconstruction and send the isolated waveforms to a standard speech recognizer. Figure 3 shows the results of running the SUMMIT recognizer on reconstructed waveforms from oracle masks for a range of mask thresholds and at various SNRs for two-speaker mixtures and speech in speech-shaped noise. 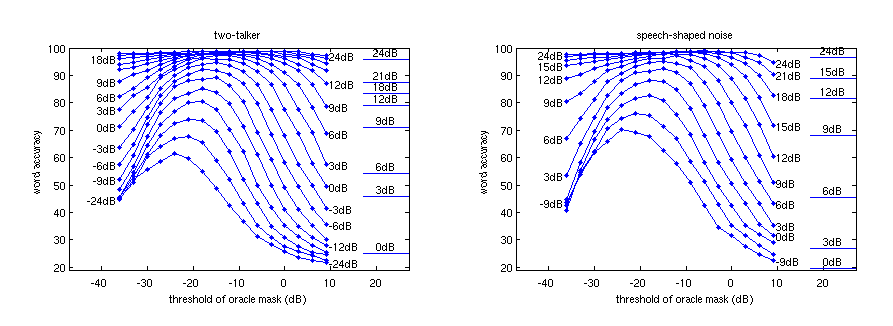 Figure 3. Recognition
results using "oracle" masks for a wide range of SNRs in two noise conditions.
Lines to the right of each plot show the baseline accuracy (no masking).
We can see there do exist masks which can achieve very high performance in adverse conditions (e.g. nearly 90% accuracy at 0 dB speech-shaped noise) for the simple vocabulary task of the GRID corpus [6]. Interestingly, the recognizer prefers masks at a considerably low masking level (-15 to -25 dB), i.e. it prefers including much more of the target signal at the expense of allowing more interference. Other results not shown here indicate that it may be possible to train a standard recognizer in such a way to expect masked inputs at some level. However, it is likely that the recently developed methods of missing-data recognition [7] would be more appropriate than relying on a standard recognizer. In particular, the method of bounded marginalization is seemingly well suited to the the problem of working with additive mixtures. Future WorkWe have only begun exploring this area of work. To proceed, a missing feature recognizer is needed, and mask estimation techniques will be further explored. It is desired to begin with a framework which could hypothetically work for an arbitrary mixture of N sources. However, in practice we will have to concentrate on specific cases and work with examples which begin with specific assumptions. The general framework proposed can incorporate any range of known information or assumptions on the sources, so we can experiment with different cases, e.g. speech plus stationary noise, two speakers, N speakers, speech plus music, speech plus a known signal, etc. References:[1] Cooke, M. P. A glimpsing model of speech perception in noise, Journal of the Acoustical Society of America, in press. 2006 [2] Miller, G.A. and Licklider, J.C.R. The intelligibility of interrupted speech, Journal of the Acoustical Society of America, 22, 167-173, 1950. [3] Wang D.L. On ideal binary mask as the computational goal of auditory scene analysis, In Divenyi P. (ed.), Speech Separation by Humans and Machines, pp. 181-197, Kluwer Academic, Norwell MA. 2005. [4] D.P.W. Ellis. Prediction-driven computational auditory scene analysis, Ph.D. thesis, Dept. of Elec. Eng & Comp. Sci., M.I.T. 1996. [5] D.P.W. Ellis. Speech recognition as a component in computational auditory scene analysis, Unpublished monograph. 1998. [6] Cooke, M. P., Barker, J., Cunningham, S. P. and Shao, X. An audio-visual corpus for speech perception and automatic speech recognition, submitted to Journal of the Acoustical Society of America, in press. 2005. [7] Cooke, M. P., Green, P. D., Josifovski, L. B., and Vizinho, A. Robust automatic speech recognition with missing and uncertain acoustic data, Speech Communication, 34, 267-285. 2001. [8] Brown G.J. and Wang D.L. An oscillatory correlation framework for computational auditory scene analysis, Proceedings of NIPS-99, pp. 747-753. 2000. |
|||
|