| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
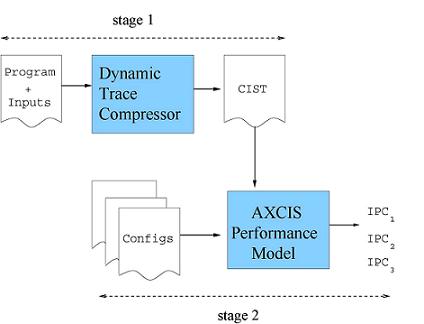
AXCIS: Accelerating Architectural Exploration using Canonical Instruction SegmentsRose Liu & Krste AsanovićIntroductionDetailed microarchitectural simulators are not well suited for exploring large design spaces due to their excessive simulation times. We introduce AXCIS (Architectural eXploration using Canonical Instruction Segments), a framework for fast and accurate design space exploration. AXCIS achieves fast simulation times by compressing a program's dynamic trace into a form that can model many different machines. AXCIS performs compression and performance modeling using a new primitive called the instruction segment to represent the context of each dynamic instruction. As shown in Figure 1, AXCIS is divided into two stages: dynamic trace compression and performance modeling.
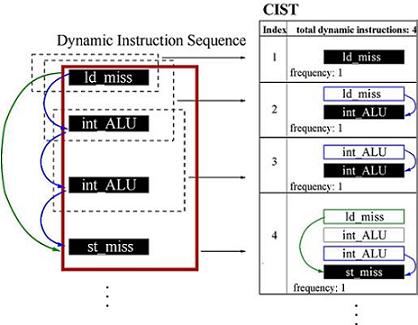
During the first stage, the Dynamic Trace Compressor (DTC) identifies all instruction segments within the dynamic trace and compresses these into a Canonical Instruction Segment Table (CIST). In order to capture locality events (ex. cache and branch behaviors) within instruction segments, partially-specified branch predictors and instruction/data caches are simulated. During this stage, only the organizations (ex. sizes, associativities) of these structures are specified and not their latencies, allowing the generated CISTs to be used for simulating multiple machines. To perform compression, the DTC compares each dynamic segment against existing CIST entries, and either increments the count of an existing entry if a match is found or adds the new segment to the CIST if not. CISTs can be adjusted to trade simulation speed for accuracy by varying the DTC compression scheme. In the second stage, the AXCIS Performance Model (APM) uses dynamic programming to quickly estimate performance in terms of instructions per cycle (IPC) for each design, given a CIST and a set of microarchitecture configurations. First, the APM calculates the total effective stall cycles of the CIST by summing the stall cycles of each segment weighted by their corresponding frequency counts. Then the APM computes IPC using the total effective stall cycles and the total instructions in the dynamic trace. This work applies AXCIS to in-order superscalar processors, although the main ideas behind AXCIS apply to out-of-order processors as well. More detailed descriptions of AXCIS can be found in [1] and [2]. Instruction Segments and CISTsEach dynamic instruction has a corresponding instruction segment, containing its dependencies, locality events, and all preceding instructions directly affecting the stalls it experiences. A segment begins with the producer associated with the instruction's longest dependency and ends with the instruction itself, termed the defining instruction of the segment. Instructions within segments are abstracted into instruction types (ex. integer ALU, LD hit). The left side of Figure 2 shows a sequence of dynamic instructions and their segments. Dependencies are represented by arrows, and the segment for the st_miss is highlighted. A CIST is an ordered array of instruction segments and their frequency counts that also records the total instructions analyzed during trace compression. The right side of Figure 2 shows the CIST corresponding to the sequence of dynamic instructions and their instruction segments.
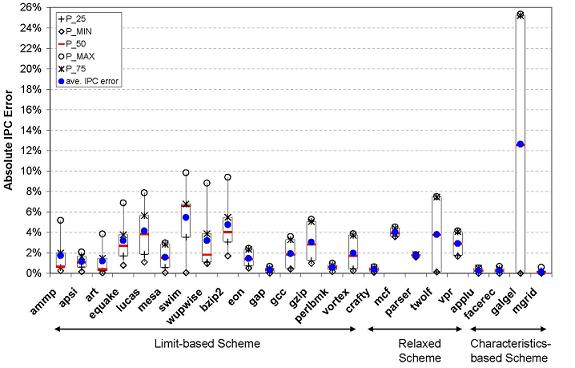
Compression SchemesBecause program behavior repeats over time, many dynamic instructions have equivalent segments that can be compressed. Two instruction segments can be compressed, without sacrificing accuracy, if their defining instructions have the same set of stall cycles (performance) under all configurations. Since it is not possible to determine the set of all possible stalls for an instruction under all configurations, we propose three different compression schemes that approximate this idea using heuristics, while making different tradeoffs between compression and accuracy. In the Limit-Configurations Based Compression Scheme, the DTC simulates two configurations (min and max) to calculate, for each instruction, a pair of stall cycles and structural occupancies (snapshots of microarchitectural state) to approximate its set of all possible stalls. Two segments are compressed if their defining instructions have the same (1) min/max stall cycles, (2) min/max structural occupancies, and (3) instruction types. In the Relaxed Limit-Configurations Based Compression Scheme, only the defining instruction types and the min/max stalls are compared for equality. Instruction segments that look the same are more likely to have the same number of stall under all configurations. Therefore, the Instruction Segment Characteristics Based Compression Scheme compares segment characteristics such as segment lengths, instruction types, locality events, and dependence distances. ResultsWe evaluated AXCIS against our baseline cycle-accurate simulator, SimInOrder, for speed and accuracy (absolute IPC error between results obtained from AXCIS and SimInOrder). We simulated a wide range of microarchitectures, differing in memory latency, issue width, number of processor functional units and primary-miss tags in the nonblocking data cache using 24 SPEC CPU2000 benchmarks [3]. Using the optimal compression scheme for each benchmark (selected from the three explored), AXCIS is highly accurate and configuration independent, achieving an average IPC error of 2.6% with an average error range of 4.4% over all benchmarks and configurations. Except for galgel with a maximum error of 25.3%, the maximum error of all benchmarks is less than 10%. Figure 3 shows the distribution of IPC error specified in quartiles for each benchmark. Using pre-generated CISTs, AXCIS is over four orders of magnitude faster than conventional detailed simulation. While cycle-accurate simulators can take many hours to simulate billions of dynamic instructions, AXCIS can complete the same simulation on the corresponding CIST within seconds.
Research SupportThis work was partly funded by the DARPA HPCS/IBM PERCS project, an NSF Graduate Fellowship, and NSF CAREER Award CCR-0093354. References[1] Rose F. Liu. AXCIS: Rapid Architectural Exploration using Canonical Instruction Segments. Master's Thesis, Massachusetts Institute of Technology, September 2005. [2] Rose F. Liu and Krste Asanović. Accelerating Architectural Exploration using Canonical Instruction Segments. In International Symposium on Performance Analysis of Systems and Software, Austin, TX, March 2006. [3] SPEC CPU2000 benchmark suite. Standard Performance Evaluation Corporation. http://www.spec.org/cpu2000/. |
||||||
|