
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Cooperative Checkpointing for Supercomputer ApplicationsAdam Oliner & Larry RudolphAbstractCooperative checkpointing increases the performance and robustness of a system by allowing checkpoints requested by applications to be dynamically skipped at runtime. A robust system must be more than merely resilient to failures; it must be adaptable and flexible in the face of new and evolving challenges. A simulation-based experimental analysis using both probabilistic and harvested failure distributions reveals that cooperative checkpointing enables an application to make progress under a wide variety of failure distributions that periodic checkpointing lacks the flexibility to handle. Cooperative checkpointing can be easily implemented on top of existing application-initiated checkpointing mechanisms and may be used to enhance other reliability techniques like QoS guarantees and fault-aware job scheduling. The simulations also support a number of theoretical predictions related to cooperative checkpointing, including the non-competitiveness of periodic checkpointing. As high-performance computing systems continue to grow in size and complexity, the robustness conferred by cooperative checkpointing will be crucial for reliably running long jobs on inherently unreliable hardware. OverviewPeriodic checkpointing, the standard method for providing reliable completion of long-running jobs, cannot cope with many realistic reliability challenges on large-scale systems; cooperative checkpointing, in which checkpoint requests may be skipped, provides greater performance and reliability by enabling flexible behavior. With cooperative checkpointing, the application programmer, the compiler, and the runtime system are all part of the decisions regarding when and how checkpoints are performed. Specifically, the programmer inserts checkpoints at locations in the code where the application state is minimal, placing them liberally wherever a checkpoint would be efficient. The compiler then removes any state which it finds to be superfluous, checks for errors, and makes various optimizations that reduce the overhead of the checkpoint. At runtime, the application requests a checkpoint. The system grants or denies the checkpoint based on various system-wide heuristics, including disk or network usage and reliability information. A key benefit of cooperative checkpointing is that checkpoints less likely to be used for recovery can be skipped, thereby improving overall performance. Standard practice is to checkpoint periodically, at an interval determined primarily by the overhead and the failure rate of the system. Although such a scheme is optimal under an exponential (memoryless) failure distribution, real systems may not exhibit such failure behavior and there is no reason to believe different systems will share reliability characteristics. Furthermore, periodic checkpointing does not scale with the growing size and complexity of systems. Cooperative checkpointing performs well under all tested failure distributions and system parameters, including those where periodic checkpointing fails. The checkpointing mechanism gives the system an opportunity to skip requested checkpoints at runtime, and thus may be considered a hybrid of application-initiated and system-initiated checkpointing. The application requests checkpoints, and the system either grants or denies each one. Without cooperative checkpointing, all application-initiated checkpoints are taken, even if system-level considerations would have revealed that some are grossly inefficient or have a low probability of being used for recovery. Cooperative checkpointing also leads to more portable code; an application instrumented with checkpoint requests can be run on machines with many different failure distributions. Therefore, cooperative checkpointing provides a robust and practical solution to system reliability challenges. These claims are verified by means of extensive simulations of large-scale systems. For example, using cooperative checkpointing in one instance reduced bounded slowdown by a factor of nine, improved system utilization, and lost no more work to failures than periodic checkpointing; this occurred even when event prediction had a 90% false negative rate. This is the first work to present cooperative checkpointing as a practical solution to system reliability, and also the first to experimentally evaluate it. 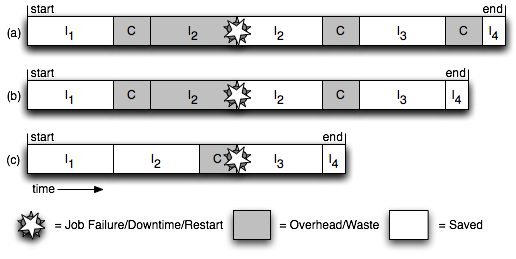
This is a picture of the job behavior with cooperative checkpointing. Tree job runs in which different checkpoints are skipped. Run (a) shows typical periodic behavior, in which every checkpoint is performed. In run (b), the final checkpoint is skipped, perhaps because the critical event predictor sees a low probability that such a checkpoint will be used for rollback, given the short time remaining in the computation. Finally, run (c) illustrates optimal behavior, in which a checkpoint is completed immediately preceding a failure. AcknowledgmentsThis word was funded in part by I.B.M. and the Singapore-MIT Alliance References:[1] A. Oliner, L. Rudolph, and R. Sahoo, Cooperative Checkpointing: A Robust Approach to Large-Scale Systems, ICS 2006 |
|||
|