
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Quantitative Information-Flow Tracking for Real SystemsStephen McCamant & Michael D. ErnstIntroductionBecause digital information can be easily copied, it can easily go astray. Information that is intended to be confidential can accidentally be transferred to subjects who should not have it, and information that should not be trusted (perhaps because it comes from an unknown party on a network) can affect the operation of critical processes. To prevent such failures, computer systems should track the provenance of the information they work with, so that it can be given the correct levels of protection and trust. We are exploring a new, more practical technique for such information-flow tracking. The key technical challenge in performing such tracking is to follow information not just as it is stored and transferred, but as it is used and modified by potentially complex calculations. For instance, in most operating systems it is up to a program to mark its outputs as confidential if necessary. However, if the program makes this determination incorrectly (perhaps because it contains a bug), the information is not protected. An alternative strategy, 'mandatory access control', makes the assumption that every output of a secret-using program must be secret. While safe, this policy makes many programs impossible to run. What is needed instead, and missing from existing systems, is a way to track information flow at a fine-grained level through the operations performed on data. Previous language-based approaches, such as type systems [1], can track information at a fine-grained level, but are not applicable to programs written in languages such as C and C++. Operating system techniques are potentially applicable to any program, but require substantial changes in system architecture [2]. ApproachOur approach to this challenge has two innovative aspects. First, the information tracking is performed on preexisting software, by tracking its operation at the instruction level. This makes the technique effective even for memory-unsafe languages such as C. Because the level of analysis exactly matches a program's actual execution, the results are both comprehensive and precise. Second, the measurement of information flow is a numeric estimate of how many bits of information could have been transferred at any point in a particular program execution. Most previous information-flow approaches use a binary notion of security: either any of amount of information might flow, or none. However, more important in practice is to distinguish between executions that reveal a limited quantity of information, versus those that reveal too much: for instance, between an execution of a password checking program that reveals whether a password is correct and one that releases the entire password database. To define the number of bits of information that a program transmits from its secret inputs to its public outputs, consider the graph representation of the program's computation as a flow network in which each intermediate value is a channel whose capacity is its size in bits. Then the number of bits that the program might leak is bounded by the maximum flow in this network. Rather than computing this maximum flow globally, however, a more efficient local approach is to annotate the boundaries between portions of the program that operate primarily on secret data and those that operate primarily on public data. The encapsulation strategy, illustrated in Figure 1, corresponds to finding a minimum cut in the flow network, and can also be used to bound the amount of information leaked by secret-dependent control-flow decisions (so-called "indirect flows"). 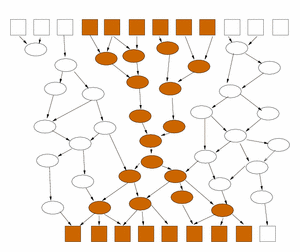 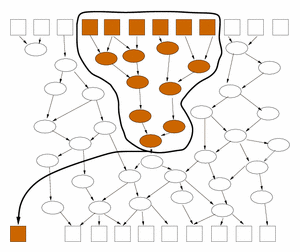
Figure 1. The propagation of secrets in a program represented as a data-flow network. Certain inputs to a program (top row boxes) are secret (shaded). Via the results of intermediate computations (ovals), the inputs affect the values of some outputs (bottom row boxes). The amount of information about the inputs that can be recovered from the outputs is bounded by the number of affected outputs. However, it can be much less if, as shown on the left, there is a flow bottleneck in the intermediate processing; this is characteristic of a secure program. To more accurately estimate the amount of information transmitted, encapsulate the first part of the processing as if it were a separate program (shown on the right), and count its results as if they were output immediately. Application exampleAs a simple "toy" example of how such information-flow tracking might be used, consider a client application for a networked version of the children's game Battleship, shown in Figure 2. Each player secretly chooses locations for four rectangular ships on a grid representing the ocean, and then they take turns firing shots at locations on the other player's board. The player is notified whether each shot is a hit or a miss, and a player wins when he or she has shot all of the squares of all of the opponent's ships. When playing the game, one would like to know how much information about the layout of one's board is revealed in the network messages to the other player. If the client program is written securely, only one bit ("hit" or "miss") should be revealed for each of the opponent's shots. 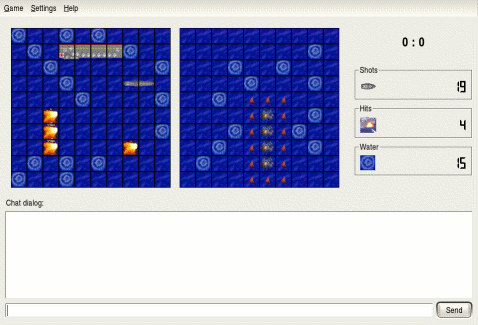
Figure 2. Version 3.3.2 of kbattleship, a program from the KDE desktop environment for playing a game of Battleship with an opponent over the Internet. Our technique can be used to verify whether each round of the game reveals only one bit of information about the secret ship locations on the player's board; in the version pictured, this security property does not hold. Our technique can be used to test this information-flow security policy about the battleship game client. The program inputs specifying the locations of the player's ships are marked as secret (for instance, by temporarily entering a mode in which all mouse inputs from the windowing system are secret), and the goal is to estimate how many bits of this information are transmitted over the network socket. The locations of the ships are stored in a relatively complex data structure (the KShipList class), but the details of its internal processing are not important, because the accesses used to generate the network reply are encapsulated in the return value of the single method shipTypeAt. If shipTypeAt returned a boolean value, indicating whether or not the grid square was occupied by a ship, our technique could then verify that this one bit was the only part of the network message that depended on the secret board data. (The message also contains the coordinates of the shot, and the entire message is encoded in XML, but the details of this downstream processing do not increase the amount of information it reveals, as in the lower half of the networks in Figure 1.) However, in the version (3.3.2) of kbattleship we have examined, shipTypeAt returns not a boolean but an integer code describing the type of ship at the queried location, and this code is passed unmodified in the network message. Though the standard client does not display this extra information, an opponent with a modified game program could use it to gain an unfair advantage, because it reveals more about the state of adjacent locations. Research SupportThis research is supported by DARPA and a National Defense Science and Engineering Graduate Fellowship. References:[1] Andrew C. Myers. JFlow: Practical mostly-static information flow control. In The Proceedings of the 26th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL 99), pp. 228–241, San Antonio, Texas, USA, January 1999. [2] Petros Efstathopoulos, Maxwell Krohn, Steve VanDeBogart, Cliff Frey, David Ziegler, Eddie Kohler, David Mazières, Frans Kaashoek, and Robert Morris. Labels and event processes in the Asbestos operating system. In The Proceedings of the 20th ACM Symposium on Operating Systems Principles (SOSP 2005), pp. 17–30, Brighton, UK, October 2005. |
|||
|