
| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Verifiable Binary Sandboxing for a CISC ArchitectureStephen McCamant & Greg Morrisett11Department of Engineering and Applied Sciences, Harvard University IntroductionA key requirement for many kinds of secure systems is to execute code from an untrusted source, while enforcing some policy to constrain the code's actions. The code might come directly from a malicious author, or it might have bugs that allow its execution to be subverted by maliciously chosen inputs. Typically, the system designer chooses some set of legal interfaces for interaction with the untrusted code, and the challenge is to ensure that the code's interaction with the rest of the system is limited to those interfaces. The most common technique for isolating untrusted code is the use of hardware virtual memory protection in the form of an operating system process, but for convenience and efficiency, most large applications, servers, and operating system kernels are constructed to run in a single address space. Another technique is to require that the untrusted code be written in a type-safe language such as Java, but this is not possible for the large amount of existing code written in unsafe languages such as C and C++. We are investigating a code isolation technique that enforces a security policy similar to an operating system, but with ahead-of-time code verification more like a type system, by rewriting the machine instructions of code after compilation to directly enforce limits on memory access and control flow. ApproachOur approach belongs to a class of techniques known as "software-based fault isolation" (SFI for short) or "sandboxing". However, previous SFI techniques were applicable only to RISC architectures [2], or their treatment of key security issues was faulty, incomplete, or never described publicly. By contrast, our technique applies to CISC architectures like the Intel IA-32 (x86), and can be separately verified so as to minimize the amount of code that must be trusted to assure security. The key challenge is that the x86 has variable-length instructions that might start at any byte; execution starting at an address that did not correspond to an intended instruction will instead execute other (usually nonsensical, but potentially dangerous) ones. To avoid this, our tool artificially enforces its own alignment constraints: it divides memory into 16-byte chunks, inserts no-op instructions as padding so that no instruction crosses a chunk boundary, and ensures that the low 4 bits of jump instruction targets are always zero (Figure 1). The technique is further optimized by treating certain registers specially, by leaving guard pages around the constrained data region, by choosing virtual locations to minimize the number of enforcement instructions required, and by giving special treatment to procedure returns. 
Figure 1. Illustration of the instruction alignment enforced by our technique. Black filled rectangles represent instructions of various lengths present in the original program. Gray outlined rectangles represent added no-op instructions. Call instructions (dark blue) go at the end of chunks, so that the corresponding return addresses are aligned. Another important aspect of the technique is that its implementation is divided into two tools, one that rewrites instructions to add checks, and a second that verifies that correct checks have been added. Only the separate verifier needs to be trusted to ensure the technique's security: in particular, the rewriting can be performed by the untrusted code producer, and the verification performed by the eventual code user. Furthermore, the verifier can be very simple; it performs no optimization, and can be implemented in a single pass over the modified code with minimal internal state. To further increase our confidence in the security of the verifier, we have constructed a formal model of the key aspects of the technique and the verification algorithm, and proved a safety result for the model using the ACL2 theorem-proving environment. ExperienceWe have implemented our technique in a prototype tool known as PittSFIeld (project home page). Though simple, PittSFIeld uses the separate verification architecture we advocate, and includes a few simple but fruitful optimizations. To test the technique's scalability and performance, we have used PittSFIeld to fault-isolate untrusted decompression modules for a storage system, and the standard SPECint2000 benchmarks. The results show PittSFIeld to be competitive in performance with other x86 tools [1], and robust enough to scale to the complexities of realistic systems. Figure 2 shows the cumulative overhead of the transformations performed by our PittSFIeld tool for the SPECint2000 benchmarks. To make later transformations easier, PittSFIeld operates on code compiled with instruction scheduling disabled (purple) and one register reserved (blue). The largest source of overhead is the additional instructions required by the technique. The figure first shows the effect of the padding instructions required to make the original code chunk-aligned (orange). The additional effect of the sandboxing instructions and the additional padding they require is added next, first with the sandboxing instructions replaced by no-ops (green) and then with the real sandboxing instructions (red). 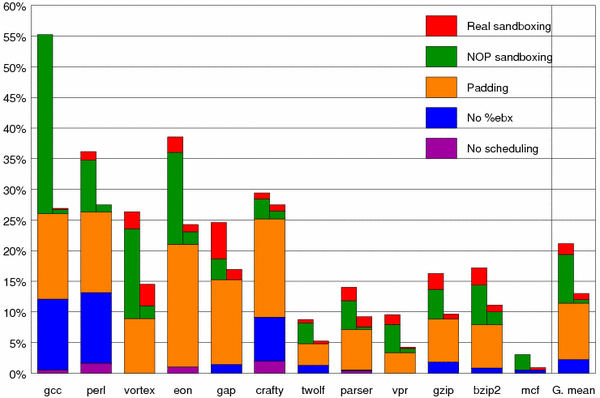
Figure 2. Run-time overhead, in percent, to protect the SPECint2000 benchmarks using PittSFIeld. Colors represent various sources of overhead, as explained above. The left half of each bar shows the overhead for protecting both writes and jumps, the right half jumps only. The programs are given in order of decreasing size. FutureThe current prototype verifier was not designed for trustworthiness; we would like to construct a more realistic one that could be carefully audited. We would like to extend the machine-checked safety proof so that it describes the remaining important optimizations of the technique, and to use an independent specification of the processor's behavior. More ambitiously, we would be interested in exploring generating a verifier and a machine-checked safety proof from a single specification. Finally, we would like to apply the technique to additional security-critical system components, such as device drivers or libraries used by in network-accessible servers. Research SupportThis research is supported in part by a National Defense Science and Engineering Graduate Fellowship. References:[1] Martín Abadi, Mihai Budiu, Úlfar Erlingsson, and Jay Ligatti. Control-Flow Integrity: Principles, Implementations, and Applications. In ACM Conference on Computer and Communication Security (CCS), Alexandria, Virginia, USA, November, 2005. [2] Robert Wahbe, Steven Lucco, Thomas E. Anderson, and Susan L. Graham. Efficient Software-Based Fault Isolation. In Proceedings of the 14th Symposium on Operating Systems Principles, pp. 203-216, Asheville, North Carolina, USA, December 1993. |
|||
|