| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Hidden Conditional Random Fields for Gesture RecognitionSy Bor Wang, Ariadna Quattoni, Louis-Phillppe Morency, David Demirdjian & Trevor Darrell
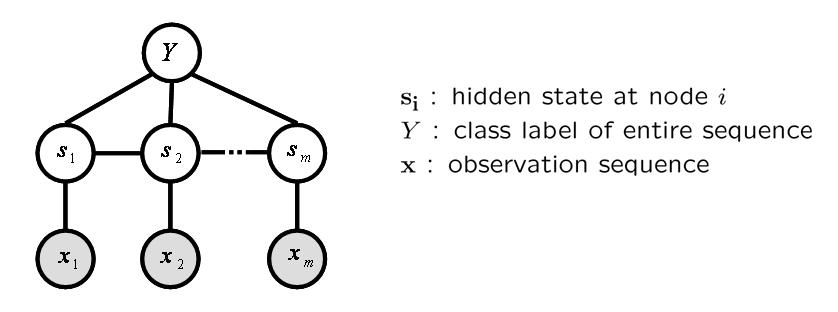
ProblemGesture sequences often have a complex underlying structure, and models that can incorporate hidden structure have proven in the past to be advantageous. Most existing approaches to gesture recognition with hidden state employ a Hidden Markov Model or suitable variant (e.g., a factored or coupled state model) to model gesture streams; a significant limitation of these models is the requirement of conditional independence of observations. In addition, hidden states in a generative model are selected to maximize the likelihood of generating all examples of a given gesture class, which is not necessarily optimal for discriminating the gesture class against other gestures. Previous discriminative approaches to gesture sequence recognition have shown promising results, but have not incorporated hidden state and have not addressed the problem of predicting the label of an entire sequence. ApproachWe propose a new model for gesture recognition which incorporates hidden state variables in a discriminative random field model. Our approach combines gesture class conditional Condtional Random Fields(CRFs)[1] into a unified framework for gesture recognition. The parameters of the CRF are estimated in a maximum likelihood framework and recognition proceeds by finding the most likely gesture label while integrating over hidden state. By allowing a classification model with hidden state, no a-priori segmentation into substructures is needed, and labels at individual observations are optimally combined to form a class conditional estimate. Our hidden state conditional random field (HCRF)[2] model can be used either as a gesture class detector, where a single class is discriminatively trained against all other gestures, or as a multi-way gesture classifier, where discriminative models for multiple gestures are simultaneously trained. The latter approach has the potential to share useful hidden state structure across the different classification tasks, allowing higher recognition rates.
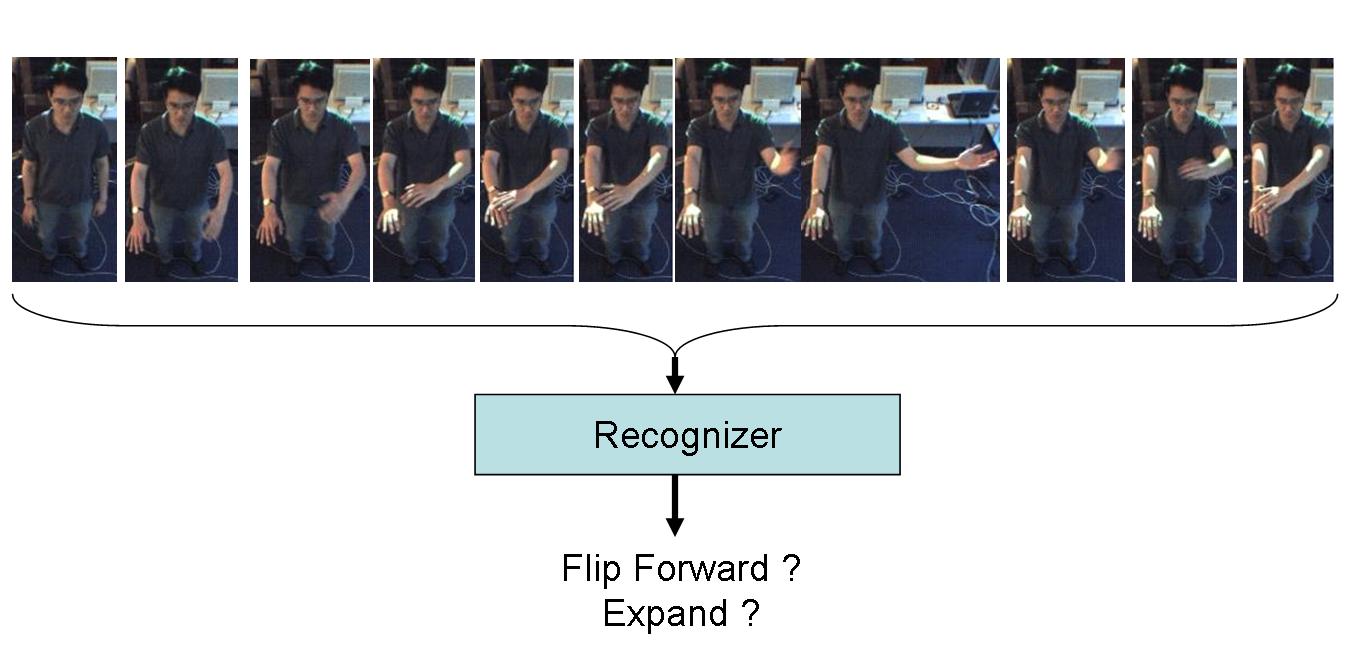
DatasetsArm Gesture Dataset We defined six arm gestures for the experiments. The six gestures are illustrated below
From each image frame, a 3D cylindrical body model consisting of a head, torso, arms and forearms was fitted. This model is estimated using a stereo-tracking algorithm and setup similar to [3]. Below is a figure showing a gesture sequence articulated in front of a stereo camera, with the estimated body model superimposed on the user.
We used the joint angles and relative co-ordinates as features for gesture recognition. Head Gesture Dataset For head gesture recognition, pose tracking was performed using an adaptive view-based appearance model which captured the user-specific appearance under different poses[4]. Three classes of head gestures, namely nods, shakes and junk were collected. We used 3D angular velocities as features for gesture recognition. ExperimentsWe used the features mentioned in the datasets section for training in the following models: HMM Models - a HMM model per class. Each model had four states and used a single Gaussian observation model. We ran several experiments varying the states from two to eight and also the number of Gaussians per mixture, our results showed that four states and a single Gaussian per state produced the optimal performance in the testing dataset. We chose the parameters that perform optimally on the test set because we want to compare our models against the best performing HMM. During evaluation, test sequences are passed through each of these models, and the model with the highest likelihood is selected as the recognized gesture. CRF Model - As a second baseline, we trained a single CRF chain model where every gesture class has a corresponding state. This CRF models each frame in a sequence, not the sequence per se. During evaluation, we find the Viterbi path under the CRF model, and assign the sequence label based on the most frequently occurring gesture label per frame. HCRF (multiclass) Model - We trained a single HCRF using twelve hidden states. (We conducted several experiments, varying the model with hidden states ranging from eight to fifteen and the model with twelve hidden states generated the lowest error on the training set). The test sequences were passed through this model and the gesture class with the highest probability was selected as the recognized gesture. HCRF (one-vs-all) Model - For each gesture class, we trained a seperate HCRF model to discriminate that gesture from the other classes. Each HCRF was trained using 6 hidden states (We tried models with five, six and seven states and the model with six hidden states produced the best results in the training set). For a given test sequence, we compared the probabilties for each single HCRF, and the highest scoring HCRF model is selected as the recognized gesture. Results
The table above summarizes the results for the head gesture experiments. We notice that the HCRF model performs slightly worse than the HMM model. However, when we incorporated one futrue observation and one previous observation to a single feature, the HCRF performs significantly better than all the other models(64.4%). For this data the extra modeling power of HCRFs (i.e. the ability to incorporate longer range dependencies) yields a substantial improvement. The CRF performed poorly for the head gesture task. This may not be surprising, since CRFs are really modeling labels per frame rather than explicitly forming the conditional probability of the sequence label.
The table above summarizes results for the arm gesture recognition experiments. In these experiments the CRFs perform better than HMMs, indicating that a discriminative approach is more appropriate for this task. Both multiclass and one-vs-all HCRFs perform better than HMMs and CRFs. The most significant improvement in performance is obtained when we use a multi-class HCRF, suggesting that it is important to learn the best discriminative structure jointly. ++ Research SupportThis research was carried out in the Vision Interface Group, which is supported in part by DARPA, Project Oxygen, NTT, Ford, CMI, and ITRI. This project was supported by one or more of these sponsors, and/or by external fellowships. References:[1] J. Lafferty, A. McCallum and F. Pereira. condtional random fields:probabilistic models for segmenting and labelling sequence data In ICML,2001 [2] A. Quattoni, M. Collins and T. Darrell. Conditional Random Fields for object recognition. A tutorial on hidden markov models and selected applications in speech recognition. In NIPS,2004 [3] D. Demirdjian and T. Darrell. 3-D articulated pose tracking for untethered deictic reference. In Int'l Conf. on Multimodal Interfaces, 2002. [4] L.-P. Morency, A. Rahimi and T. Darrell. Adaptive view-based appearance model. In CVPR, 2003. |
|||||||||||||||||||||||
|