| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
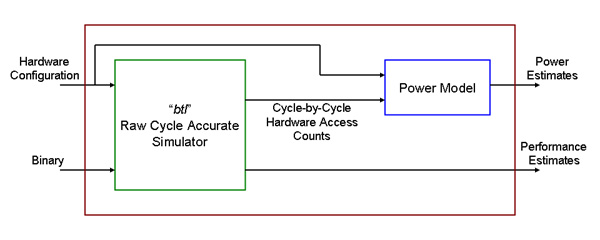
Power Performance of Tiled Processor ArchitecturesT. Konstantakopoulos, I. Bratt, J. Psota, W. Lee & A. AgarwalIntroductionTiled architectures have been proposed as a way to allow the performance of high-performance microprocessors to scale along with processor designers' exponentially-increasing transistor budgets. Modern superscalar processors with large out-of-order instruction issue widths, register renaming units, multi-level caches, and other performance-targeting features have begun to yield diminishing returns on performance. Additionally, such structures typically consume a tremendous amount of power, giving rise to today's power-hungry commercial processors. Architectures that attempt to break up these structures into smaller, more localized ones seem to be a viable way of alleviating both the performance and power scaling issues. Taylor et al. [1] demonstrated that the long wire delay caused by these large centralized structures is effectively mitigated by a tiled architecture. Tiled processor architectures reduce power by breaking up computation into multiple independent tasks, which can potentially decrease power consumption without sacrificing performance. Furthermore, intelligent compilers exploit data locality, allowing computation to be scheduled and positioned in a way that communication costs are low, thereby reducing overall power. Besides it is predicted that both power and wire constraints will drive processors to explicitly parallel modular architectures. TileWattchWe would like to justify our claim by comparing power and energy measurements of Raw [2], a tiled architecture, and a baseline superscalar processor. We are building TileWattch, a tiled processor architecture power simulator, based on Wattch [3], a superscalar power simulator tied to SimpleScalar [4]. Fig. 1 shows the overall structure of our tiled processor architecture simulator, TileWattch. Our power models use technology parameters from the IBM SA-27E process. This is a 1.8V, 0.18um, 6-level Cu ASIC process. "btl", the Raw cycle accurate simulator, feeds our power models with events, whenever there is access to any of the hardware functional units on each tile. The events include: ALU accesses (integer and floating point), register file accesses, instruction and data cache accesses, and accesses on the four on-chip networks of Raw (2 static and 2 dynamic). The power and energy numbers from all of the functional unit accesses, as well as the leakage and clock power and energy, is reported for every tile to construct a general Raw chip power and energy report. TileWattch OutputThis is a typical TileWattch output. In this example we run vpenta on a 16 tile Raw configuration. The vpenta benchmark is from the Spec92 NASA benchmark suite. This kernel simultaneously inverts three pentadiagonal matrices. The frequency of operation was 425MHz and the supply voltage was 1.8V. Per Tile Report This is the output of TileWattch regarding the total energy of one of
the tiles.
Full Chip Report This is the output of TileWattch regarding the total energy of all the tiles. These numbers are just a summation of the respective hardware functional units, on each of the active tiles (16 in this case). Total Cycles: 1000562 Frequency: 425MHz Vdd: 1.8 Full Chip Energy **************************************
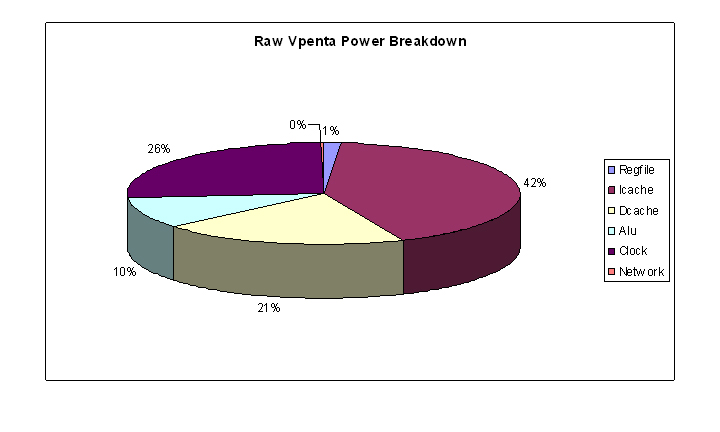
Based on these results Fig. 2 shows the average power breakdown for vpenta References:[1] M. Taylor and A. Agarwal. Evaluation of the Raw Microprocessor. An Exposed-Wire-Delay Architecture for ILP and Streams. In The Proceedings of the International Symposium on Computer Architecture, pp. 2--13, Munich, Germany, June 2004. [2] M. Taylor and A. Agarwal. The Raw Microprocessor. A Computational Fabric for Software Circuits and General Purpose Programs. In IEEE Micro, Mar/Apr 2002. [3] D. Brooks and M. Martonosi. Wattch: A Framework for Architectural-Level Power Analysis and Optimizations. In The Proceedings of the International Symposium on Computer Architecture, pp. 83--94, Vancouver, British Columbia, Canada, June 2000. [4] D. Burger and T. M. Austin. The SimpleScalar Tool Set, Version 2.0. In Computer Architecture News, pp. 13--25, June 1997. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|